【拓展】谈谈字符编码:Unicode编码与emoji表情编码
共 6830字,需浏览 14分钟
·
2020-08-15 21:12
“开发过程中,字符编码是我们一定要掌握的知识。本文回顾ASCII标准,并介绍了Unicode和UTF-8、UTF-16方案间的关系,各自是如何存储的,最后介绍了Unicode中emoji表情的构成规则。
介绍字符编码前,先要明确概念:
码位(码点),对应编码术语中英文中的code point,指的是一个编码标准中为某个字符设定的数值,具有唯一性与一一对应性。码位只规定了一个字符对应的数值,并没有规定这个数值如何存储,视编码方案不同有不同的存储方式。
像ASCII这样的简单编码方式,其码位值就是存储时字符实际上存储的值,因此不需要特别强调这个概念。但后面我们会看到,Unicode编码中每个码位的值会对应许多中不同的存储方案,不同的码位用几个字节存储也会有变化。所以需要理解码位和字符的一一对应关系,知道这个码位值不受存储方案的干扰。
code unit,可以翻译成编码单元。搜集资料并没有找到一个权威的官方定义。根据我的理解,code unit指的是某个编码方案存储方式中最小有意义的单元。例如,UTF-8中最少一个字节存储一个字符,那么code unit就是8位大小。UTF-16中最少两个字节存储一个字符,那么code unit就是16位大小。类似,UTF-32中的code unit是32位大小。从中可以看出,UTF-后面的数字指的就是该方案下code unit的bit位数。
ASCII标准与其扩展编码方案概述
谈到编码就不得不提到。ASCII码是我们学习计算机时一定会接触到的第一个编码标准,相信大家很熟悉。简单总结一下ASCII码的特点。
(1)一个字符就用一个字节表示,而且限制字节的最高位必须为0,使得总共只能表示2^7=128个不同字符。
(2)存在许多没有字形的字符,如0x00-0x20码位均属于此类字符。如格式控制符回车换行、以及计算机网络中提到的EOF、SOH等等。
(3)是按照美国人的习惯制定的,不能表示除英文字符外的其他众多字符。 这就导致其他国家用将每个自己字节最高位改成1的方式将ASCII编码扩展。扩展后多出来的128个码位用于添加自己国家的的语言文字。也有如苏联的国家将ASCII码中的`$`美元符号替换成了其他货币符号。 在这种情况下,同一个码位在不同编码标准中有不同的含义,导致各国的编码标准无法兼容。
在大陆国内历史上用于拓展ASCII的方案则是GB(国标)系列编码方案,该编码方案历史悠久,详细叙述比较复杂。由于Windows命令行对中文默认的就是使用GB2312,平时我们也会接触到使用GB系列编码的字符串,所以我们要大致了解其基本特征。
(1)兼容ASCII编码方案。原有的ASCII字符对应的码位不变,也是使用一个字节来存储。
(2)除拓展的生僻字外,大部分汉字采用双字节编码。也就是说GB系列编码存储也采用的是变长存储方案。一旦谈到变长存储,就涉及到字符的定界问题。计算机需要知道到底哪几个字节属于同一个字符的表示。 GB系列方案中,规定每个汉字存储时的第一个字节第一位用1开头,和ASCII码做区分。这样只要某个码位值大于127,就固定表示这是一个汉字的开始。从GBK编码之后不要求第二个字节的首位以1开头,不过处理时只要前面的那个字节最高位是1,就能识别这个字节是前面字节的延续,从而解决定界问题。
Unicode概述
如上所述,各国的编码之间大部分在ASCII码范围可以兼容,但扩展后的字符集就不兼容了。因此诞生了Unicode标准以实现一个各国都能统一的字符集。
不过需要注意的是,Unicode标准的想法仅仅是为每个字符规定一个码位。不包括具体的存储方案。不像GB系列方案规定到每个字节在存储时最高位必须为1这么详细,这个标准仅仅给字符分配了码位而已。
在阅读介绍Unicode的其他资料时,需要理解Unicode方案为每个字符制定的码位的表示方式及规则。
