
GBDT库原理和使用的比较
GBDT拥有广泛的应用,然而GBDT在大数据集存在性能问题。为此很多GBDT方法都聚焦在模型加速和并行计算,在本文中对比了最近的GBDT系统的优缺点。
背景介绍
有许多GBDT的库,虽然这些库提供了类似的功能,但它们的算法设计和系统实现有很大的不同:
XGBoost LightGBM CatBoost ThunderGBM
比如哪些部分分别在GPU和CPU上实现,以及树增长的策略。但树模型整体的构建过程是类似的:每个决策树的构建深度从0到最大深度。采用基于贪心的节点分割算法递归地生长树,直到达到终止条件。
求解每个节点的分裂点的方法包括精确方法和近似方法:
在精确的方法中会遍历所有的特征值,以找到最大化增益的分割。对于高维数据集来说,找到精确的分割点的成本高得令人望而却步。 在近似方法中,只尝试由分位数或直方图等技术生成的一些候选点。
GBDT并行训练
开发高效的GBDT训练并行算法具有挑战性
最小化通信成本 计算资源的利用率 数据适应性
Node Split
寻找一个节点的最佳分割点的传统方法是通过枚举所有分割点,这种方法对于取值空间较大的情况下是非常昂贵的。
当前并行GBDT系统常见解决方案是使用基于直方图的近似,而不是枚举所有可能的分裂点,或者说列举多个有代表性的分裂点。
直方图近似是效率和准确性之间的权衡,但这种解决方案不适用于高维和稀疏问题,因为每个维度都需要与一个直方图关联。 在并行算法中,需要维护的直方图总数等于:线程数乘以特征数量。
Parallelism Granularity
并行度的关键粒度包括三个级别:
节点级别的并行 特征级别的并行 值级别的并行
在节点级并行:一个线程专门用于查找节点的最佳分割,因此它将计算节点中所有特性的所有值的增益。
