
深度学习多目标优化的多个loss应该如何权衡
共 7211字,需浏览 15分钟
·
2021-05-08 13:08
转载自 | 深度学习与计算机视觉
作者 | 马东什么
链接 | https://zhuanlan.zhihu.com/p/362330594
对于多任务学习(多目标优化)而言,它们每一组loss之间的数量级和学习难度并不一样,寻找平衡点是个很难的事情。文章从工程角度对该类问题进行了系统的解答。

MTL中的一个重大挑战源于优化过程本身。特别是,我们需要仔细平衡所有任务的联合训练过程,以避免一个或多个任务在网络权值中具有主导影响的情况。极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势。
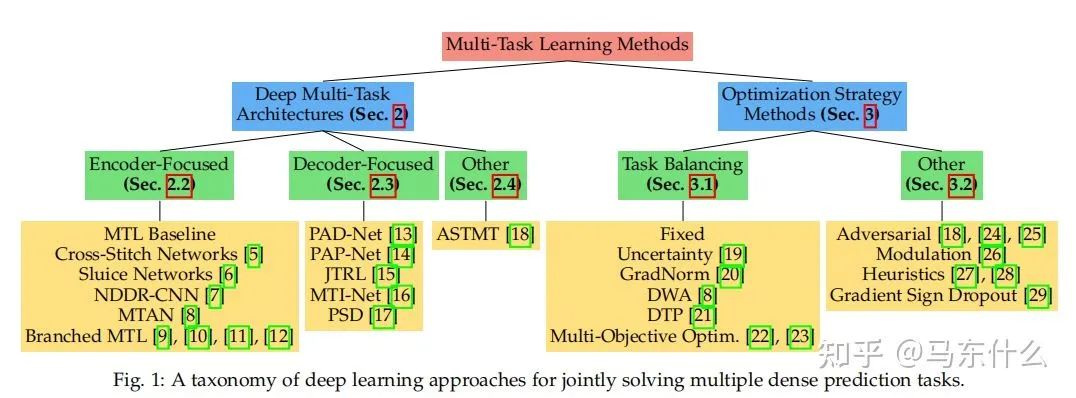
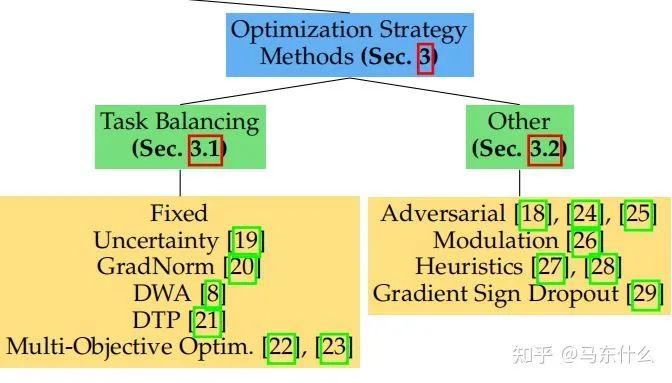
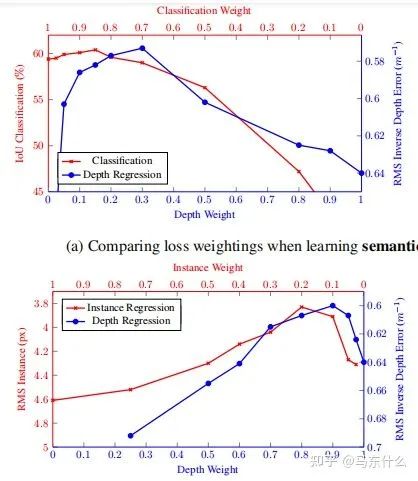
第一大类方法 Task Balancing Approaches
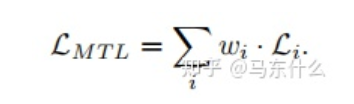
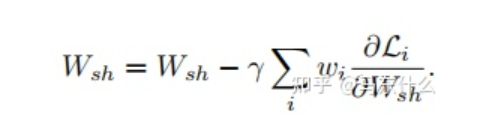
所以,后续的方法大体分为两类:
另外,tensorflow-probability在google上有关于这本书完整的代码demo,非常浅显易懂,上手快。
另外也有torch版的pyro
CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers:https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
from
我们初高中学物理的时候,老师肯定提过偶然误差这个词。我们做小车下落测量重力加速度常数的时候,每次获得的值都会有一个上下起伏。这是我们因为气流扰动,测量精度不够等原因所造成的,是无法被避免的一类误差。在深度学习中,我们把这种误差叫做偶然不确定性。
从深度学习的角度来举例子,我们举一个大家应该很比较熟悉的人脸关键点回归问题[3]:
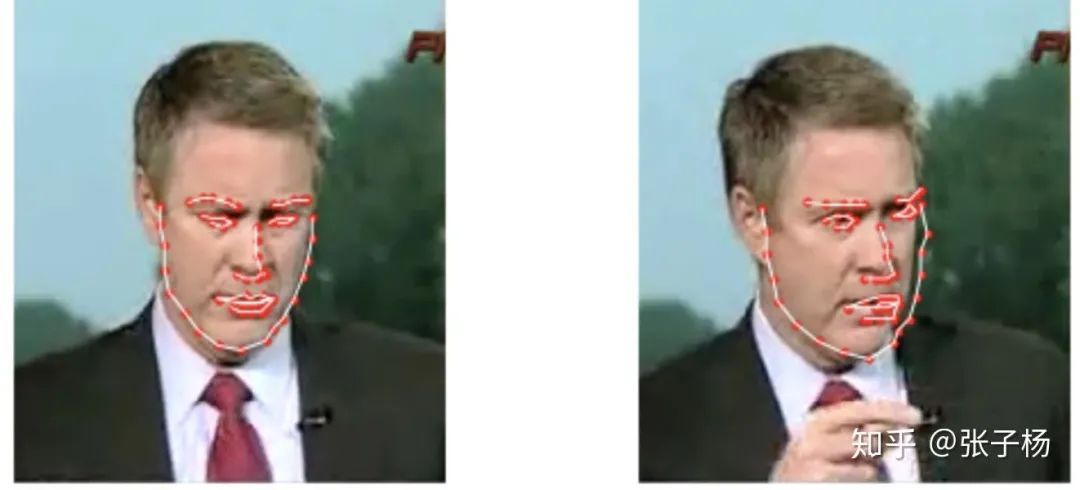
我们可以看到,对于很相似的一组数据,dataset的标注出现了比较大的误差(见右图的右侧边缘)。这样的误差并不是我们模型带入的,而是数据本来就存在误差。数据集里这样的bias越大,我们的偶然不确定性就应该越大。
2.认知不确定性
认知不确定性是我们模型中存在的不确定性。就拿我们文章一开始举的例子来说,假设我们训练一个分类人脸和猩猩脸的模型,训练中没有做任何的增强,也就是说没有做数据集的旋转,模糊等操作。如果我给模型一个正常的人脸,或者是正常猩猩的脸,我们的模型应该对他所产生的结果的置信度很高。但是如果我给他猫的照片,一个模糊处理过得人脸,或者旋转90°的猩猩脸,模型的置信度应该会特别低。换句话说,认知不确定性测量的,是我们的input data是否存在于已经见过的数据的分布之中。