一般Unicode的码位表示成U+XXXXXX 的形式,X 代表一个十六制数字,表示形式的范围在 4-6 位之间,也就是U+0000 ~ U+10FFFF间。当码位值不足 4 位时前面补 0 补足 4 位,超过则按是几位就是几位。
至于为什么上限是10FFFF,和目前的码位划分方式有关。为了方便码位的管理,便于码位的分配,Unicode将编码空间均分成 17 个 65536 大小的分区,每个分区称为**平面(plane)。**共存在65536*17=1114112个码位,换算成16进制从0开始算起就是U+10FFFF了。
其中,第零平面,也就是U+0000~U+FFFF的码位叫做基本多语言平面,简称BMP(Basic Multilingual Plane)。我们平常的使用的大部分语言文字,包括除生僻字以外的汉字码位都规定在这个平面中。其余平面叫做补充平面(Supplementary Planes)。
注意,BMP里存在一种特殊区域: 代理区(Surrogate)。Unicode标准规定U+D800 - U+DFFF的值不对应于任何字符。后面可以看到,UTF-16就巧妙地利用了这一段空白区域进行了编码的转换。
如前面所述,由于Unicode 只是给每个字符规定了一个码位,是连续分配的,而没有考虑到一些其他的冲突问题,即前面说过的字符定界的问题。码位值越大,需要完整表示使用的二进制位数越多,假如直接把码位值转换成二进制存储,在 Unicode 中往后的字符可能就需要 3 个字节甚至4个字节来表示了。这就导致定界问题,如何确定到底用几个字节来表示一个字符呢?这是Unicode标准没有指明的。涉及到具体存储光看Unicode编码无法解决问题,如何存储还需要另外的方案。
容易想到,最简单的做法是让所有的字符类型都用四个字节定长存储,计算机在读取时统一读取四个字节作为一个码位来理解,这样就解决了定界问题。UTF-32采用的是这种方案,这样解决了编码问题,但是却造成了空间的极大浪费。大部分常用字符位于BMP内,本来两个字节就能存储,却统一变成了四个字节来存储,使得存储空间浪费了很多。
因此,目前采用广泛的Unicode编码存储方案都是变长的存储方案,如UTF-8和UTF-16。
UTF-8
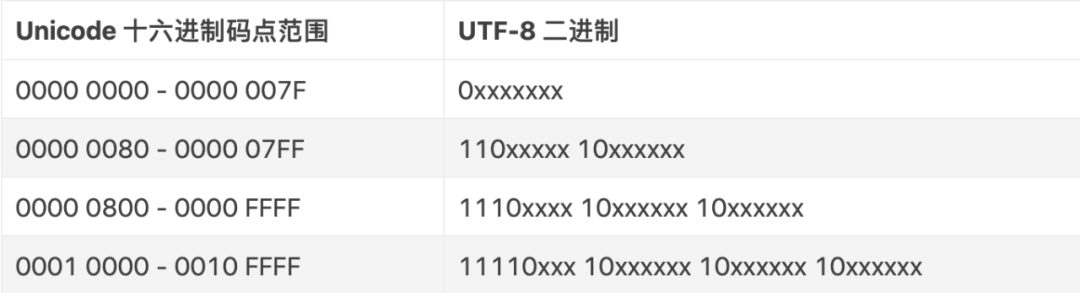
UTF-8的实现方案其实非常简单,上面这张表就可以看懂。特性总结为:
(1)与ASCII码兼容。也就是对于ASCII字符按照原有的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码位。这样用 ASCII 码编码的文档用 UTF-8 编码打开不会出现问题。
(2)除了ASCII以外,其他码位需要用多个字节表示。对于这种类型的字符,第一个字节的前面使用110~1110几个不同的前缀来标识,而后面的字节则以10开头,表示这个字节是前面的延续。这种方式使计算机看到了第一个字节就能知道后面是还有几个字节属于同一个字符,也能在看到以10开头的字节就知道这个字节不是一个字符的开始。
根据上表实现unicode到UTF-8的转换也比较简单,知道unicode编码后查表找到其对应UTF-8编码的范围,从这个范围开头往后寻找其位置即可。有兴趣的同学可以自己尝试。
使用UTF-8编码时,大部分汉字转换后需要用三字节存储。
UTF-16
UTF-16实现方案则介于UTF-8和UTF-32之间。对最常用的基本平面中字符的存储空间进行了压缩,使得汉字只需要两个字节就可以存储。
由于基本平面的码位值从U+0000-U+FFFF,刚好用 2 个字节就可以存放,所以UTF-16规定基本平面中的字符占用2个字节,辅助平面的字符占用 4 个字节。UTF-16 的编码长度要么是 2 个字节,要么是 4 个字节。
那么UTF-16又是怎么解决字符存储的时不同字符的边界问题的呢?
