
支付宝面试:什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决?
共 9207字,需浏览 19分钟
·
2020-10-31 16:11
点击“开发者技术前线”,选择“星标?”
让一部分开发者看到未来
作者:riemann_
遇到这个 Java Serializable 序列化这个接口,我们可能会有如下的问题
什么叫序列化和反序列化 作用。为啥要实现这个 Serializable 接口,也就是为啥要序列化 serialVersionUID 这个的值到底是在怎么设置的,有什么用。有的是1L,有的是一长串数字,迷惑ing。
我刚刚见到这个关键字 Serializable 的时候,就有如上的这么些问题。
在处理这个问题之前,你要先知道一个问题,这个比较重要。这个Serializable接口,以及相关的东西,全部都在 Java io 里面的。
一、序列化和反序列化的概念
序列化:把对象转换为字节序列的过程称为对象的序列化。 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
上面是专业的解释,现在来点通俗的解释。在代码运行的时候,我们可以看到很多的对象(debug过的都造吧),可以是一个,也可以是一类对象的集合,很多的对象数据,这些数据中,有些信息我们想让他持久的保存起来,那么这个序列化。
就是把内存里面的这些对象给变成一连串的字节描述的过程。
常见的就是变成文件
我不序列化也可以保存文件啥的呀,有什么影响呢?我也是这么问的。
二、什么情况下需要序列化
当你想把的内存中的对象状态保存到一个文件中或者数据库中时候; 当你想用套接字在网络上传送对象的时候; 当你想通过RMI传输对象的时候;
(老实说,上面的几种,我可能就用过个存数据库的)
三、如何实现序列化
实现Serializable接口即可
上面这些理论都比较简单,下面实际代码看看这个序列化到底能干啥,以及会产生的bug问题。
先上对象代码,FlyPig.java
package com.test;import java.io.Serializable;public class FlyPig implements Serializable {// private static final long serialVersionUID = 1L;private static String AGE = "269";private String name;private String color;transient private String car;private String addTip;public String getName() {return name;}public void setName(String name) {this.name = name;}public String getColor() {return color;}public void setColor(String color) {this.color = color;}public String getCar() {return car;}public void setCar(String car) {this.car = car;}public String getAddTip() {return addTip;}public void setAddTip(String addTip) {this.addTip = addTip;}public String toString() {return "FlyPig{" +"name='" + name + '\'' +", color='" + color + '\'' +", car='" + car + '\'' +", AGE='" + AGE+ '\'' +'}';}}
注意下,注释的代码,是一会儿要各种情况下使用的。
下面就是main方法啦
package com.test;import java.io.*;public class SerializableTest {public static void main(String[] args) throws Exception {serializeFlyPig();FlyPig flyPig = deserializeFlyPig();System.out.println(flyPig.toString());}/*** 序列化*/private static void serializeFlyPig() throws Exception {FlyPig flyPig = new FlyPig();flyPig.setColor("black");flyPig.setName("riemann");flyPig.setName("audi");// ObjectOutputStream 对象输出流,将 flyPig 对象存储到E盘的 flyPig.txt 文件中,完成对 flyPig 对象的序列化操作ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("d:/flypig.txt")));oos.writeObject(flyPig);System.out.println("FlyPig 对象序列化成功!");oos.close();}/*** 反序列化*/private static FlyPig deserializeFlyPig() throws Exception {ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("d:/flypig.txt")));FlyPig pig = (FlyPig) ois.readObject();System.out.println("FlyPig 对象反序列化成功!");return pig;}}
对上面的2个操作文件流的类的简单说明
ObjectOutputStream代表对象输出流:
它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
ObjectInputStream代表对象输入流:
它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
具体怎么看运行情况。
第一种:上来就这些代码,不动,直接run,看效果。
实际运行结果,他会在 d:/flyPig.txt 生成个文件。
FlyPig 对象序列化成功!FlyPig 对象反序列化成功!FlyPig{name='audi', color='black', car='null', AGE='269'}
从运行结果上看:
他实现了对象的序列化和反序列化。
transient 修饰的属性,是不会被序列化的。我设置的奥迪四个圈的车不见啦,成了null。my god。
你先别着急说,这个静态变量AGE也被序列化啦。这个得另测。
第二种:为了验证这个静态的属性能不能被序列化和反序列化,可如下操作。
public class SerializableTest {public static void main(String[] args) throws Exception {serializeFlyPig();// FlyPig flyPig = deserializeFlyPig();// System.out.println(flyPig.toString());}
这个完了之后,意思也就是说,你先序列化个对象到文件了。这个对象是带静态变量的static。
现在修改flyPig类里面的AGE的值,给改成26吧。
然后,看下图里面的运行代码和执行结果。
public class SerializableTest {public static void main(String[] args) throws Exception {// serializeFlyPig();FlyPig flyPig = deserializeFlyPig();System.out.println(flyPig.toString());}
输出结果:
FlyPig 对象反序列化成功!FlyPig{name='audi', color='black', car='null', AGE='26'}
可以看到,刚刚序列化的269,没有读出来。而是刚刚修改的26,如果可以的话,应该是覆盖这个26,是269才对。
