
微服务流控防护场景与应对措施
共 1887字,需浏览 4分钟
·
2021-03-27 04:05
前言
微服务成了互联网架构的标配模式,对微服务之间的调用的流量治理和管控就尤为重要。哪些场景需要流量防控,针对这些场景又有哪些应对措施。有没有一个通用的措施来降低风险呢?这篇文章咱就聊聊这个。
一、服务被过载调用
当服务D的某个接口服务被上游服务过载调用时,如果不对服务D加入保护,可能整体将服务D整体拖垮。在这种场景中,我们需要对服务D配置限流,以保护服务D不被整体冲跨。
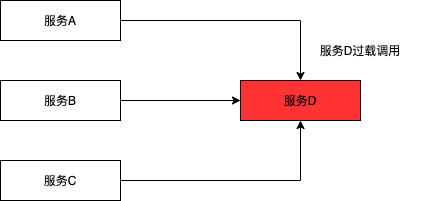
应对措施: 针对服务提供方D配置流量防护规则,对进入服务D的流量进行控制,从而对服务D提供保护。触发流控时可以有多重策略,例如:快速失败、预热模式、排队等待、预热模式+排队等待。
快速失败: 发生流控时直接抛出异常。
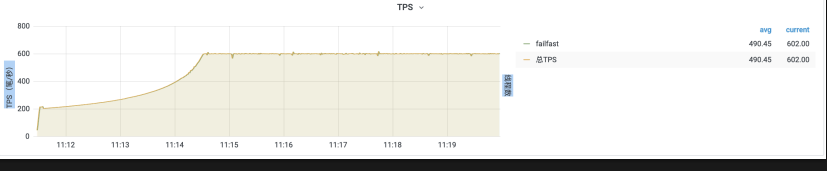
预热模式: 发生流控时,流量缓慢增加的一种模式,效果如下图所示,流量QPS从200缓慢增加到600。
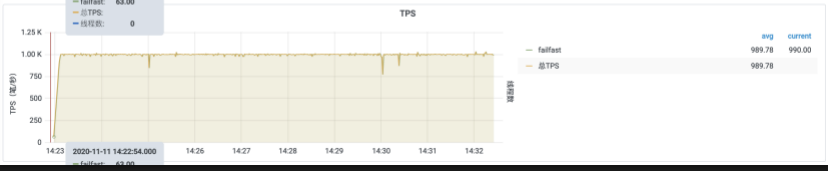
排队等待: 请求匀速通过,过多请求需要排队,此时排队有超时时间,超过排队时间抛出流控异常。效果如下图所示:请求QPS保持1000的匀速通过。
预热模式+排队等待: 这种模式是预热和排队等待的叠加模式,请求以匀速的方式缓慢增加。如下图:请求从0缓慢增加到500,匀速通过一段时间后,再增加到1000。

二、服务慢调用或故障
下面的场景A调用B、A调用C、A调用D,当服务B服务不稳定时,服务A调用服务B发生了慢调用或者大量异常错误。这种场景,如果不干预,可能影响到A调用C和A调用D的状况。
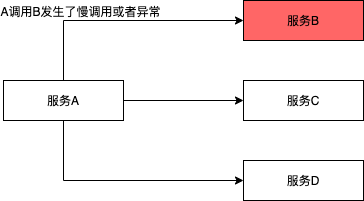
应对措施: A调用B配置熔断降级规则,当服务B不稳定发生慢调用或者异常时,如果触发阈值,将服务B的调用熔断;从而保护了服务A调用C、服务A调用D的正常情况。
熔断效果: 熔断的实现通常通过断路器实现,具体过程为:
当满足慢调用比例、异常比例、异常数量阈值后,触发熔断(OPEN),在熔断时长内拒绝所有请求
当熔断过了定义的熔断时长,状态由熔断(OPEN)变为探测(HALF_OPEN)
接下来的一个请求不发生慢调用或者异常,熔断结束由探测状态(HALF_OPEN)变为(CLOSED)
接下来的一个请求发生慢调用或者异常,继续熔断,由探测状态(HALF_OPEN)变为(OPEN)
三、服务资源被挤占
分布式链路中,如果某一条链路产生慢调用,对其他链路造成挤压。除了上面提到配置熔断降级外,可以通过线程并发控制来隔离。
下图中有3条链路,其中链路1由于服务E的不稳定,产生了慢调用。

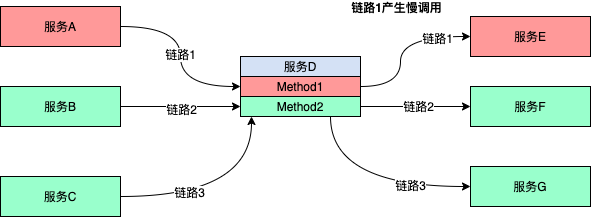
链路1慢调用可能导致如下情况:
链路1线程数增多对服务D资源造成挤压
对服务D资源的过度挤压,链路2和链路3造成不稳定
极端情况导致整个服务D不可用,严重时引发雪崩
应对措施: 通过对服务D的MethodA1、MethodA2的线程数并发设置规则,超过阈值时将会触发阻断,不再向下游调用,避免不可用引发雪崩。
并发控制效果 下图中设置了调用方的并发线程数为10,通过每分钟的查询可以看出,线程数一直保持在10。
四、数据过热挤占资源
热点数据,比如:大促时的热销产品、秒杀类产品等。如下图所示,如果不对热点商品下单流量进行管控,可能对其他商品造成挤压;影响整个商品下单体验。

应对措施: 通过对热点参数测速,配置流控规则,超过阈值时触发流控。例如:通过对入参产品ID进行测速,超过设置的阈值时,触发流控,避免对其过度挤占资源。
五、通用防护分组措施
上面的现象中,无论是服务不稳定、还是被挤占、或者被过载调用。除了通过上述的防护措施外,可以对服务进行等级划分并分组。
如下图所示:服务A和服务D为核心服务、服务B和服务C为非核心服务。通过将服务D进行分组,分成了1组和2组。分组1只允许核心服务调用,分组2只允许非核心服务调用。
这样做的好处:将流量进行物理隔离,避免由于非核心业务流量对核心业务流量造成挤压、保护核心链路稳定性。
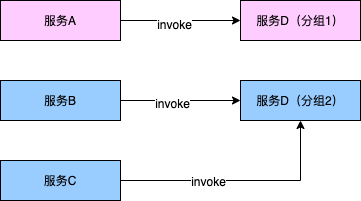
分组措施@1 通常可以更换注册中心路径实现,服务A和服务D(分组1)放在同一个注册中心路径(例如:soa-group1);服务B、服务C、服务D(分组2)放在另一个不同的注册中心路径(例如:soa-group2)。
分组措施@2 通过对分组的服务节点打标实现,例如:服务D(分组1)节点被打标为group1,服务D(分组2)节点被打标为group2。在服务消费方订阅节点时根据不同的分组筛选节点调用。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️