前面提到,在基本平面内,从 U+D800 到 U+DFFF 的码位是代理区,不对应任何字符。因此,UTF-16就用了这一段区域巧妙地解决了边界问题。
UTF-16将代理区进一步划分成两部分。0xD800~0xDBFF,称为高半代理(leading surrogate)。0xDC00~0xDFFF分区, 称为低半代理(trailing surrogate)。
不难得到,高半代理范围含有0xDBFF-0xD800+1=0x0400=2^10个码位,低半代理范围也有0x0400=2^10个码位。
除去基本平面已经分配存储方案的码位后,辅助平面还剩下0x10FFFF-0x010000+1 = 0x0F0000,约为2^20个码位。这些码位还需要分配存储方案。假如将这些码位值全部存储成二进制数,需要至少20位来存储,至少也需要四个字节。
UTF-16的做法是,将这四个字节的前两个字节映射到高半代理表示的范围,后两个字节映射到低半代理的范围。高半代理和低半代理总共能表示2^10*2^10=2^20个数,刚好能为每个辅助平面还剩下的2^20个码位分配存储方案。
这样,按两个字节两个字节读取的方式判别,假如读到的值不在代理区内,就证明这就是一个BMP内的字符。假如读到的值位于前导代理范围内,证明这是一个四字节辅助字符的开头,后面两个字节是这个字符的延续。假如读到的值位于后导代理范围内,证明前面两个字节也属于这个辅助字符的一部分。
这样就解决了字符定界问题。