所以,得出结论,这个静态static的属性,他不序列化。
第三种:示范这个 serialVersionUID 的作用和用法
最暴力的改法,直接把model的类实现的这个接口去掉。然后执行后面的序列化和反序列化的方法。直接报错。
抛异常:NotSerializableException
这个太暴力啦,不推荐这么干。
然后就是,还和上面的操作差不多,先是单独执行序列化方法。生成文件。然后,打开属性 addTip ,这之后,再次执行反序列化方法,看现象。
抛异常:InvalidClassException 详情如下。
InvalidClassException: com.lxk.model.FlyPig;local class incompatible:stream classdesc serialVersionUID = 7230772301104163489,local class serialVersionUID = -2293195637094031536Exception in thread "main" java.io.InvalidClassException: com.test.FlyPig; local class incompatible: stream classdesc serialVersionUID = 7230772301104163489, local class serialVersionUID = -2293195637094031536at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1885)at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)at com.test.SerializableTest.deserializeFlyPig(SerializableTest.java:33)at com.test.SerializableTest.main(SerializableTest.java:8)
解释一下:
因为我再model里面是没有明确的给这个 serialVersionUID 赋值,但是,Java会自动的给我赋值的,这个值跟这个model的属性相关计算出来的。
我保存的时候,也就是我序列化的时候,那时候还没有这个addTip属性呢,所以,自动生成的serialVersionUID 这个值,在我反序列化的时候Java自动生成的这个serialVersionUID值是不同的,他就抛异常啦。
(你还可以反过来,带ID去序列化,然后,没ID去反序列化。也是同样的问题。)
再来一次,就是先序列化,这个时候,把 private static final long serialVersionUID = 1L; 这行代码的注释打开。那个addTip属性先注释掉,序列化之后,再把这个属性打开,再反序列化。看看什么情况。
FlyPig 对象反序列化成功!FlyPig{name='audi', color='black', car='null', AGE='26', addTip='null'}
这个时候,代码执行OK,一切正常。good。序列化的时候,是没的那个属性的,在发序列化的时候,对应的model多了个属性,但是,反序列化执行OK,没出异常。
这个现象对我们有什么意义:
老铁,这个意义比较大,首先,你要是不知道这个序列化是干啥的,万一他真的如开头所讲的那样存数据库啦,socket传输啦,rmi传输啦。虽然我也不知道这是干啥的。你就给model bean 实现了个这个接口,你没写这个 serialVersionUID 那么在后来扩展的时候,可能就会出现不认识旧数据的bug,那不就炸啦吗。回忆一下上面的这个出错情况。想想都可怕,这个锅谁来背?
所以,有这么个理论,就是在实现这个Serializable 接口的时候,一定要给这个 serialVersionUID 赋值,就是这么个问题。
这也就解释了,我们刚刚开始编码的时候,实现了这个接口之后,为啥IDEA编辑器要黄色警告,需要添加个这个ID的值。而且还是一长串你都不知道怎么来的数字。
下面解释这个 serialVersionUID 的值到底怎么设置才OK。
首先,你可以不用自己去赋值,Java会给你赋值,但是,这个就会出现上面的bug,很不安全,所以,还得自己手动的来。
那么,我该怎么赋值,eclipse可能会自动给你赋值个一长串数字。这个是没必要的。
可以简单的赋值个 1L,这就可以啦。。这样可以确保代码一致时反序列化成功。
不同的serialVersionUID的值,会影响到反序列化,也就是数据的读取,你写1L,注意L大些。计算机是不区分大小写的,但是,作为观众的我们,是要区分1和L的l,所以说,这个值,闲的没事不要乱动,不然一个版本升级,旧数据就不兼容了,你还不知道问题在哪。。。
第四种:当属性是对象的时候,没实现序列化接口
当属性是对象的时候,如果这个对象,没实现序列化接口,那么上面的方法在序列化的时候就在执行oos.writeObject(flyPig)时候,报错了“Exception in thread “main” java.io.NotSerializableException: com.lxk.model.Bird”。然后给刚刚的属性的对象加上实现序列化的接口之后,上面的测试就正常通过了。
下面是摘自 jdk api 文档里面关于接口 Serializable 的描述
类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。因为实现接口也是间接的等同于继承。序列化接口没有方法或字段,仅用于标识可序列化的语义。
# 关于 serialVersionUID 的描述
序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。
如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为 “serialVersionUID” 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID:
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java™ 对象序列化规范”中所述。
不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。
因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 – serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
最后分享一份来自亚马逊工程师写的 Google 面试指南,目前在GitHub上火了
一位从1997年就入行的Web工程师,立志要成为Google软件工程师,3年前写下了一篇超完整学习和面试教程,以此作为自己的奋斗计划。
这位名叫John Washam的工程师,换了好几份工作,最后却阴差阳错在2017年成为了亚马逊AWS的技术专家。
但这并不妨碍他的教程成为热门,在GitHub上线以来,已收获近10万星的好评。
而且最近这篇教程已经完成了中文翻译,就算你没有去Google面试的机会,也可以用它来好好充实一下自己。
为何写这篇教程
作者Washam本人并非计算机学位,但在儿时就已经展现出对计算机的浓厚兴趣,从事的工作是关于web程序的构建、服务器的构建。
作为一名非专业人士转行,Washam已经算是相当成功。然而,他还是想去Google工作,真正地去理解计算机系统、算法效率、数据结构性能、低级别编程语言及其工作原理。
可对这些知识都不了解的他,怎么会被Google应聘呢?
于是他在网上收集了各类计算机专业知识,以及进入谷歌工作的员工分享的资源,并系统地整理了这些资料。
Washam强调,想去Google工作首先不要妄自菲薄。Google的工程师都是才智过人的。但是,就算是工作在 Google 的他们,仍然会因为觉得自己不够聪明而感到一种不安。
学习资源
接下来就跟着Washam的脚步去学习。
首先要做的就是选择一门语言,在Google一般是C++、Java、Python,有时也会用到JavaScript、Ruby。背后还有一些如SQL、HTML等技术没有列出。
接着开始学习计算机硬件知识:

