
突发!美国又“出手”了!
大家好,我是 Jack。
今天继续聊聊互联网上发生的那些事,又是聊技术、聊“八卦”的一天~
一、美国升级对华芯片出口限制
去年 10 月,美国升级了对华半导体出口管制,以 Nvidia A100 芯片的性能指标作为限制标准,限制对华出口高性能计算芯片。
时隔一年,10 月 17 日,美国再次“出手”,计划继续升级出口限制,据悉 Nvidia A800 和 H800 芯片也将无法出口给中国。

10 月 16 日晚,美国商务部长 Gina Raimondo 曾告诉记者,新政策的目的在于修正去年 10 月发布的法规,未来可能会进行“至少每年一次”的更新。
此外,美国商务部还于 10 月 17 日将壁仞科技、摩尔线程等多家中国 GPU 芯片企业列入了受限实体清单。
具体包括:北京壁仞科技开发有限公司、广州壁仞集成电路有限公司、杭州壁仞科技开发有限公司、光线云(杭州)科技有限公司、摩尔线程智能科技(北京)有限责任公司、摩尔线程智能科技(成都)有限责任公司、摩尔线程智能科技(上海)有限责任公司、上海壁仞信息科技有限公司、上海壁仞集成电路有限公司、上海壁仞科技股份有限公司、超燃半导体(南京)有限公司、苏州芯延半导体科技有限公司、珠海壁仞集成电路有限公司。

二、国美 APP 骂创始人
最近有一则消息,当用户打开国美APP上的“幸运大转盘”抽奖页面时,弹出的文案包含了对国美电器董事长黄秀虹和创始人黄光裕的侮辱性言辞,指控其拖欠工资、拖欠货款,“早晚得再进去蹲几年”。
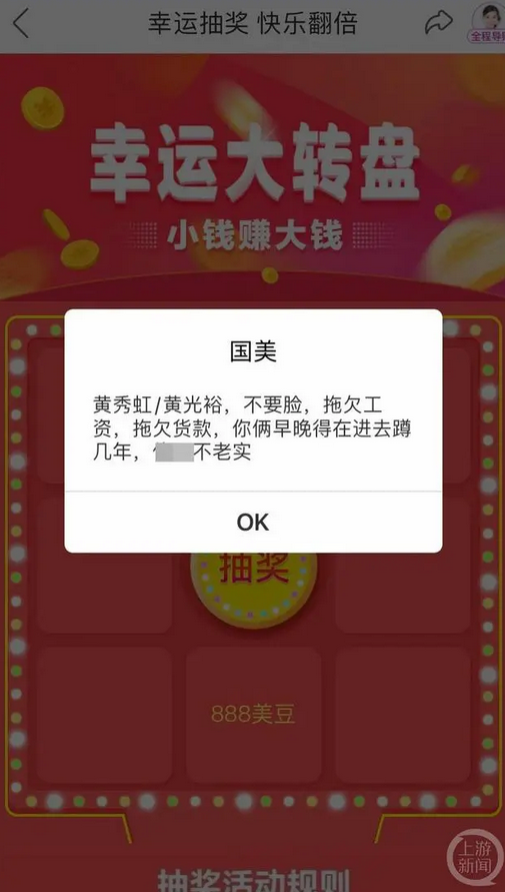
据说,国美从去年 10 月份就开始拖欠薪资了 。
网友们调侃:这是程序员的愤怒和呐喊。
不过这个“锅”程序员可不背,毕竟一个运营活动上线,要经过策划、产品、研发的通力合作,还要有测试、运营的验收。
只能说整条产品线的人,都或多或少参与其中,这也实属被逼无奈之举吧。
当然,这种做法并不理智,虽然此举会引发社会对于国美欠薪问题的关注,但自己也会受到惩罚。
碰到欠薪行为的公司,明智一些的做法是:及时止损,赶紧跑路,然后联合同事申请劳动仲裁。
虽然过程艰辛,但至少是合法维权途径。
希望咱们打工人,都不会遇到这样的糟心公司和老板。
三、AudioSep
这条上点“干货”:AudioSep。
我们经常会碰到从纷繁的音频中提取和分离所需声音的需求。
比如最简单的:从嘈杂的音频中提取人声。
最近,有一篇新研究,通过自然语言即可提取想要的音频。
我们先看 AudioSep 的效果。
这段音频混合着手风琴和其它声音,想要提取其中干净的手风琴声音。
那么,只需要对算法输入:
accordion
翻译为:手风琴,AudioSep 算法就能自动从这段音频中提取对应的声音,这是提取后的效果:
再比如,这也是一段音频:
想要提起其中的吉他原声,只需要输入:
acoustic guitar
干净的音频就提取出来了:
是不是效果很不错?