有了具体的存储方案,unicode在制定标准时就只需要为字符分配抽象的码位了,具体的存储由采用UTF-8还是UTF-16方案来定,极大方便了编码的制定。
因此,下面讨论emoji表情编码时不需要讨论其存储方案,只需要讨论其逻辑层次上的Unicode编码。
emoji表情的unicode编码
emoji表情大家应该也比较熟悉了。像常用的??用语就是emoji表情组成的。我们再来谈谈在unicode对于emoji表情的编码。这里也要注意,Unicode只是规定了 emoji 的码位和含义,以及用文字指导它们代表的表情长什么样,并没有规定它的具体样式。渲染的工作则由各个系统自己实现。如果用户的系统没有实现某个emoji表情的渲染,就会显示成一个空方框。
在MAC中,输入ctrl + cmd + 空格后在弹出的面板里添加unicode代码表就可以看见每个unicode码位对应的字符了。其中可以非常方便地查询到字符对应到编码值。如下图所示。
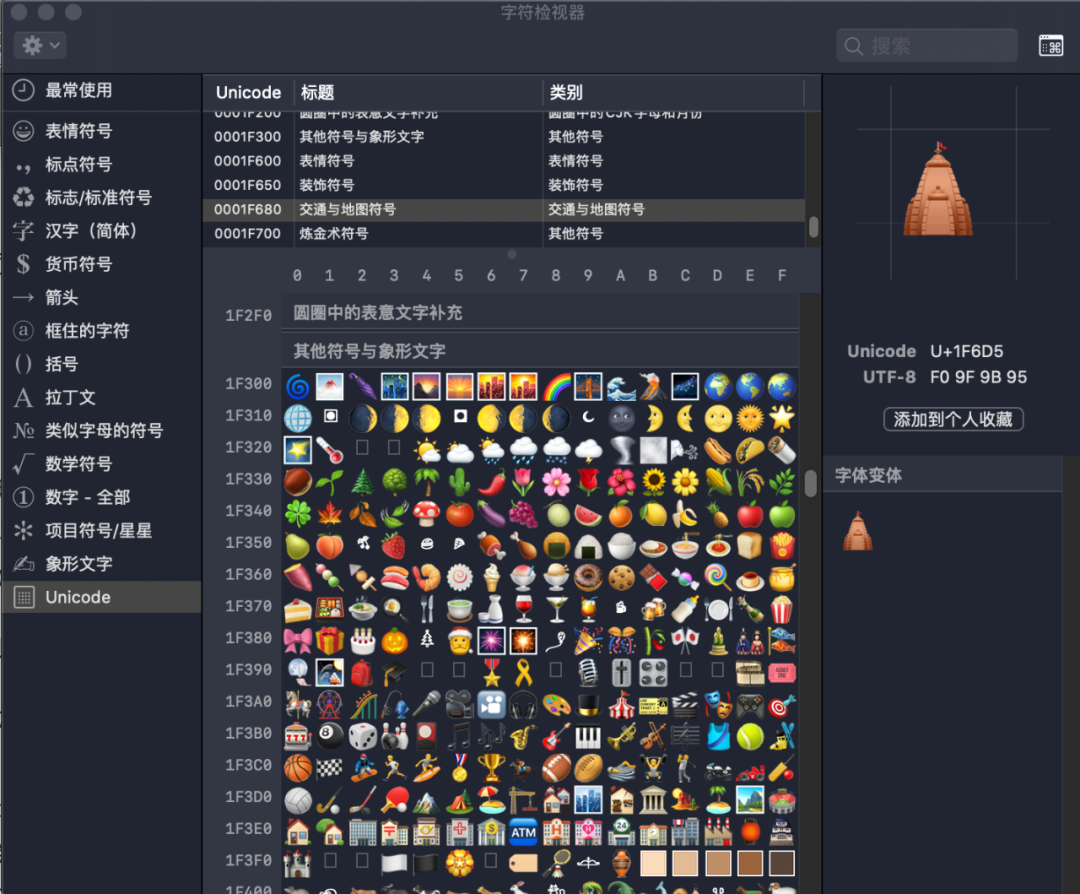
从U+1F300开始,存放的这些小表情就是emoji表情。
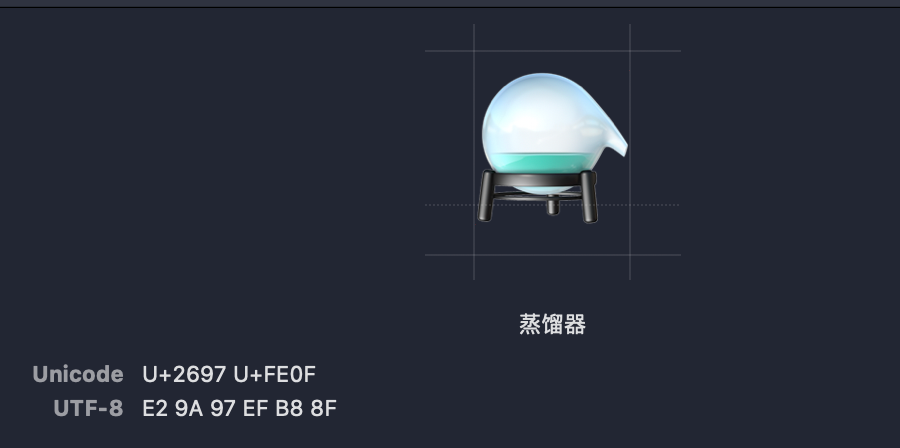
可以发现简单的笑脸对应的是Unicode的一个码位,但一个蒸馏器对应了两个码位,一个金发男子表情竟然对应了五个码位。我们看到,一个emoji表情也是变长存储的,而且一个表情可占用多个码位组成。那么这些表情的渲染又有什么规则呢?