认知不确定性可以通过增加更多的data来缓解,偶然不确定性则需要对数据进行统一标准的处理。
偶然不确定性又存在两种不确定性类别:
什么是异方差?为什么异方差的出现通常与模型中某个解释变量的变化有关?https://www.zhihu.com/question/354637231/answer/895286217
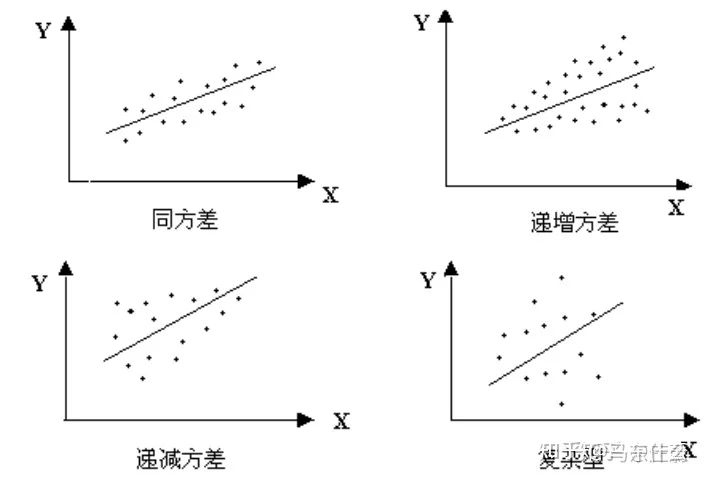
2、任务依赖性(同方差不确定性)是不依赖于输入数据的任意不确定性,它与模型输出无关,是一个在所有输入数据保持不变的情况下,在不同任务之间变化的量,因此,它可以被描述为与任务相关的不确定性,但是作者并没有详细解释在多任务深度学习中的同方差不确定性的严格定义,而是认为同方差不确定性是由于任务相关的权重引起的。
下面我们定义fW(x)为nn的预测值,也就是我们熟悉的y_pred,
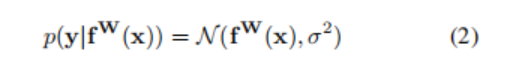
其中  在代码中的体现,是一个可学习的参数,我们用这个参数服从的公式2的高斯分布作为同方差不确定性的衡量方法,即以 y_pred为均值向量,**2 作为方差的多元高斯分布;
在代码中的体现,是一个可学习的参数,我们用这个参数服从的公式2的高斯分布作为同方差不确定性的衡量方法,即以 y_pred为均值向量,**2 作为方差的多元高斯分布;

则在多目标的前提下,我们认为总的同方差不确定性可以用不同任务的不确定性的乘积来表示:
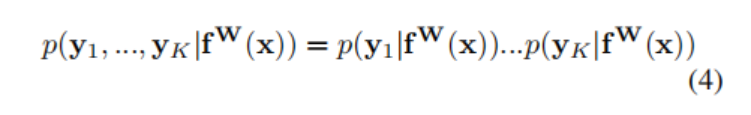
通过对公式(4)进行对数变换后可以得到:
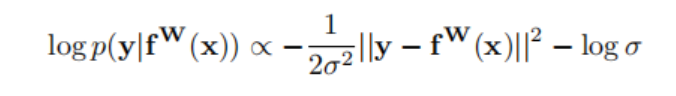
现在让我们假设我们的模型输出由两个向量y1和y2组成,每个向量都遵循一个高斯分布:
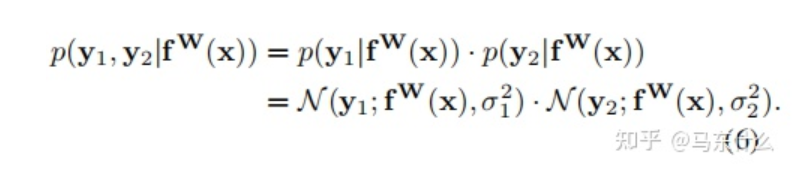
然后得到多输出模型的最小化目标函数 L(W、σ1、σ2):
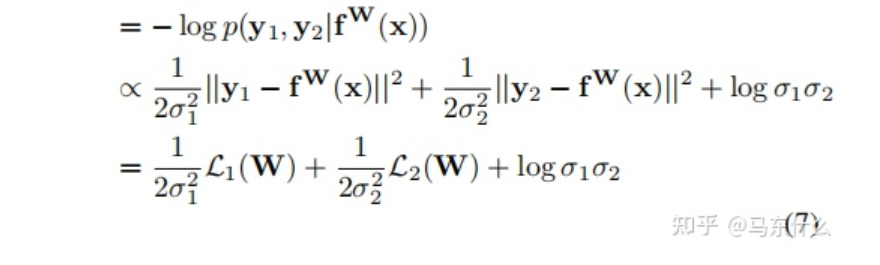
对于分类型任务,作者木有给出最终的化简公式,不过对照下面的一个分类型任务+一个回归型任务的化简公式:

我们可以先推出单个回归型任务的不确定性度量公式,从而得到分类型任务的同方差不确定性的近似衡量公式为:
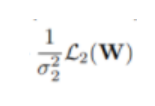
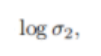
这种构造可以简单地扩展到任意离散和连续损失函数的组合,允许我们以一种有原则和有充分根据的方式学习每一个损失的相对权重。这种损失是平滑可微的,并且分布形状很好,使得任务权重不会收敛到零。相比之下,使用直接学习权值会导致快速收敛到零的权值。
总结一下,整体的思路就是用sigma来衡量同方差不确定性,同方差不确定性和任务有关,同方差不确定性越高的任务则意味着模任务相关的输出的噪声越多,任务越难以学习,因此在多任务模型训练的过程中,其对应的sigma会增大,削弱这类任务的权重使得整体的多任务模型的训练更加顺畅和有效。
