
mybatis-plus多数据源解析
写在前面文章已收录到我的Github精选,欢迎Star:https://github.com/yehongzhi/learningSummary
上一篇文章大致介绍了dynamic-datasource的功能,用起来的确很方便,只需要一个@DS注解,加上一些简单的配置即可完成多数据源的切换。究竟是怎么做到的呢,底层是怎么实现呢?带着这个疑问,一起研究了一下源码。
由于框架本身功能点比较多,有很多小功能比如支持spel、正则表达式匹配,动态增删数据源这种功能的源码就不去细讲了。我们只关心核心的功能,就是多数据源的切换。
源码解析首先我们都记得,一开始需要引入spring-boot-starter:
<dependency>
<groupId>com.baomidougroupId>
<artifactId>dynamic-datasource-spring-boot-starterartifactId>
<version>3.3.0version>
dependency>
一般starter自动配置,都是从 META-INF/spring.factories文件中指定自动配置类:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.baomidou.dynamic.datasource.spring.boot.autoconfigure.DynamicDataSourceAutoConfiguration
接着打开这个类:
/**
* 动态数据源核心自动配置类
*
* @author TaoYu Kanyuxia
* @see DynamicDataSourceProvider
* @see DynamicDataSourceStrategy
* @see DynamicRoutingDataSource
* @since 1.0.0
*/
@Slf4j
@Configuration
@AllArgsConstructor
//以spring.datasource.dynamic为前缀读取配置
@EnableConfigurationProperties(DynamicDataSourceProperties.class)
//在SpringBoot注入DataSourceAutoConfiguration的bean自动配置之前,先加载注入当前这个类的bean到容器中
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
//引入了Druid的autoConfig和各种数据源连接池的Creator
@Import(value = {DruidDynamicDataSourceConfiguration.class, DynamicDataSourceCreatorAutoConfiguration.class})
//条件加载,当前缀是"spring.datasource.dynamic"配置的时候启用这个autoConfig
@ConditionalOnProperty(prefix = DynamicDataSourceProperties.PREFIX, name = "enabled", havingValue = "true", matchIfMissing = true)
public class DynamicDataSourceAutoConfiguration {
private final DynamicDataSourceProperties properties;
//读取多数据源配置,注入到spring容器中
@Bean
@ConditionalOnMissingBean
public DynamicDataSourceProvider dynamicDataSourceProvider() {
Map datasourceMap = properties.getDatasource();
return new YmlDynamicDataSourceProvider(datasourceMap);
}
//注册自己的动态多数据源DataSource
@Bean
@ConditionalOnMissingBean
public DataSource dataSource(DynamicDataSourceProvider dynamicDataSourceProvider) {
DynamicRoutingDataSource dataSource = new DynamicRoutingDataSource();
dataSource.setPrimary(properties.getPrimary());
dataSource.setStrict(properties.getStrict());
dataSource.setStrategy(properties.getStrategy());
dataSource.setProvider(dynamicDataSourceProvider);
dataSource.setP6spy(properties.getP6spy());
dataSource.setSeata(properties.getSeata());
return dataSource;
}
//AOP切面,对DS注解过的方法进行增强,达到切换数据源的目的
@Role(value = BeanDefinition.ROLE_INFRASTRUCTURE)
@Bean
@ConditionalOnMissingBean
public DynamicDataSourceAnnotationAdvisor dynamicDatasourceAnnotationAdvisor(DsProcessor dsProcessor) {
DynamicDataSourceAnnotationInterceptor interceptor = new DynamicDataSourceAnnotationInterceptor(properties.isAllowedPublicOnly(), dsProcessor);
DynamicDataSourceAnnotationAdvisor advisor = new DynamicDataSourceAnnotationAdvisor(interceptor);
advisor.setOrder(properties.getOrder());
return advisor;
}
//关于分布式事务加强
@Role(value = BeanDefinition.ROLE_INFRASTRUCTURE)
@ConditionalOnProperty(prefix = DynamicDataSourceProperties.PREFIX, name = "seata", havingValue = "false", matchIfMissing = true)
@Bean
public Advisor dynamicTransactionAdvisor() {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("@annotation(com.baomidou.dynamic.datasource.annotation.DSTransactional)");
return new DefaultPointcutAdvisor(pointcut, new DynamicTransactionAdvisor());
}
//动态参数解析器链
@Bean
@ConditionalOnMissingBean
