
数字被修改了吗?
日期 : 2021年10月05日
正文共 :2801字
从7.23动车事故开始,死亡35人便成为了一部分网民经久不衰的话题。他们认为,当事故死亡人数超过35人时,省市官员就必须为此负责,因此官员将有动机将死亡人数实际超过35人的事故压低到死亡35人以内。那么,我们如何判断这种现象是否存在?数字到底有没有被修改?
由于随机数字的出现会满足一系列规律,因此,当一系列数字实际出现的规律与其应当出现的规律有显著不同时,这一系列数字就可能被人为更改了。先看几个简单的例子:
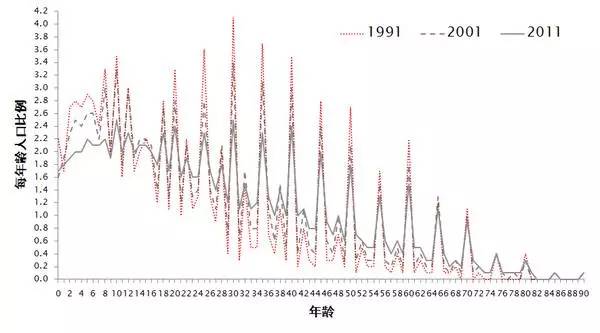
一,大量产生的随机数字汇总后往往会具有平滑的性质,印度人口普查的年龄是一个很好的反例。一般来说,如果没有很强烈的年份偏好或者战争和饥荒,那么一个国家的分年龄人口应当是平滑的。在一个较小的区间内,我们不应当看到波动很大的年龄结构。因此,印度人口普查显示的图形,就显得非常不正常——2011年,约有50%的人口错报了自己的年龄,他们以尾数为0或者5的数字来替代自己的真实年龄。
二,随机序列也有可能看起来不太随机。将一个硬币扔100次,得到一个序列,h为正面t为反面,下面哪个序列是真实的抛硬币结果,哪个是脑补出来的?
序列1:
tthhhhhtthhhhtthhthhhtthhhhttththhhtthhhhhhtthhhhh
htthhthhhthhhhthhththtttththtthhtthhhhhttthhththtt
序列2:
hthtthhtthtthhhthtthtttththhthhththhhhthhtthtththh
hthhhthtththhhthttththhthhhthththhhhthhthttththhth
答案是序列1。在一个完全随机的抛硬币过程中,100次抛掷得到至少一个连续6次相同结果的序列的概率大于80%,得到至少一个连续5次相同结果的序列的概率大于90%。而在序列2里,最长的一串连续序列的长度仅有4。一列伪造的硬币随机数为了让自己看起来更随机,可能会频繁变化正反,但正是这一点反而出卖了它的伪随机本质。
三,真实的数字序列会满足Benford法则。在真实产生的十进制数字中,不同数码的出现次数会满足Benford法则,见下表:
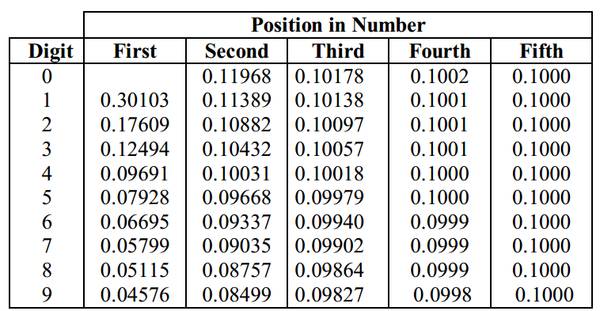 上表的第一列表示随机数字的第一位数中各数码可能出现的概率,即首位数为1的概率为30.1%,首位数为2的概率为17.6%……首位数字为9的概率仅有4.6%。同样我们也能计算第二位数字的出现概率。当一系列数字大幅度偏离Benford法则时,他就很有可能经过人为调整。