在代码实现上有个小问题,也是比较常见的实现和论文存在区别的地方:https://github.com/yaringal/multi-task-learning-example/blob/master/multi-task-learning-example-pytorch.ipynb
这个是原论文作者的实现:基于两个回归型任务,损失函数mse为前提下得到的
def criterion(y_pred, y_true, log_vars):
loss = 0
for i in range(len(y_pred)):
precision = torch.exp(-log_vars[i])
diff = (y_pred[i]-y_true[i])**2. ## mse loss function
loss += torch.sum(precision * diff + log_vars[i], -1)
return torch.mean(loss)

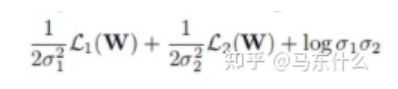
首先我们定义 log(sigma)=a(a是一个可学习的变量),则 torch.exp(-a)=torch.exp(-log(sigma))=torch.exp(log(sigma**-1))=1/sigma(这里0.5可以省去也可以包含进来,因为我们定义1/2*变量x和直接定义变量x,在梯度下降法求解的过程中没有太大区别,然后是常数项的部分,作者在原文中提到,后面的常数项并不是很重要,放进来作为一种正则乘法太大的sigma(方差),这里后面的常数项,按照代码的意思,是直接用了sigma方差来代替了标准差,其实差别也不大)
所以根据上述的设定对下面的代码做了一些修改:
找了几个实现,发现代码都有问题,只有这个git是完全忠于原文的,并且封装的也比较舒服。
import torch
import torch.nn as nn
class AutomaticWeightedLoss(nn.Module):
"""automatically weighted multi-task loss
Params:
num: int,the number of loss
x: multi-task loss
Examples:
loss1=1
loss2=2
awl = AutomaticWeightedLoss(2)
loss_sum = awl(loss1, loss2)
"""
def __init__(self, num=2):
super(AutomaticWeightedLoss, self).__init__()
params = torch.ones(num, requires_grad=True)
self.params = torch.nn.Parameter(params) #parameters的封装使得变量可以容易访问到
def forward(self, *x):