public DsProcessor dsProcessor() {
DsHeaderProcessor headerProcessor = new DsHeaderProcessor();
DsSessionProcessor sessionProcessor = new DsSessionProcessor();
DsSpelExpressionProcessor spelExpressionProcessor = new DsSpelExpressionProcessor();
headerProcessor.setNextProcessor(sessionProcessor);
sessionProcessor.setNextProcessor(spelExpressionProcessor);
return headerProcessor;
}
}
我们可以发现,在使用的时候配置的前缀为spring.datasource.dynamic的配置都会被读取到DynamicDataSourceProperties类,作为一个Bean注入到Spring容器。其实这种读取配置文件信息的方式在日常开发中也是很常见的。
@Slf4j
@Getter
@Setter
@ConfigurationProperties(prefix = DynamicDataSourceProperties.PREFIX)
public class DynamicDataSourceProperties {
public static final String PREFIX = "spring.datasource.dynamic";
public static final String HEALTH = PREFIX + ".health";
/**
* 必须设置默认的库,默认master
*/
private String primary = "master";
/**
* 是否启用严格模式,默认不启动. 严格模式下未匹配到数据源直接报错, 非严格模式下则使用默认数据源primary所设置的数据源
*/
private Boolean strict = false;
/**
* 是否使用p6spy输出,默认不输出
*/
private Boolean p6spy = false;
/**
* 是否使用开启seata,默认不开启
*/
private Boolean seata = false;
/**
* seata使用模式,默认AT
*/
private SeataMode seataMode = SeataMode.AT;
/**
* 是否使用 spring actuator 监控检查,默认不检查
*/
private boolean health = false;
/**
* 每一个数据源
*/
private Map datasource = new LinkedHashMap<>();
/**
* 多数据源选择算法clazz,默认负载均衡算法
*/
private Class strategy = LoadBalanceDynamicDataSourceStrategy.class;
/**
* aop切面顺序,默认优先级最高
*/
private Integer order = Ordered.HIGHEST_PRECEDENCE;
/**
* Druid全局参数配置
*/
@NestedConfigurationProperty
private DruidConfig druid = new DruidConfig();
/**
* HikariCp全局参数配置
*/
@NestedConfigurationProperty
private HikariCpConfig hikari = new HikariCpConfig();
/**
* 全局默认publicKey
*/
private String publicKey = CryptoUtils.DEFAULT_PUBLIC_KEY_STRING;
/**
* aop 切面是否只允许切 public 方法
*/
private boolean allowedPublicOnly = true;
}
但是读取到配置文件怎么让这些配置文件信息跟spring的DataSource结合起来呢?我们利用反向思维,从结果往回推,要整合一个数据源到spring,是需要实现DataSource接口,那么Mybatis-Plus的动态数据源也是有实现的,就是这个:
/**
* 抽象动态获取数据源
*
* @author TaoYu
* @since 2.2.0
*/
public abstract class AbstractRoutingDataSource extends AbstractDataSource {
//抽象方法,由子类实现,让子类决定最终使用的数据源
protected abstract DataSource determineDataSource();
//重写getConnection()方法,实现切换数据源的功能
@Override
public Connection getConnection() throws SQLException {
//这里xid涉及分布式事务的处理
String xid = TransactionContext.getXID();
if (StringUtils.isEmpty(xid)) {
//不使用分布式事务,就是直接返回一个数据连接
return determineDataSource().getConnection();
} else {
String ds = DynamicDataSourceContextHolder.peek();
ConnectionProxy connection = ConnectionFactory.getConnection(ds);
return connection == null ? getConnectionProxy(ds, determineDataSource().getConnection()) : connection;
}
}
}
上面的源码如果学过模板模式肯定都熟悉,他把获取DataSource的行为延伸到子类去实现了,所以关键在于看子类的实现:
@Slf4j
public class DynamicRoutingDataSource extends AbstractRoutingDataSource implements InitializingBean, DisposableBean {
private static final String UNDERLINE = "_";
/**
* 所有数据库
*/
private final Map dataSourceMap = new ConcurrentHashMap<>();
/**
* 分组数据库
*/
private final Map groupDataSources = new ConcurrentHashMap<>();
@Setter
private DynamicDataSourceProvider provider;
@Setter
private Class strategy = LoadBalanceDynamicDataSourceStrategy.class;
@Setter
private String primary = "master";
@Setter
private Boolean strict = false;
@Setter
private Boolean p6spy = false;
@Setter
private Boolean seata = false;