️
要解答这个问题,需要阅读unicode官方介绍emoji表情的文档。
https://www.unicode.org/reports/tr51/#Emoji_Properties_and_Data_Files
关于emoji表情涉及到许多定义,见其中1.4节。其中有这样的定义
text_presentation_selector := \x{FE0E}U+FE0E的含义是,一个text_presentation_selector,大概意思是文本表示选择符。
text_presentation_sequence := emoji_character text_presentation_selector这个定义表明,加上了这个U+FE0E修饰的emoji字符会构成一个文本表示序列。所以,这个text_presentation_selectorU+FE0E是用来修饰前面的emoji表情,指定其展示方式的。
不过笔者使用的macbook对这种文本表示emoji的表情还没有支持,使用上面的输入法添加U+FE0E选择符后并没有成功渲染出emoji的文本表示形态。
类似的,还存在定义
emoji_presentation_selector := \x{FE0F}emoji_presentation_sequence := emoji_character emoji_presentation_selector加上了U+FE0F修饰的emoji字符会构成一个emoji表示序列。
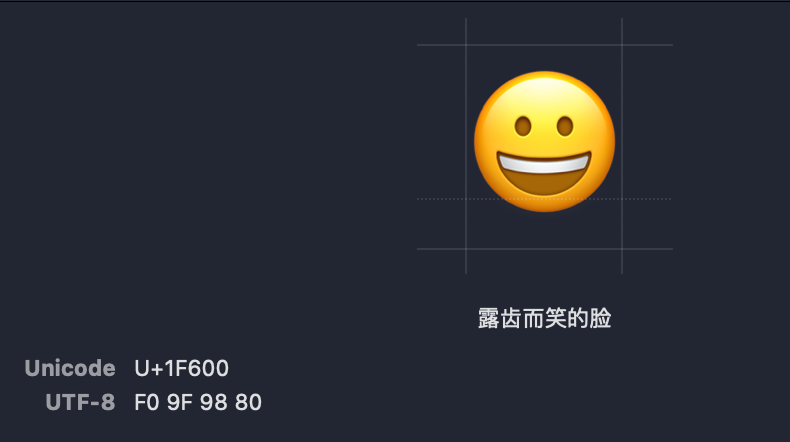
例如这个蒸馏器表情就是由U+FE0F修饰U+2697产生的,可以利用刚才提到的mac自带输入法尝试一下。
输入查找Unicode编码U+2697输出得到⚗这个小蒸馏器符号
假如在输入法中搜索U+FE0F找到

再连在前面输入的U+2697⚗符号后面后面输入这个修饰符就得到了⚗️这个emoji表情。
由此,我们理解了U+FE0F的作用,相当于一个修饰符,在渲染文字时如果遇到了U+FE0F就和前面的字符组合一下,改成渲染成一个emoji表情的形式。这样就可以理解上面的蒸馏器为什么占用了二个Unicode码位了。本身这个表情就是由其他字符加上修饰符组合而成的。
此外, 还有另一些比较有趣的定义。
emoji_modifier := \p{Emoji_Modifier}emoji_modifier_base := \p{Emoji_Modifier_Base}emoji_modifier_sequence := emoji_modifier_base emoji_modifier
意思是,一个作为base的表情加上一个modifier修饰符后会构成一个emoji修饰符序列。有些表情会具有base属性,有些则具有modifer属性。下面来看个例子。
在输入法中找到U+1F471号字符,单独输出。
?