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += 0.5 * torch.exp(-log_vars[i]) * loss + self.params[i]
# +1避免了log 0的问题 log sigma部分对于整体loss的影响不大
return loss_sum
关于权重项部分

适配的话:
from torch import optim
from AutomaticWeightedLoss import AutomaticWeightedLoss
model = Model()
awl = AutomaticWeightedLoss(2) # we have 2 losses
loss_1 = ...
loss_2 = ...
# learnable parameters
optimizer = optim.Adam([
{'params': model.parameters()},
{'params': awl.parameters(), 'weight_decay': 0}
])
for i in range(epoch):
for data, label1, label2 in data_loader:
# forward
pred1, pred2 = Model(data)
# calculate losses
loss1 = loss_1(pred1, label1)
loss2 = loss_2(pred2, label2)
# weigh losses
loss_sum = awl(loss1, loss2)
# backward
optimizer.zero_grad()
loss_sum.backward()
optimizer.step()
2、如果在多任务学习中,我们主要是希望主任务的效果好,辅助任务的效果可能不是很care,那么如果恰好主任务是同方差不确定性最高的,则使用这种方法可能会削弱主任务的效果,这是最大的问题,因为这种处理的方式针对的是整个多任务模型的总体loss来设计的,无法满足对特定任务的不同程度的需求,因为作者原始的思路是不确定性越高的任务越应该削弱权重,但是反过来想,不确定性越高的任务越难,如果我们反而让模型重点去学习这个任务,是否可以提高模型的能力;
3、 这里没有考虑权重和为1的问题,不过我觉得作者本来也没打算这么做,影响不大,权重之和是否为1并不是问题其实,本来多任务也不一定需要权重为1的设定,另外权重简单做归一化就可以得到权重为1了。。
4、实际应用的一个问题,权重可能会变成负数,导致我们最终的loss变成负数了。。。也就是部分任务对于最终总loss的贡献是负贡献,我认为可能是这部分任务的不确定性太大使得模型训练困难,这个部分我们torch.relu进行截断就可以了
1、模型训练的效率低,最终运行时间由最复杂的任务决定;
2、复杂任务收敛的过程中,简单任务的局部最优权重可能会变差。
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!