@Override
public DataSource determineDataSource() {
return getDataSource(DynamicDataSourceContextHolder.peek());
}
private DataSource determinePrimaryDataSource() {
log.debug("dynamic-datasource switch to the primary datasource");
return groupDataSources.containsKey(primary) ? groupDataSources.get(primary).determineDataSource() : dataSourceMap.get(primary);
}
@Override
public void afterPropertiesSet() throws Exception {
// 检查开启了配置但没有相关依赖
checkEnv();
// 添加并分组数据源
Map dataSources = provider.loadDataSources();
for (Map.Entry dsItem : dataSources.entrySet()) {
addDataSource(dsItem.getKey(), dsItem.getValue());
}
// 检测默认数据源是否设置
if (groupDataSources.containsKey(primary)) {
log.info("dynamic-datasource initial loaded [{}] datasource,primary group datasource named [{}]", dataSources.size(), primary);
} else if (dataSourceMap.containsKey(primary)) {
log.info("dynamic-datasource initial loaded [{}] datasource,primary datasource named [{}]", dataSources.size(), primary);
} else {
throw new RuntimeException("dynamic-datasource Please check the setting of primary");
}
}
}
他实现了InitializingBean接口,这个接口需要实现afterPropertiesSet()方法,这是一个Bean的生命周期函数,在Bean初始化的时候做一些操作。
这里做的操作就是检查配置,然后通过调用provider.loadDataSources()方法获取到关于DataSource的Map集合,Key是数据源的名称,Value则是DataSource。
@Slf4j
@AllArgsConstructor
public class YmlDynamicDataSourceProvider extends AbstractDataSourceProvider {
/**
* 所有数据源
*/
private final Map dataSourcePropertiesMap;
@Override
public Map loadDataSources() {
//调AbstractDataSourceProvider的createDataSourceMap()方法
return createDataSourceMap(dataSourcePropertiesMap);
}
}
@Slf4j
public abstract class AbstractDataSourceProvider implements DynamicDataSourceProvider {
@Autowired
private DefaultDataSourceCreator defaultDataSourceCreator;
protected Map createDataSourceMap(
Map dataSourcePropertiesMap) {
Map dataSourceMap = new HashMap<>(dataSourcePropertiesMap.size() * 2);
for (Map.Entry item : dataSourcePropertiesMap.entrySet()) {
DataSourceProperty dataSourceProperty = item.getValue();
String poolName = dataSourceProperty.getPoolName();
if (poolName == null || "".equals(poolName)) {
poolName = item.getKey();
}
dataSourceProperty.setPoolName(poolName);
dataSourceMap.put(poolName, defaultDataSourceCreator.createDataSource(dataSourceProperty));
}
return dataSourceMap;
}
}
这里的defaultDataSourceCreator.createDataSource()方法使用到适配器模式。
因为每种配置数据源创建的DataSource实现类都不一定相同的,所以需要根据配置的数据源类型进行具体的DataSource创建。
@Override
public DataSource createDataSource(DataSourceProperty dataSourceProperty, String publicKey) {
DataSourceCreator dataSourceCreator = null;
//this.creators是所有适配的DataSourceCreator实现类
for (DataSourceCreator creator : this.creators) {
//根据配置匹配对应的dataSourceCreator
if (creator.support(dataSourceProperty)) {
//如果匹配,则使用对应的dataSourceCreator
dataSourceCreator = creator;
break;
}
}
if (dataSourceCreator == null) {
throw new IllegalStateException("creator must not be null,please check the DataSourceCreator");
}
//然后再调用createDataSource方法进行创建对应DataSource
DataSource dataSource = dataSourceCreator.createDataSource(dataSourceProperty, publicKey);
this.runScrip(dataSource, dataSourceProperty);
return wrapDataSource(dataSource, dataSourceProperty);
}
对应的全部实现类是放在creator包下:
我们看其中一个实现类就:
@Data
@AllArgsConstructor
public class HikariDataSourceCreator extends AbstractDataSourceCreator implements DataSourceCreator {
