
MySQL主从数据不一致,怎么办?
先给大家说个身边的故事。
小伙伴二狗最近面宇宙厂,前面被问MySQL索引、锁、主从复制原理时答的都很开心。
当面试官问到 :“你们遇到主从不一致的问题怎么解决呢?你有什么更好的方案吗?”
二狗懵了。不就是读写时候走主,纯读走从吗。。难道还有什么别的办法?
面试官:emmm……有。那我们换个问题,主从复制的方式有几种,你能讲讲吗?
二狗:…… 问到盲点了
面试官:答不上来没关系,您的情况我基本了解了。感谢您参加本次面试,后续结果HR会联系你。
如果你也有类似上述疑惑,那么这篇文章拿好了!
主从数据不一致问题
先介绍下问题产生的背景。
在MySQL 一主多从的架构中,主要有两种,一种是通过客户端直连,一种是通过代理 prxoy 间接连接。
客户端直连模式下一般会把数据库的连接信息放在客户端的连接层,客户端做负载均衡,由客户端来选择后端数据库进行查询。通过代理的模式下 MySQL 和客户端之间有一个中间代理层 proxy,客户端直连接 proxy, 由 proxy 根据请求类型和上下文决定请求的分发路由。
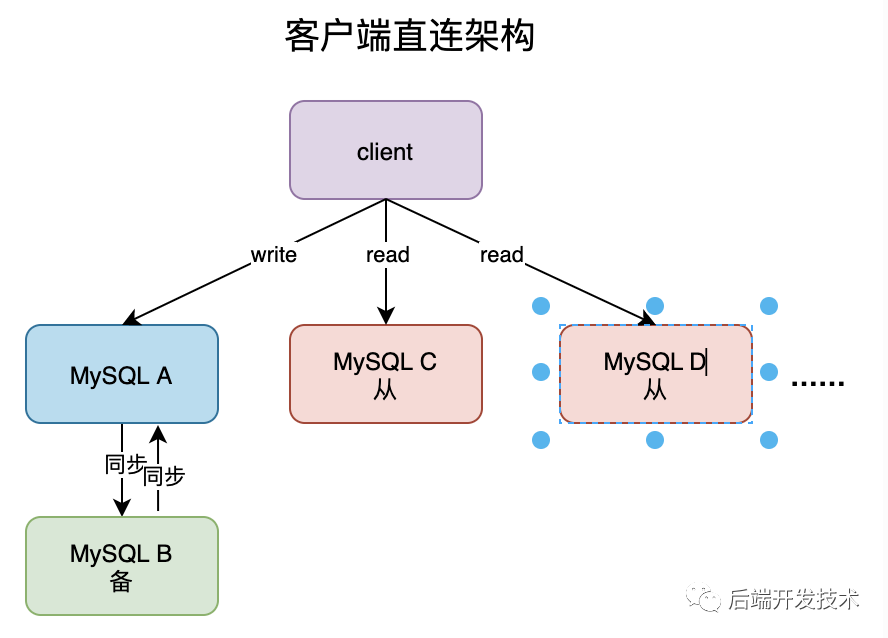
客户端直连和带 proxy 的读写分离架构,各有哪些特点。
客户端直连方案,整体架构简单,排查问题方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,处理起来比较麻烦,对开发人员要求高。 直连 proxy 的架构,对客户端比较友好。客户端不需要关注后端细节,但是 proxy 也需要有高可用架构,架构更复杂,对运维团队要求更高。
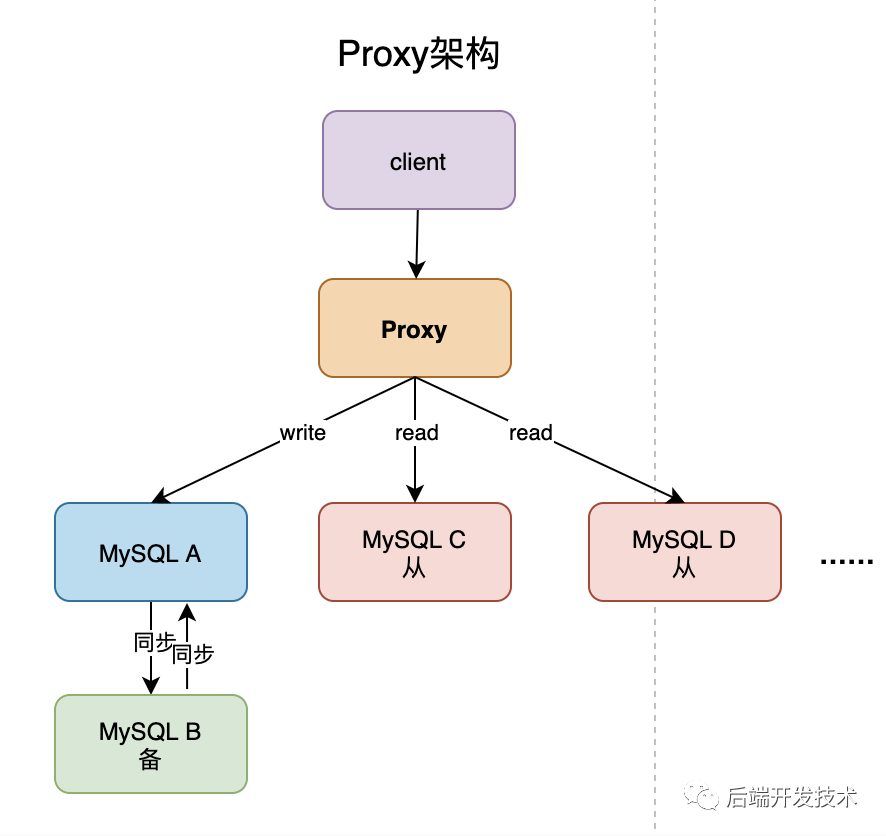
目前趋势是直连 proxy 的方向发展,具体取舍取决于自身情况。
带来的问题
无论哪种架构,都会遇到主从数据不一致的问题:由于主从同步可能存在延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就有可能读到刚刚的事务更新之前的状态。如何解决呢?