然后补充计算机专业的基础数学知识,如算法复杂度 / Big-O / 渐进分析法、数据结构、树、排序、图论。

此外还有递归、动态规划、组合与概率、NP&NP-完全和近似算法、缓存、线程与进程、系统设计、可伸缩性、数据处理。
看到这么多知识点,你会不会觉得有点懵呢?Washam告诉你一点小技巧。
因为你不可能一遍就记住所有知识点。所以需要把要回顾的知识点做成抽认卡(flashcard):正常的及带有代码的,类似于背单词。
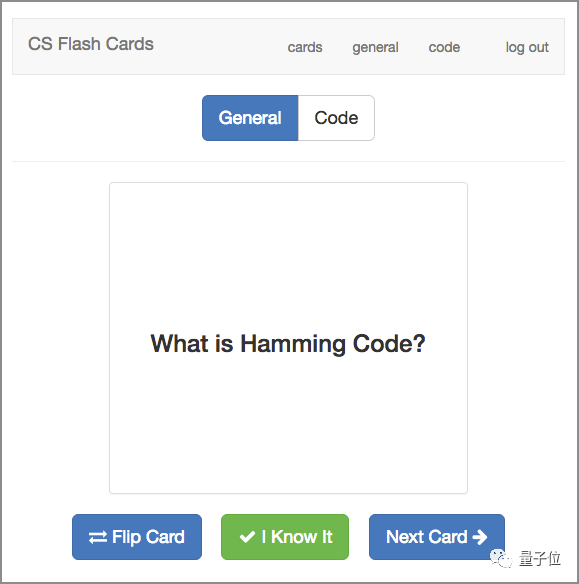
每种卡都会有不同的格式设计。项目主页中就有抽认卡的源代码,可以根据自己的学习特点去制作。
Washam还留有一组 ASCII 码表、OSI 堆栈、Big-O 记号及更多的小抄纸,以便在空余的时候可以学习。每编程半个小时就要休息一下,并去回顾你的抽认卡。
当然,论文的阅读也是必不可少的,尤其是谷歌曾经发表的一些基础技术论文。

书籍则推荐一些关于算法和C++编程之类的。

去Google面试需要注意什么
面试的第一步当然是要有一份好的简历,这样才能为你争取到宝贵的面试机会。知名科技博主Steve Yagge给出了10个贴士,帮你做出一份还不错的简历。

这位Steve曾经在亚马逊、Google都工作过,Washam的这个项目就大量地引用了他的技术博客内容。
在面试时,你可能会遇到这20个问题,每个问题准备 2-3 种回答。准备点故事,而不要只是摆一些你完成的事情的数据。

面试官在也会问你还有哪些问题,不要说自己没有什么要问题,可以试试问一些此类问题:

当然,进入Google也不意味着结束,你还要新的学习过程。
Washam还有一份附加内容,包括Emacs和Vim、Unix命令行工具、密码学。这些内容虽然不会直接用到,但是会大大提高你的效率。
最后,在这样一个特殊的时期,好好给自己充个电。祝大家在新的一年里都能面试成功!
传送门
资源地址。已经整理完成:
扫下面二维码回复”Google面试手册“ 获取公开地址