private static Boolean hikariExists = false;
static {
try {
Class.forName(HIKARI_DATASOURCE);
hikariExists = true;
} catch (ClassNotFoundException ignored) {
}
}
private HikariCpConfig hikariCpConfig;
//创建HikariCp数据源
@Override
public DataSource createDataSource(DataSourceProperty dataSourceProperty, String publicKey) {
if (StringUtils.isEmpty(dataSourceProperty.getPublicKey())) {
dataSourceProperty.setPublicKey(publicKey);
}
HikariConfig config = dataSourceProperty.getHikari().toHikariConfig(hikariCpConfig);
config.setUsername(dataSourceProperty.getUsername());
config.setPassword(dataSourceProperty.getPassword());
config.setJdbcUrl(dataSourceProperty.getUrl());
config.setPoolName(dataSourceProperty.getPoolName());
String driverClassName = dataSourceProperty.getDriverClassName();
if (!StringUtils.isEmpty(driverClassName)) {
config.setDriverClassName(driverClassName);
}
return new HikariDataSource(config);
}
//判断是否是HikariCp数据源
@Override
public boolean support(DataSourceProperty dataSourceProperty) {
Class type = dataSourceProperty.getType();
return (type == null && hikariExists) || (type != null && HIKARI_DATASOURCE.equals(type.getName()));
}
}
再回到之前的,当拿到DataSource的Map集合之后,再做什么呢?
接着调addDataSource()方法,这个方法是根据下划线"_"对数据源进行分组,最后放到groupDataSources成员变量里面。
/**
* 新数据源添加到分组
*
* @param ds 新数据源的名字
* @param dataSource 新数据源
*/
private void addGroupDataSource(String ds, DataSource dataSource) {
if (ds.contains(UNDERLINE)) {
String group = ds.split(UNDERLINE)[0];
GroupDataSource groupDataSource = groupDataSources.get(group);
if (groupDataSource == null) {
try {
//顺便设置负载均衡策略,strategy默认是LoadBalanceDynamicDataSourceStrategy
groupDataSource = new GroupDataSource(group, strategy.getDeclaredConstructor().newInstance());
groupDataSources.put(group, groupDataSource);
} catch (Exception e) {
throw new RuntimeException("dynamic-datasource - add the datasource named " + ds + " error", e);
}
}
groupDataSource.addDatasource(ds, dataSource);
}
}
分组的时候,会顺便把负载均衡策略也一起设置进去。这个负载均衡是做什么呢?
比如一个组master里有三个数据源(A、B、C),需要合理地分配使用的频率,不可能全都使用某一个,那么这就需要负载均衡策略,默认是轮询,对应的类是:
public class LoadBalanceDynamicDataSourceStrategy implements DynamicDataSourceStrategy {
/**
* 负载均衡计数器
*/
private final AtomicInteger index = new AtomicInteger(0);
@Override
public DataSource determineDataSource(List dataSources) {
return dataSources.get(Math.abs(index.getAndAdd(1) % dataSources.size()));
}
}
获取数据源的时候就通过:
@Override
public DataSource determineDataSource() {
return getDataSource(DynamicDataSourceContextHolder.peek());
}
/**
* 获取数据源
*
* @param ds 数据源名称
* @return 数据源
*/
public DataSource getDataSource(String ds) {
//没有传数据源名称,默认使用主数据源
if (StringUtils.isEmpty(ds)) {
return determinePrimaryDataSource();
//判断分组数据源是否包含,如果包含则从分组数据源获取返回
} else if (!groupDataSources.isEmpty() && groupDataSources.containsKey(ds)) {
log.debug("dynamic-datasource switch to the datasource named [{}]", ds);
return groupDataSources.get(ds).determineDataSource();
//如果普通数据源包含,则从普通数据源返回
} else if (dataSourceMap.containsKey(ds)) {
log.debug("dynamic-datasource switch to the datasource named [{}]", ds);
return dataSourceMap.get(ds);
}
if (strict) {
throw new RuntimeException("dynamic-datasource could not find a datasource named" + ds);
}
return determinePrimaryDataSource();
}
那么上面的DynamicDataSourceContextHolder这个类是干嘛的呢?注解@DS的值又是怎么传进来的呢?
回到最开始的自动配置类,其中有一个是配置DynamicDataSourceAnnotationAdvisor的,还设置了一个拦截器:
@Role(value = BeanDefinition.ROLE_INFRASTRUCTURE)
@Bean
@ConditionalOnMissingBean
public DynamicDataSourceAnnotationAdvisor dynamicDatasourceAnnotationAdvisor(DsProcessor dsProcessor) {
//创建拦截器
DynamicDataSourceAnnotationInterceptor interceptor = new DynamicDataSourceAnnotationInterceptor(properties.isAllowedPublicOnly(), dsProcessor);
DynamicDataSourceAnnotationAdvisor advisor = new DynamicDataSourceAnnotationAdvisor(interceptor);
advisor.setOrder(properties.getOrder());
return advisor;
}
DynamicDataSourceAnnotationAdvisor是用于AOP切面编程的,针对注解@DS的切面进行处理:
public class DynamicDataSourceAnnotationAdvisor extends AbstractPointcutAdvisor implements BeanFactoryAware {
//通知
private final Advice advice;
//切入点
private final Pointcut pointcut;
public DynamicDataSourceAnnotationAdvisor(@NonNull DynamicDataSourceAnnotationInterceptor dynamicDataSourceAnnotationInterceptor) {
this.advice = dynamicDataSourceAnnotationInterceptor;
this.pointcut = buildPointcut();
}
@Override
public Pointcut getPointcut() {
return this.pointcut;
}
@Override
public Advice getAdvice() {
return this.advice;
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
if (this.advice instanceof BeanFactoryAware) {
((BeanFactoryAware) this.advice).setBeanFactory(beanFactory);
}
}
private Pointcut buildPointcut() {
//类上面添加了注解
Pointcut cpc = new AnnotationMatchingPointcut(DS.class, true);
//方法上添加了注解
Pointcut mpc = new AnnotationMethodPoint(DS.class);
//方法优于类
return new ComposablePointcut(cpc).union(mpc);
}
}
切入点我们都清楚了,是@DS注解。那么做了什么处理,主要看advice,也就是传进来的那个拦截器
DynamicDataSourceAnnotationInterceptor。
public class DynamicDataSourceAnnotationInterceptor implements MethodInterceptor {
/**
* The identification of SPEL.
*/
private static final String DYNAMIC_PREFIX = "#";
private final DataSourceClassResolver dataSourceClassResolver;
private final DsProcessor dsProcessor;
public DynamicDataSourceAnnotationInterceptor(Boolean allowedPublicOnly, DsProcessor dsProcessor) {
dataSourceClassResolver = new DataSourceClassResolver(allowedPublicOnly);
this.dsProcessor = dsProcessor;
}
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