不仅是这些音频,说话、笑声也可以,比如这是一段带着背景噪音的笑声:
只需要输入:
laughing
就能提取出干净的笑声:
各种声音都可以通过自然语言提取,键盘声、流水声、猫叫等等。
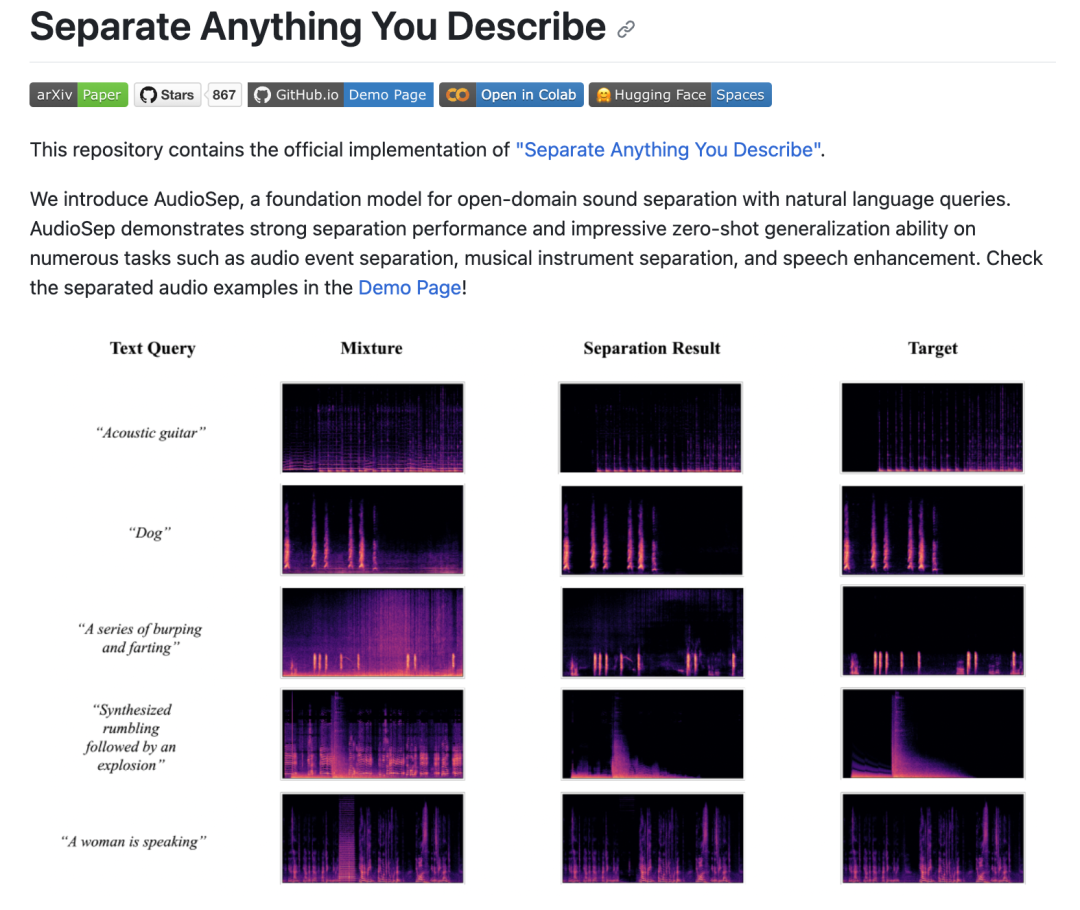
目前算法已经开源:
https://github.com/audio-agi/audiosep
使用方法很简单,首先配置开发环境:
git clone https://github.com/Audio-AGI/AudioSep.git && \
cd AudioSep && \
conda env create -f environment.yml && \
conda activate AudioSep
然后下载模型权重文件放到 checkpoint 目录中。
然后就可以通过如下方式调用,进行预测:
from pipeline import build_audiosep, inference
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = build_audiosep(
config_yaml='config/audiosep_base.yaml',
checkpoint_path='checkpoint/audiosep_base_4M_steps.ckpt',
device=device)
audio_file = 'path_to_audio_file'
text = 'textual_description'
output_file='separated_audio.wav'
# AudioSep processes the audio at 32 kHz sampling rate
inference(model, audio_file, text, output_file, device)
感兴趣的小伙伴不妨试一试!
今天就聊这么多吧,我是 Jack,我们下期见!
 ·················END·················
·················END·················