再找到U+1F3FF号字符,单独输出

这次再将两个表情连在一起输出,结果变成了一个

类似还有其他的组合规则,如国旗,键盘等都有各自的组合规则,也是用具有不同属性的unicode字符组合而成。详情可翻阅文档查阅。
另外,介绍Emoji表情编码还不得不提到一个特殊字符ZWJ,全程zero-width joiner,意思是零宽度连字符,占用码位U+200D。这个字符不是为emoji单独服务的。用于插入在某些语言的字符中,使左右的两个字符连在一起产生连字效果,合成单个人类可读的字符。
具体到emoji表情中,某些单个显示表情也会由多个独立的ZWJ连字合成得到。
举例
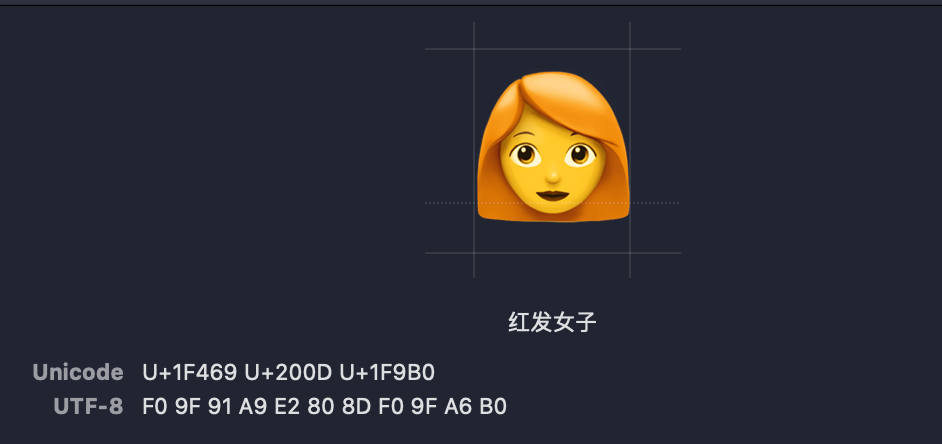
可以看到,这个红发女子就是由U+1F469和U+1F9B0使用U+200D连字得到的。下面我们来输入看看这两个字符分别代表什么。
U+1F469
?
U+1F9B0

这表明,U+1F469代表的是一个女子,而U+1F9B0单个表情代表的是头发的颜色,利用U+200D组合到一起,就得到了红发女子这个表情。
有了这些组合方式的基础,再回头看前面的金发黑人男子就不难理解为什么它由那么多Unicode字符组成了。本质也是通过前面所述的三种表示规则组成得到的。大家可以用输入法每个字符依次自行输入一遍金发黑人男子表情,就能理解其合成的方式。
总结与展望
限于时间与篇幅,本文仅仅回顾ASCII标准,并介绍了Unicode和UTF-8、UTF-16方案间的关系,各自是如何存储的,最后介绍了Unicode中emoji表情的构成规则。
掌握这些编码的通用基础知识,是后续学习各语言各平台对字符串处理规则的基础。每个语言存储字符串时采用UTF-8还是UTF-16都会有所不同,视每个语言、每个编译器的具体实现而定。
特别是对于emoji表情,由于其组成规则复杂,可能是由多个Unicode字符组合而成的。所以在处理含有emoij表情的字符串时,使用索引、统计长度和其他字符串比较运算都需要一些算法支持。iOS开发使用Swift语言时,emoji表情能作为单个的字符进行索引,特性强大,但同时也因此造成了Swift语言的字符串使用起来并不方便。
后续的文章会逐步介绍Swift语言对字符串的实现机制,研读swift是如何处理含义emoji表情的字符串。

回复“加群”与大佬们一起交流学习~