在特征级并行中:一个线程专门用于仅为一个节点的一个特征查找最佳值。因此一个线程计算一个节点的一个特征的所有值的增益。
在值级并行性中:一个线程计算节点中一个特征的一个值的增益。基于多核CPU的训练算法经常会适应节点级和特征级的并行性。
Training Data Partitioning
当训练问题由多个GPU或多个CPU处理时,需要对训练数据集进行分区,数据有三种划分方法:
基于实例的分区 基于特征的分区 混合实例和特征的分区
基于实例的分区:将许多训练实例分配给机器,其余的实例分配给其他机器。这种分区方式的好处是,每台机器都有存储在其中的实例的全部信息。因此当计算一个实例的训练错误时,存储该实例的机器可以很容易地计算出它。
相比之下,基于特性的分区会将多个特性的所有值分配给一台机器。因此,计算训练错误要困难得多,因为机器没有计算实例的所有信息。但是, 基于特征的划分的优点是,机器可以很容易地找到特征的最佳分割值,因为训练数据的所有特征值都存储在一起。
混合划分分区将训练数据集视为一个矩阵,每个GPU/CPU处理一个块或瓷砖。主流GBDT可以使用基于实例的分区或基于特性的分区。由于实现和维护的复杂性,混合划分方法并没有得到广泛的采用。
GBDT Training on CPUs
在CPU的并行中,有许多挑战:
由于树状结构的性质,GBDT对数据的模式是不规则的。 在GBDT训练期间对特征值进行排序非常耗时。
为了解决这些挑战,现有的GBDT库可以在CPU上并行运行,并在并行性、节点分割和 训练数据分区方面采用不同的设计。
GBDT Training on GPUs
为了利用GPU 的能力,需要在优化GBDT训练的并行性、节点分割和训练数据分区方面做大量的工作。