上表的第一列表示随机数字的第一位数中各数码可能出现的概率,即首位数为1的概率为30.1%,首位数为2的概率为17.6%……首位数字为9的概率仅有4.6%。同样我们也能计算第二位数字的出现概率。当一系列数字大幅度偏离Benford法则时,他就很有可能经过人为调整。
ANZ银行的研究人员就用该法则对中国的GDP增长数据进行了研究,他们发现,中国从1952年开始的年度GDP增长率中,首位数为1的次数为24次,高于Benford法则预测的18次;从1991年开始的季度GDP增长率中,第二位数为0的比例高达21次,而预测值仅有10次。该研究人员认为,这样的偏差说明了中国的GDP数据可能存在相当的「进位」现象,即将较大的数码进位到10,才导致了第一位数的数码1出现次数偏高且第二位数的数码0的出现次数偏高。
在这份报告里,首位数的Benford法则讨论其实是值得商榷的,假设一列随机数以正态分布取自均值为10的区间内,那么其首位数为1的概率将会高达50%,但这并不能说明这列随机数字是人为调整过的。但第二位数字就不会出现首位数字碰到的问题,其分布则较为均匀,可以进行比较好的比较。
我们可以将中国和美国的季度GDP增长率的第二位数字的出现概率放在一起进行比较,得到下图:
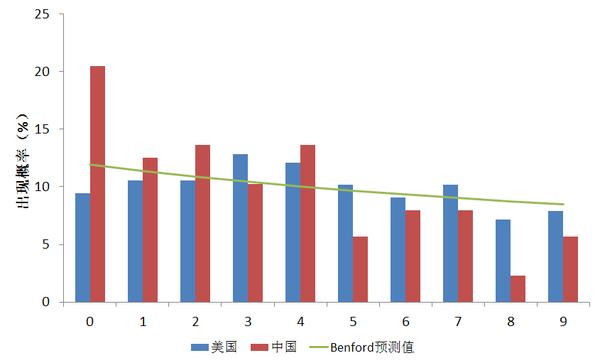 可以看到,中国在第二位数等于0的概率确实要远大于预测值12%,较大数码的出现概率则要小于Benford法则预测值。美国的第二位数字与Benford法也有差距,体现在数码0到3的出现概率提高上。但总体上来说,美国的统计数字距离Benford法则预测的差距要比中国统计数字的差距要小许多,中国在0和8两个数字上的实际出现次数甚至可以在5%水平上显著异于Benford法则的预测。中国是否将一系列尾数为8的GDP增长率给进位到10了?仍然不能确定,但至少这种解释与数据所体现的现象不矛盾。
可以看到,中国在第二位数等于0的概率确实要远大于预测值12%,较大数码的出现概率则要小于Benford法则预测值。美国的第二位数字与Benford法也有差距,体现在数码0到3的出现概率提高上。但总体上来说,美国的统计数字距离Benford法则预测的差距要比中国统计数字的差距要小许多,中国在0和8两个数字上的实际出现次数甚至可以在5%水平上显著异于Benford法则的预测。中国是否将一系列尾数为8的GDP增长率给进位到10了?仍然不能确定,但至少这种解释与数据所体现的现象不矛盾。
四,特大事故的死亡人数被修改了吗?
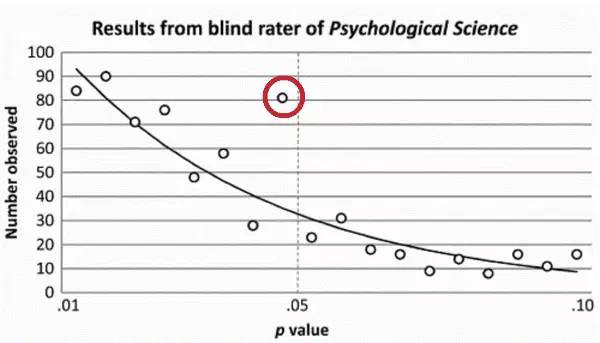
终于回到本文正题。先看一个研究数据是否调整的典型例子:p=0.05现象。在统计分析中,当一项检验的p值小于0.05时,这个结果一般被认为是在统计上显著的。由于不显著的结果难以发表,因此「调整」p值直到小于0.05,成了一些科研人员的最后手段。这一项研究(http://www.ncbi.nlm.nih.gov/pubmed/22853650)检查了三份心理学期刊,发现报告的p值略微小于0.05的文章比例畸高于正常情况,显示了「调整」p值可能已经成为了一种客观存在的现象。
 在 事故查询 里我们能够查询到中国从2000年至今的两万四千余起事故。在所有能查询到的事故中(包括安全生产事故、交通事故与火灾),从2000年7月至2014年底,死亡人数在10人以上的事故有1187起,按照死亡人数排序可得下图:
在 事故查询 里我们能够查询到中国从2000年至今的两万四千余起事故。在所有能查询到的事故中(包括安全生产事故、交通事故与火灾),从2000年7月至2014年底,死亡人数在10人以上的事故有1187起,按照死亡人数排序可得下图:
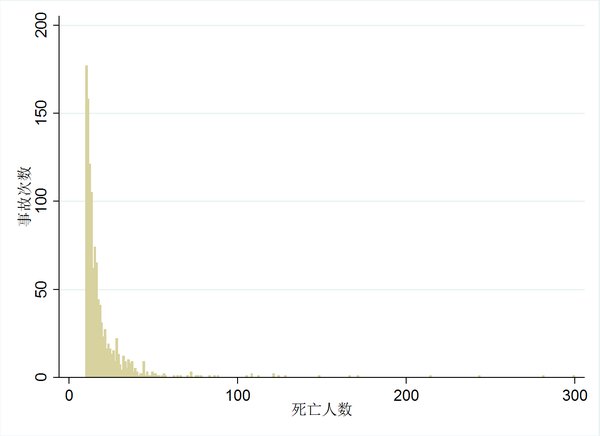 将死亡在20到40人放大看,可得下图:
将死亡在20到40人放大看,可得下图: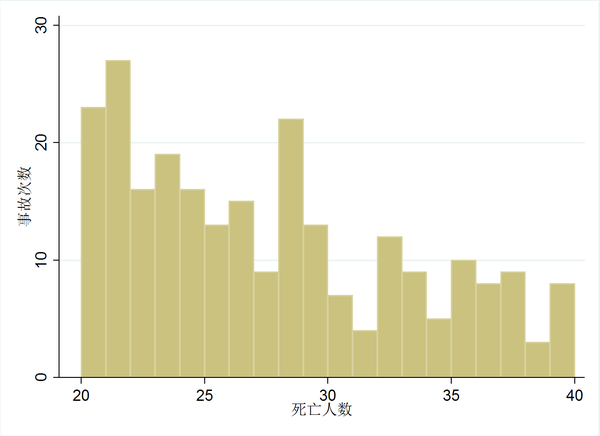 如果35人真的是一个分界点且在这个分界点附近的死亡瞒报现象真的存在,那么我们应当能看到报告死亡人数在33、34人的事故次数畸高(死亡35人及以上但被人为调整至35人以下,且不能调整幅度太大),而报告死亡35人的事故次数迅速下降。但是在图中我们并不能看到这一现象。35人死亡的事故次数甚至还高于33和34人的次数。因此,35人这个事故死亡人数分界点,是不存在的。
如果35人真的是一个分界点且在这个分界点附近的死亡瞒报现象真的存在,那么我们应当能看到报告死亡人数在33、34人的事故次数畸高(死亡35人及以上但被人为调整至35人以下,且不能调整幅度太大),而报告死亡35人的事故次数迅速下降。但是在图中我们并不能看到这一现象。35人死亡的事故次数甚至还高于33和34人的次数。因此,35人这个事故死亡人数分界点,是不存在的。
不过,虽然在35这个值上不存在分界点,在其他值上就不一定了。按照p值研究的方法,我们可以画一张类似的图: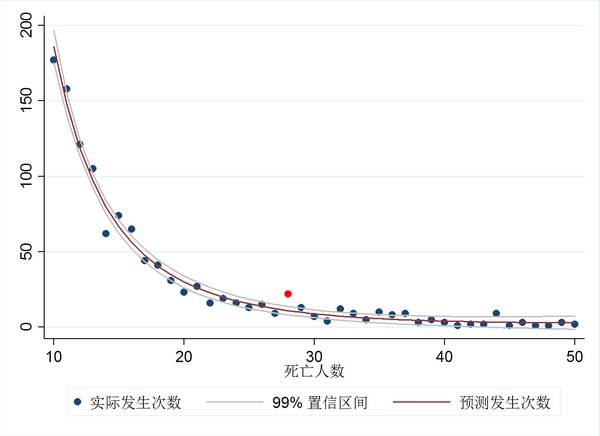 上图中的横轴为死亡人数,纵轴为事故次数,99%置信区间的拟合线公式为“预测次数=252746*死亡人数^(-3.037)”,是一个典型的幂律分布。可以看到,唯一一个实际事故次数大幅超过了预测事故次数99%置信区间上限死亡人数发生在28人。大幅度越过99%而非95%这个置信区间,可以说是非常少见的现象,这意味着在该模型成立的情况下此情形出现的概率远小于1%。仔细检查数据的话,死亡28人的事故有22次(模型预测10.2次),29人事故13次(模型预测9.1次),30人和31人迅速下降到7次和4次。
上图中的横轴为死亡人数,纵轴为事故次数,99%置信区间的拟合线公式为“预测次数=252746*死亡人数^(-3.037)”,是一个典型的幂律分布。可以看到,唯一一个实际事故次数大幅超过了预测事故次数99%置信区间上限死亡人数发生在28人。大幅度越过99%而非95%这个置信区间,可以说是非常少见的现象,这意味着在该模型成立的情况下此情形出现的概率远小于1%。仔细检查数据的话,死亡28人的事故有22次(模型预测10.2次),29人事故13次(模型预测9.1次),30人和31人迅速下降到7次和4次。
接下来,我们将所有事故里的交通事故专门拿出来做一张类似的图。交通事故和生产安全事故尤其是煤矿的安全事故不同,后者的死亡发生在作业井下,因此统计人数往往不如前者那么容易被观察到。相比于安全事故,交通事故的死亡数字修改会更加困难。
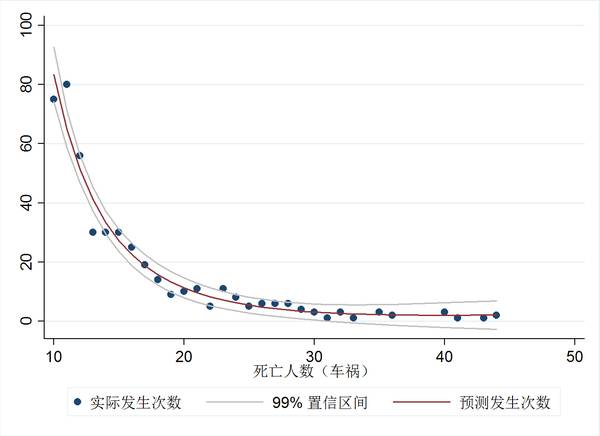 上图显示,如果只把车祸拿出来,那么28、29人死亡事故的发生次数就显著下降了,几乎所有点落在了99%置信区间内。换句话说,28人死亡事故的高频率,是由生产事故频率上升导致的。对于死亡人数更不容易被修改的交通事故,28人死亡的事故频率相对于其他死亡人数的事故频率并没有上升。
上图显示,如果只把车祸拿出来,那么28、29人死亡事故的发生次数就显著下降了,几乎所有点落在了99%置信区间内。换句话说,28人死亡事故的高频率,是由生产事故频率上升导致的。对于死亡人数更不容易被修改的交通事故,28人死亡的事故频率相对于其他死亡人数的事故频率并没有上升。
是什么导致了这种现象呢?
以下为无关引用,仅供参考。
国务院《生产安全事故报告和调查处理条例》(2007年6月1日施行)第三条规定:“根据生产安全事故造成的人员伤亡或者直接经济损失,事故一般分为以下等级:特别重大事故、重大事故、较大事故和一般事故。
特别重大事故,是指造成30人(包括30人)以上死亡。
— THE END —
