
为什么 batch size 都是2的幂数?
你有没有疑惑过,为啥batch size都是2的幂数?
有人觉得是「习惯」,也有人说这算是一种约定俗成的标准,因为从「计算」的角度来看,batch size为2的幂数有助于提高训练效率。

但计算机科学就是一门实践的学科,理论再完美也需要实验结果来验证。
最近一位AI研究者Sebastian动手试了一下所有的batch size,结果发现其对性能的影响微乎其微,甚至在某些情况下,不使用2的幂数训练速度更快!

实验结果一出,也得到大量网友的响应。
有网友认为,使用2的幂数单纯是出于审美上的愉悦,但我并不觉得有什么区别。有时候为了体验「游走于刀尖上」的感觉,我就用10的倍数。
也有网友认为batch size的设置存在玄学,他有时候还会用7的倍数。

更叛逆的网友表示,我用2的幂数,但是幂数带「小数」
不过也有正经点的讨论,认为作者做的基准测试可能是精度不够的,比如batch size选择512和539的区别可能根本测量不出来。

也有人表达反对意见,我们「不是必须」选择2的幂数,但我们「应该」这样做。
首先这个基准测试毫无意义,在一个超级小数据集上使用一个超小网络进行实验,我们无法从这样的玩具数据中获得任何现实世界的指标。
其次,在TPU上选择batch size为8的倍数太大了,数据将被填充,并且会浪费大量的计算。
我认为即使在GPU上,padding也会有影响,可能会留下潜在的性能改进空间。

理论基础
理论基础
在看实践基准结果之前,我们简单回顾一下选择batch size为2的幂的主要思路。
内存对齐(Memory Alignment)
选择batch size为 2 的幂的主要论据之一是 CPU 和 GPU 内存架构是以 2 的幂进行组织的。或者更准确地说,存在内存页的概念,它本质上是一个连续的内存块。
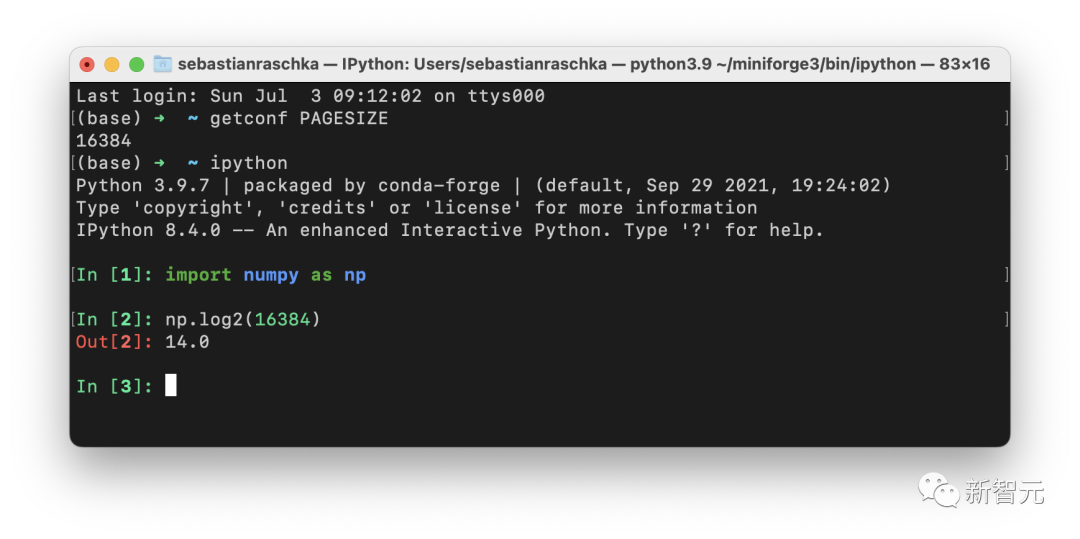
如果你使用的是 macOS 或 Linux,就可以通过在终端中执行 getconf PAGESIZE 来检查页面大小,它应该会返回一个 2 的幂的数字。
其目的是将一个或多个batch整齐地放在一个Page上,以帮助在GPU中进行并行处理,所以batch size大小为2的幂数可以帮助获得更好的内存排列。这与在视频游戏开发和图形设计中使用OpenGL和DirectX时选择2次方纹理相类似。
矩阵乘法和Tensor Core
英伟达有一个矩阵乘法背景用户指南,解释了矩阵维度和GPU的计算效率之间的关系。
文章中建议不要选择矩阵尺寸为2的幂,而是选择矩阵尺寸为8的倍数,以便在带有Tensor Core的GPU上进行混合精度训练。当然,这两者之间是有重叠的,比如8, 16, 32等。

为什么会是 8 的倍数?这与矩阵乘法有关。
假设我们在矩阵 A 和 B 之间有以下矩阵乘法:
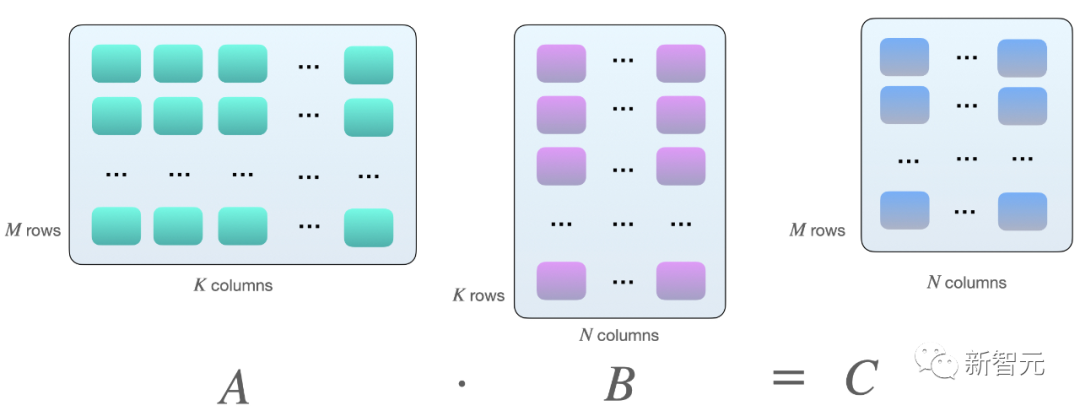
计算两个矩阵 A 和 B 相乘的一种方法是计算矩阵 A 的行向量和矩阵 B 的列向量之间的点积(dot product)。
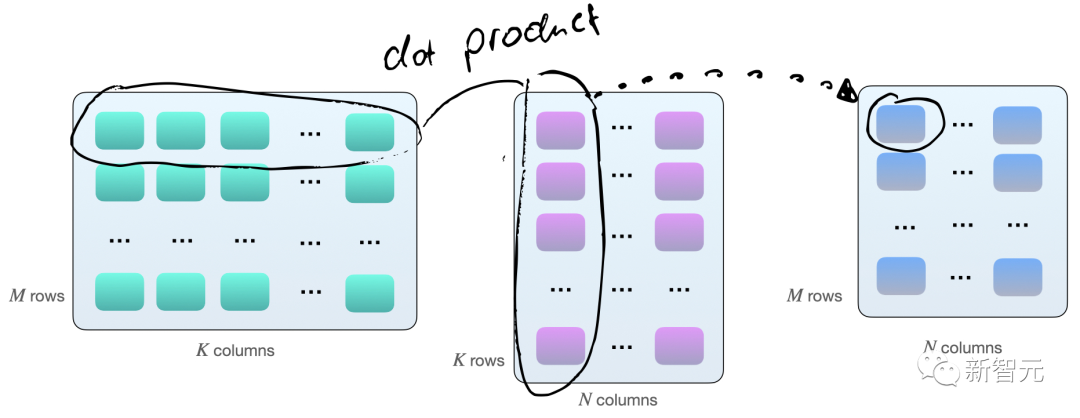
每个点积由一个「加法」和一个「乘法」操作组成,需要得到 M×N 个这样的点积,因此共有 2×M×N×K 次浮点运算(FLOPS)。
不过现在矩阵在 GPU 上的乘法并不完全如此,GPU 上的矩阵乘法还包括tiling
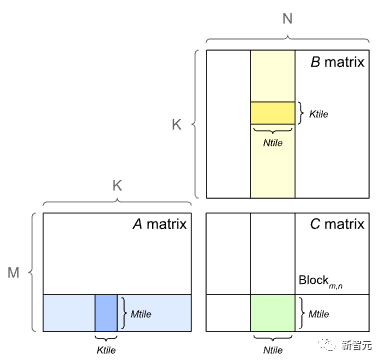
如果使用带有 Tensor Cores 的 GPU,例如英伟达 V100,当矩阵维度 (M、N 和 K)与 16 字节的倍数对齐后,在 FP16 混合精度训练的情况下,8 的倍数对于计算效率来说是最佳的。
通常维度 K 和 N 由神经网络架构决定,但batch size(此处为 M)通常是由开发者控制的。
因此,假设batch size为 8 的倍数在理论上对于具有 Tensor Core 和 FP16 混合精度训练的 GPU 来说是最有效的,不过实际提升效果有多少,还需要做过实验才知道。
简单的Benchmark
简单的Benchmark
为了了解不同的batch size对实际训练的影响,作者在CIFAR-10上运行了一个简单的基准训练MobileNetV3(large)的10个epoch,图像被调整为224×224以达到适当的GPU利用率。
在V100卡上运行了16位原生自动混合精度训练,这样可以更有效地利用GPU的Tensor Cores。
代码链接:https://github.com/rasbt/b3-basic-batchsize-benchmark
小batch size
从batch size为128的小基准开始,Train Time对应于在 CIFAR-10 上训练 MobileNetV3 的 10 个 epoch,Inference Time为在测试集中的 10k 图像上评估模型。
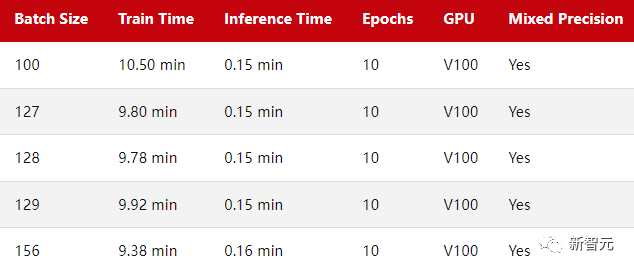
如果把batch size为128作为基准点,减少一个批处理量(127)或增加一个批处理量(129)确实会导致训练性能稍慢。然而,这里的差异几乎不明显,我认为它可以忽略不计。
将批处理量减少28(即100)会导致更明显的性能减慢。这可能是因为模型现在需要处理比以前更多的批次(50,000/100=500 vs. 50,000/100=390)。
可能由于类似的原因,当我们将批次大小增加28(156)时,我们可以观察到训练时间更短了。
最大的batch size
鉴于 MobileNetV3 架构和输入图像大小,128可能太小了,因此 GPU 利用率约为 70%。
为了研究 GPU 满负荷时的训练时间差异,作者将batch size增加到 512,以使 GPU 显示出接近 100% 的计算利用率。