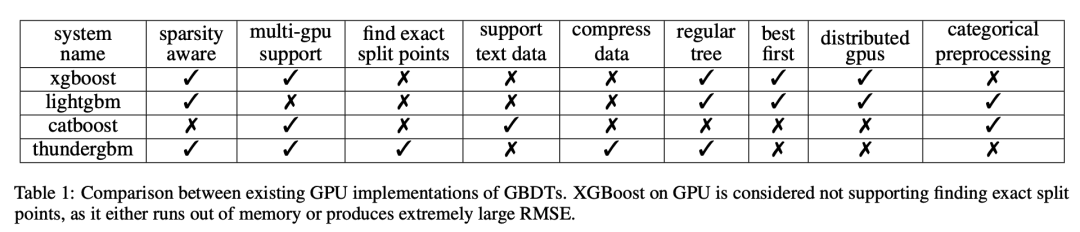
GPU上的XGBoost使用属性级和节点级并行性,对于属性级并行性,GPU线程块用于计算属性的最佳分割点。LightGBM CatBoost还使用寻找最佳分割点来避免在枚举所有可能的分割点的同时消耗过多内存。
System Comparison
所有实验中不同库的预测精度相似,与XGBoost和ThudergGBM相比,LightGBM和CatBoost往往具有较低的预测精度。
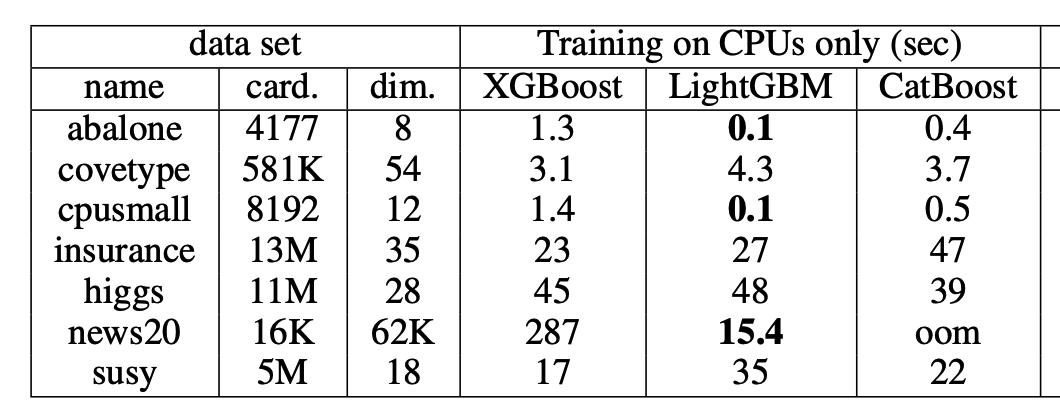
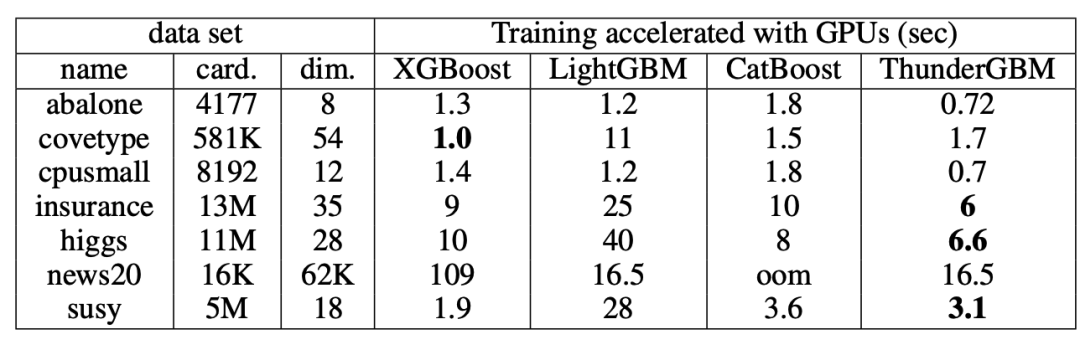
所有的库都可以在GPU上运行来显著提高效率。其次LightGBM通常在CPU上比其他现有库工作得更好,CatBoost在GPU实现是非常好的,但也需要更多的显存。
GBDT分布式训练
Load Balancing
根据实例或特性的数量进行负载平衡 根据特征值的数量进行负载平衡
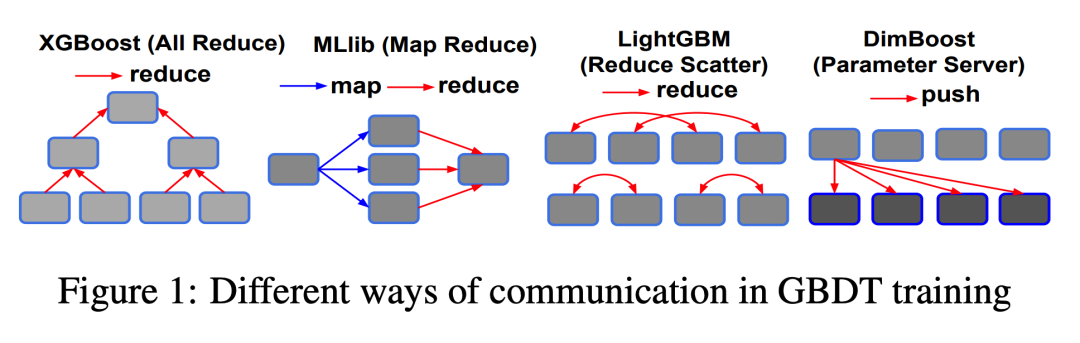
Network Communication
网络通信主要从两个方面出发:构建一个特征的直方图和在所有特征中找到最佳特征。
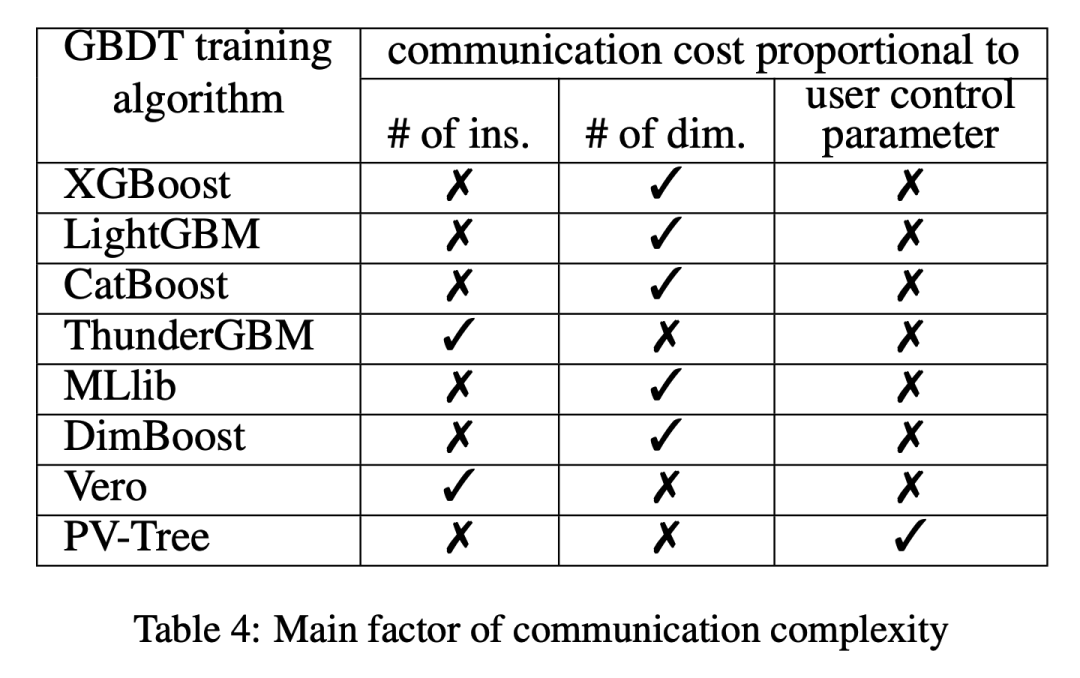
挑战和发展趋势
挑战
尽管拥有很多GBDT库,但一个公平和健壮的基准测试仍然是相当具有挑战性的开放问题。
数据隐私问题,当部署模型时用户可以相对容易地从决策树中提取信息。
自动化的功能工程和参数调优,超参数对模型的精度影响非常大。
增量式学习和在线学习,在流失数据下如何训练已有模型。
发展趋势
使用异构集群的GPU。 在TPU和FPGA上使用GBDT。
相关阅读: