
有手就会-用MNIST训练一个CNN模型并识别自己手写数字
大家好,我是小伍哥,今天我们学点视觉的东西。很多人学图片算法的时候,MNIST手写数字识别都是第一个练手的项目,其实干跑也没啥意思,我们今天训练一个模型用来识别自己的手写数字,看看能不能实现,这样学起来更有参与感点,也更实用,过程介绍也比较详细,适合初学者。
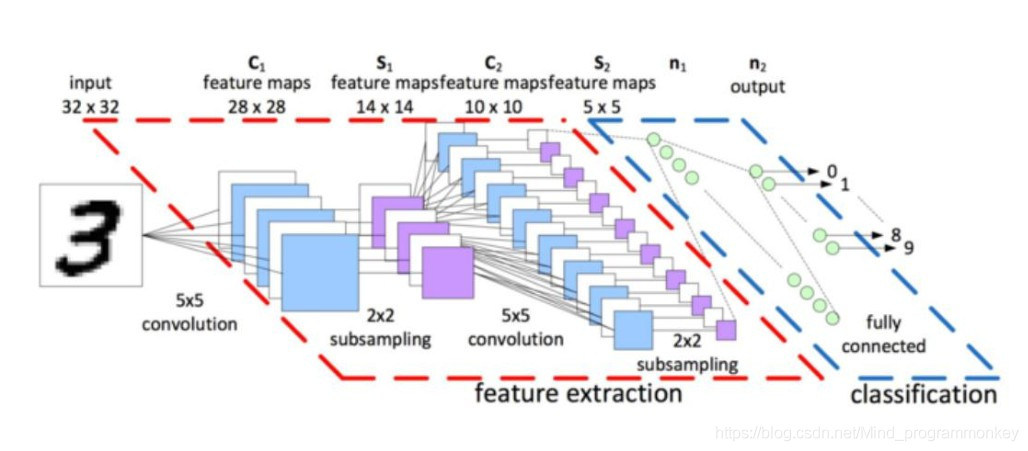
一、CNN模型构建
from keras import layersfrom keras import modelsmodel = models.Sequential()model.add(layers.Conv2D(32, (3, 3),activation='relu',input_shape=(28, 28, 1)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dropout(0.25))model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 十个分类
卷积神经网络接收形状为(image_height, image_width, image_channels)的输入张量(不包括批量维度)。本例中设置卷积神经网络处理大小为(28, 28, 1) 的输入张量,这正是MNIST 图像的格式。我们向第一层传入参数input_shape=(28, 28, 1) 来完成此设置。我们来看一下目前卷积神经网络的架构。
model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param #=================================================================conv2d (Conv2D) (None, 26, 26, 32) 320_________________________________________________________________max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0_________________________________________________________________conv2d_1 (Conv2D) (None, 11, 11, 64) 18496_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0_________________________________________________________________conv2d_2 (Conv2D) (None, 3, 3, 64) 36928_________________________________________________________________flatten (Flatten) (None, 576) 0_________________________________________________________________dropout (Dropout) (None, 576) 0_________________________________________________________________dense (Dense) (None, 64) 36928_________________________________________________________________dense_1 (Dense) (None, 10) 650=================================================================Total params: 93,322Trainable params: 93,322Non-trainable params: 0_________________________________________________________________
这里需要理解其中的具体结构,比如参数个数18496,这个的算法是(3*3*32+1)*64 得来的,这里需要充分的理解什么事参数,什么事偏置。每个卷积核单元就是一个训练参数,3*3的就有9个,上一层有32个深度,需要32个3*3的卷积核,卷积乘完了还需要加一个偏置。所以有了上面的参数个数。
二、图片下载与查看
第一步我们需要获取训练数据,mnist这个数据集,已经内置到Keras包里了,直接下载就可以,具体的代码如下。
from keras.datasets import mnistfrom keras.utils import to_categoricalfrom keras import datasets# 加载数据集(train_images,train_labels), (test_images,test_labels) = mnist.load_data()‘’‘我们可以看到下载的进度Using TensorFlow backend.Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz540672/11490434 [>.............................] - ETA: 9:00‘’‘# 训练集有60000个样本train_images.shape(60000, 28, 28)# 测试集有10000个样本test_images.shape(10000, 28, 28)train_images[1].shape(28, 28)# 看看一个数字的像素点长啥样,选取了部分train_images[1]array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 51, 159, 253, 159, 50, 0, 0, 0, 0, 0, 0,0, 0],····]]#可以看看内置的所有数据集print(dir(datasets))['absolute_import', 'boston_housing', 'cifar', 'cifar10', 'cifar100','fashion_mnist', 'imdb', 'mnist', 'reuters']
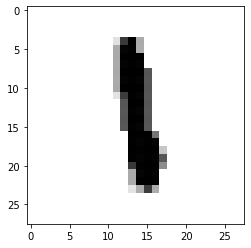
把矩阵打印出来看看,第200个,是数字1
import matplotlib.pyplot as pltplt.imshow(train_images[200] , cmap=plt.cm.binary)plt.show()
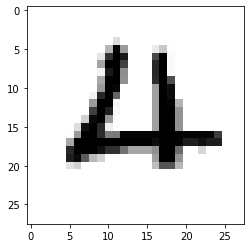
第1220个,是数字4
plt.imshow(train_images[1220] , cmap=plt.cm.binary)plt.show()
三、模型训练&准确率评估
我们开始训练模型,第一步是要调整图片的格式,通道1,并除以255归一化,将像素值转换到0-1之间,方便反向传播数据的更新。
train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype('float32') / 255train_labels = to_categorical(train_labels)test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype('float32') / 255test_labels = to_categorical(test_labels)model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])model.fit(train_images,train_labels,epochs=5,batch_size=64)
训练完成了,我们在测试集上测试下模型的准确率,可以看到,这么一个简单的模型,我们的准确率就达到了99.14%,深度学习还是非常强大的
test_loss, test_acc = model.evaluate(test_images, test_labels)test_acc0.9914000034332275
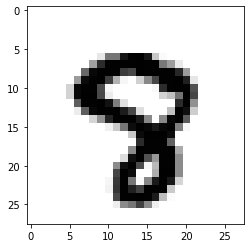
看看预测的到底准不准呢,我们看看预测的细节
import numpy as npimport matplotlib.pyplot as plty_pred = model.predict(test_images)pred = np.argmax(y_pred, axis=1)#看看第2990个数字是啥,我们预测的是8,看看图片也是8,挺准的steps = 2990print('pred: ',pred[steps])pred: 8plt.imshow(test_images[steps] , cmap=plt.cm.binary)plt.show()
四、预测自己的手写数字
在测试集效果好,那在实际应用中到底好不好呢,我们自己手写几个测试下,模型训练好了就可以保存着以后用了,预测的时候直接加载就行,如果预测样本没有发生比较大的变化,那训练好的模型理论上可以一直使用,大概的预测过程如下:

根据上面的训练,模型的准确率还挺高得,但是实际有没有用呢,还需要用自己的数据进行测试,打开自己在画图板或者在笔记本上随便写几个数字,然后单个截图保存后进行预测。
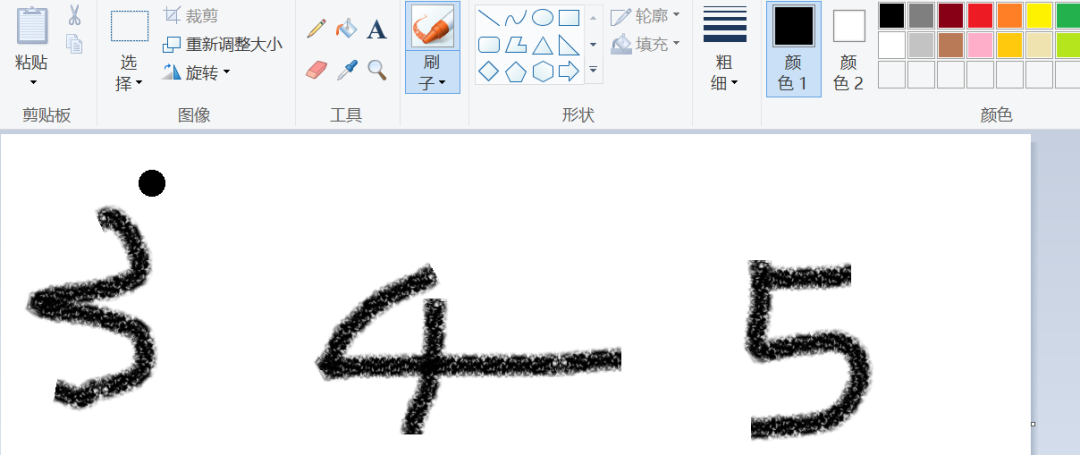
分别截图后保存成img3、img4、img5......,下面进行预处理,处理成和模型训练一样的数据才能预测。
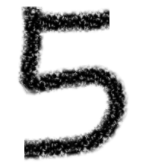
from keras.preprocessing.image import load_img,img_to_arrayimport matplotlib.pyplot as pltimport numpy as np#读取图片、调整图片大小,转换成灰度 help(load_img)path = 'C:/Users/伍正祥/Desktop/img5.jpg'img = load_img(path, target_size=(28, 28),color_mode="grayscale")#255-为了调成白底,系统灰度转换自动给处理成黑底了,所以做个反转img = 255-img_to_array(img)#查看自己加载的图片plt.imshow(img , cmap=plt.cm.binary)plt.show()#图片形状调整,需要调整到和训练集一样的格式img = img.astype('float32')/255img = img.reshape((1, 28, 28, 1))#进行图片进行预测y_pred = model.predict(img)print('预测数字:',np.argmax(y_pred, axis=1)[0]print('预测概率:',y_pred)
读取5的的手写图片并进行预测,可以看到预测的结果为5.
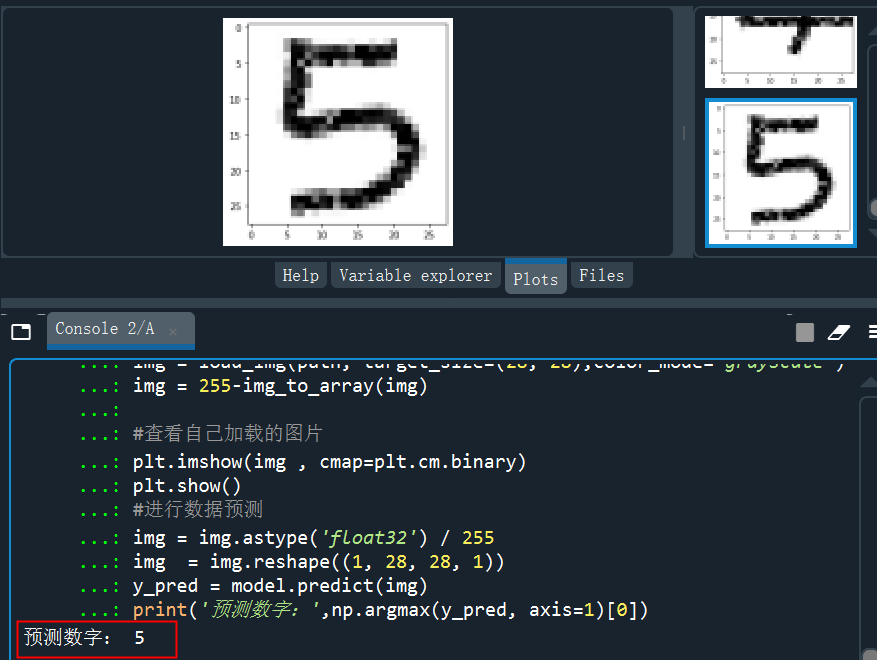
看看预测的概率分布,是5的概率几乎接近于1
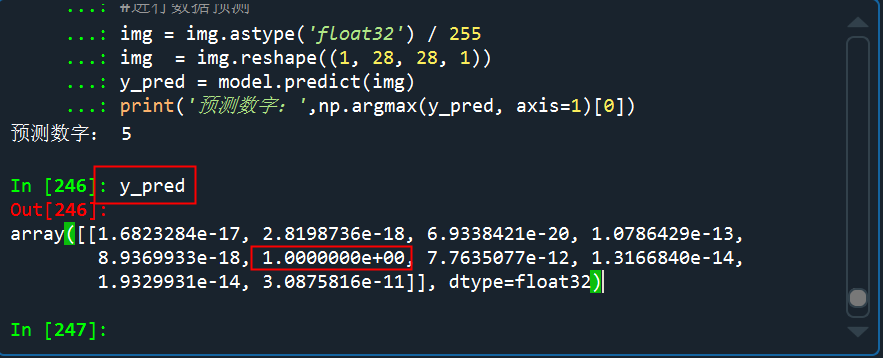
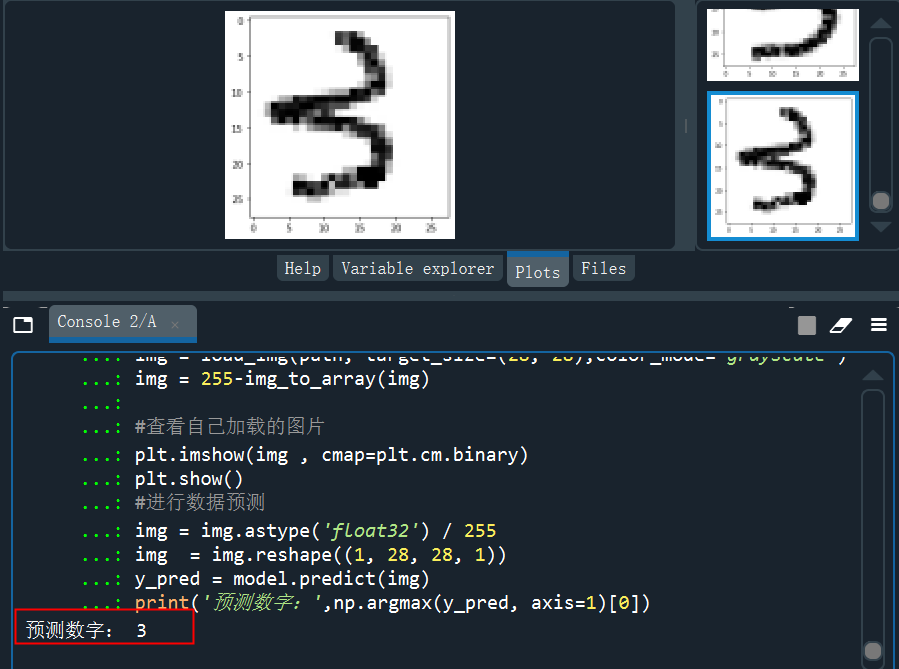
读取3的的手写图片并预测
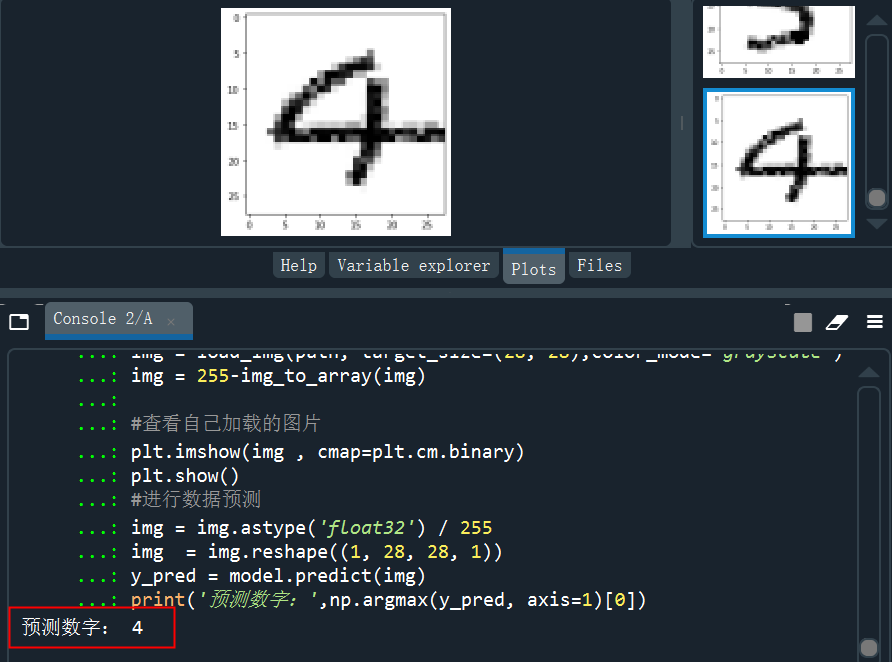
读取4的的手写图片并预测
从测试的结果来看,预测效果还是非常不错的,多试几次,也有预测错的,但是错的概率比较小。网络结构比较简单,如果对于接触的不多的同学,理解卷积还是比较困难的。特别是每一层的具体细节以及参数个数等,大家可以多看看一些可视化CNN的文章,充分理解。
··· END ···
往期精彩:
风控难题之无监督风险感知:脑力、想象力、第六感、黑洞、星座、面相···
情侣、基友、渣男和狗-基于SynchroTrap+LPA算法的团伙账户挖掘
异常检测算法之(HBOS)-Histogram-based Outlier Score