//找到@DS注解的属性值,也就是数据源名称
String dsKey = determineDatasourceKey(invocation);
//把数据源名称push到当前线程的栈
DynamicDataSourceContextHolder.push(dsKey);
try {
//执行当前方法
return invocation.proceed();
} finally {
//从栈里释放数据源
DynamicDataSourceContextHolder.poll();
}
}
//这个是使用责任链模式进行一些处理,可以先不管他
private String determineDatasourceKey(MethodInvocation invocation) {
String key = dataSourceClassResolver.findDSKey(invocation.getMethod(), invocation.getThis());
return (!key.isEmpty() && key.startsWith(DYNAMIC_PREFIX)) ? dsProcessor.determineDatasource(invocation, key) : key;
}
}
这里也有一个DynamicDataSourceContextHolder,这样就跟前面获取数据连接关联起来了,最后我们看一下这个类的源码:
/**
* 核心基于ThreadLocal的切换数据源工具类
*
* @author TaoYu Kanyuxia
* @since 1.0.0
*/
public final class DynamicDataSourceContextHolder {
/**
* 为什么要用链表存储(准确的是栈)
*
* 为了支持嵌套切换,如ABC三个service都是不同的数据源
* 其中A的某个业务要调B的方法,B的方法需要调用C的方法。一级一级调用切换,形成了链。
* 传统的只设置当前线程的方式不能满足此业务需求,必须使用栈,后进先出。
*
*/
private static final ThreadLocal> LOOKUP_KEY_HOLDER = new NamedThreadLocal>("dynamic-datasource") {
@Override
protected Deque initialValue() {
return new ArrayDeque<>();
}
};
private DynamicDataSourceContextHolder() {
}
/**
* 获得当前线程数据源
*
* @return 数据源名称
*/
public static String peek() {
return LOOKUP_KEY_HOLDER.get().peek();
}
/**
* 设置当前线程数据源
*
* 如非必要不要手动调用,调用后确保最终清除
*
*
* @param ds 数据源名称
*/
public static void push(String ds) {
LOOKUP_KEY_HOLDER.get().push(StringUtils.isEmpty(ds) ? "" : ds);
}
/**
* 清空当前线程数据源
*
* 如果当前线程是连续切换数据源 只会移除掉当前线程的数据源名称
*
*/
public static void poll() {
Deque deque = LOOKUP_KEY_HOLDER.get();
deque.poll();
if (deque.isEmpty()) {
LOOKUP_KEY_HOLDER.remove();
}
}
/**
* 强制清空本地线程
*
* 防止内存泄漏,如手动调用了push可调用此方法确保清除
*
*/
public static void clear() {
LOOKUP_KEY_HOLDER.remove();
}
}
这里为什么使用栈,主要是会存在嵌套切换数据源的情况,也就是最里面那层数据源应该先释放,最外面那层的数据源应该最后释放,所以需要用栈的数据结构。
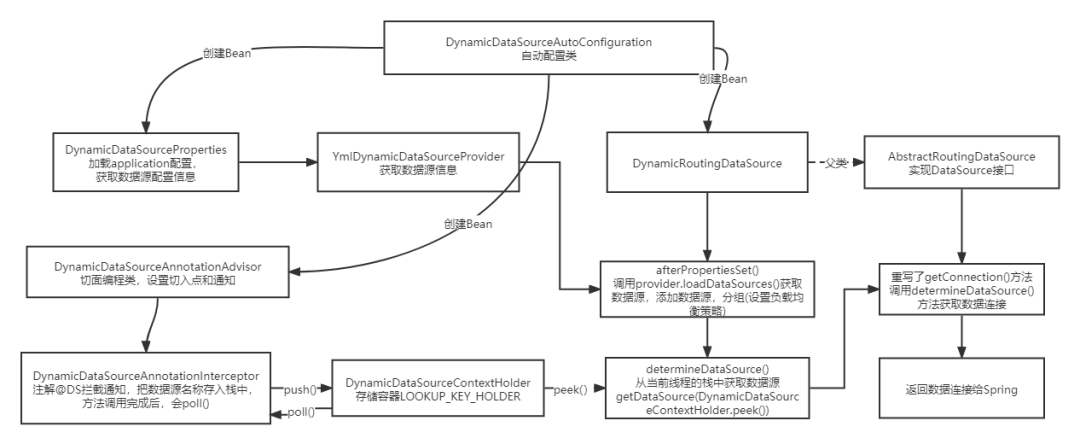
整体流程可能大家还是有点晕,毕竟有点绕,很正常。那么想研究透彻一点,我建议大家自己打开IDEA,参考我写的去研究一下。这里我画个整体的流程图,能有个大概的思路:
 总结
总结源码解析能提高读代码的能力,读代码的能力我觉得是很重要的,因为当我们加入一个新公司的时候,对项目不熟悉,那么就需要从文档,代码上面去了解项目。读懂代码才能去修改、扩展。
这篇文章介绍的这个框架的源码解析只是涉及核心代码,所以不是很难,有兴趣的同学可以自己多看几遍。多数据源的应用在日常项目中也是很常见的场景。
非常感谢你的阅读,希望这篇文章能给到你帮助和启发。
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!
能力有限,如果有什么错误或者不当之处,请大家批评指正,一起学习交流!