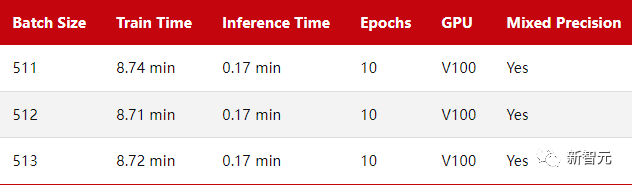
由于 GPU 内存限制,batch size值无法超过 515。
同样,正如我们之前看到的,作为 2 的幂(或 8 的倍数)的批大小确实会产生很小但几乎不明显的差异。
多GPU训练
前两个基准测试评估了在单个GPU上的训练性能,转到多GPU上结果是否会有不同?
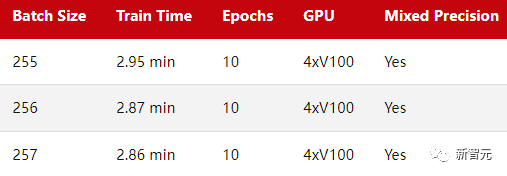
可以看到,这一次,2次方和8次方的批处理规模(256)并不比257快。
本处使用DistributedDataParallel(DDP)作为默认的多GPU训练策略。
注意事项
这里需要强调的是上述所有基准测试都有注意事项。例如只运行每个配置一次。理想情况下可能希望多次重复这些运行并报告平均值和标准偏差。
但最终结论可能都是一样的:即性能没有实质性差异。
此外,虽然实验是在同一台机器上运行了所有基准测试,但是以连续的顺序运行测试,运行之间没有很长的等待时间。也就是说GPU的温度在运行时可能有所不同,并且可能会对计时产生轻微影响。
资源和讨论
Ross Wightman 曾提到,他也不认为选择batch size为 2 的幂会产生明显的差异,但选择 8 的倍数对于某些矩阵维度可能很重要。
此外 Wightman 指出,在使用 TPU 时batch size至关重要,不过作者表示他无法轻松地访问到 TPU,所以也就没做基准测试。
Rémi Coulom-Kayufu 曾经做过一个实验表明,2 次方的batch size实际上并非最佳选择。
对于卷积神经网络,可以通过以下方式计算出较好的值
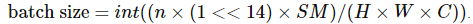
其中,n 是整数,SM 是 GPU 内核的数量(例如,V100 为 80,RTX 2080 Ti 为 68)。
结论
结论
基于本文分享的基准结果,我不相信选择batch size规模为2的幂或8的倍数在实践中会有明显的区别。
然而,在任何特定的项目中,不管是研究基准还是机器学习的实际应用,选择2次方(即64、128、256、512、1024等)可以会更加直接和易于管理。
另外,如果你对发表学术研究论文感兴趣,将你的批次大小选择为2的幂,会使你的结果看起来不那么像「调参出来的」。
虽然坚持使用2次方的batch size可以帮助限制超参数搜索空间,但必须强调批量大小仍然是一个超参数。
有些人认为,较小的batch size有助于泛化性能,而另一些人则建议尽可能地增加批次大小。
就我个人而言,我发现最佳batch size高度依赖于神经网络架构和损失函数。例如,在最近一个使用相同ResNet架构的研究项目中,我发现最佳批次大小可以在16到256之间,完全取决于损失函数。
因此,我建议始终考虑将调整batch size作为你的超参数优化搜索的一部分。
如果由于内存的限制,你不能使用512的batch size,你也不必降到256,选择500也是完全可以的。
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》