在进行读写分离的同时,解决主从同步中数据不一致的问题,主要有几种思路,一是从业务层面解决,二是从检测主从同步的差异上解决,三也是最根本的方式——从主从之间数据复制方式解决。按照这三种指导思想,我总结了一下有以下几种方案。
全部走主库方案
先说一种最为广泛使用的方案,也就是二狗的回答。
如果是在同一数据库中对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。所以我们可以根据业务场景来做区分。如果是需要写完之后必须读区到准确数据的场景,可以直接全部走主库,比如订单支付、金融业务等强一致性场景;如果业务允许读到旧数据,可以在读的时候查询从库。
这样的话你可能觉得并没有真正解决主从不一致的问题,但其实在实际生产中,大多数情况下都这么解决的。优点是简单成本低,不需要复杂架构。缺点也很明显,如果业务一致性要求很高,很多读都会在主库进行,并没有真正的读写分离减轻主库压力,读写分离成了摆设。
延迟查询方案
比如主库更新一条数据以后,查询从库数据的时候后端接口可以线sleep一段时间,比如绝大多数主从同步都可以在1s内完成,那就可以sleep一秒钟的时间。或者也可以延迟查询逻辑放在前端,比如订单支付完成后,可以前端延迟一秒再发起Ajax请求。
缺点是并不能数据保证完全准确,如果数据同步延迟大于一秒则主从依旧不一致;另一个是造成接口响应时间变长,甚至造成服务的吞吐量降低,对于不需要等待1s的场景,也必须等待够1s。
判断主备无延迟方案
在构建MySQL主从架构的文章里提过一些关于主从搭建以及状态查看的具体操作,具体请看下面这篇文章👇

快速入门Mycat及主从搭建指南
后文将要提到的关于判断主备延迟的关键参数便是从 status 的结果中获得的。
1.判断 Seconds_Behind_Master
通过 show slave status 可以拿到 Seconds_Behind_Master 的值,表示主备延迟的时间长短。判断 Seconds_Behind_Master 是否为 0,如果不等于0,就等到这个参数为0时再执行查询。但是这个延迟时间的单位为秒,所以可能产生一秒内的误差。

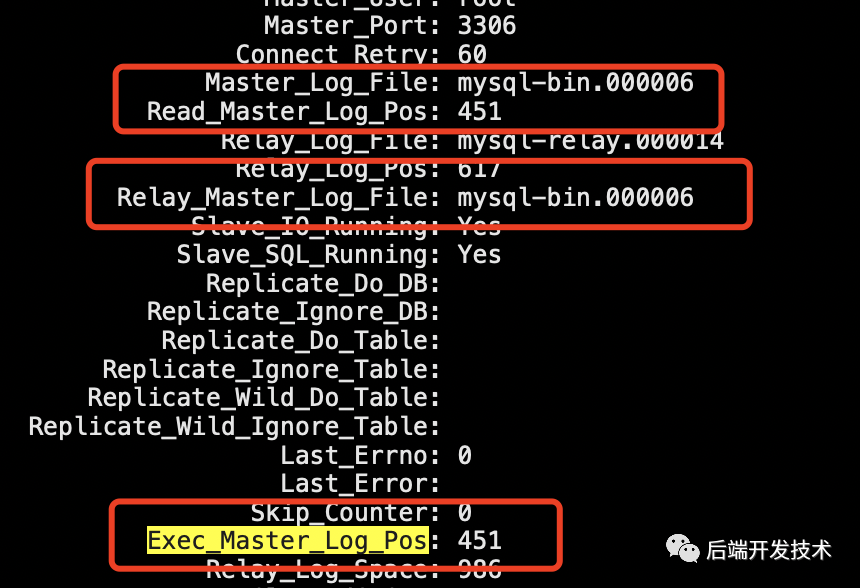
2.判断同步binlog 位置
在同步时通过文件名+文件位置就可以定位到binlog文件正在同步的位置。Master_Log_File 和 Read_Master_Log_Pos,表示的是读到的主库的最新位点;Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是备库执行的最新位点。
3.判断GTID相同
GITD在全局唯一,并且可以动过GTID来定位binlog位置,所以也可以用来判断主备是否有延迟
什么是GTID?
GTID特性是5.6加入的一个强大的特性,全称是Global Transaction Identifier。MySQL会为每一个DML/DDL操作增加一个唯一标记叫做GTID,这个标记在整个复制环境中都是唯一的。主从环境中主库的DUMP线程可以直接通过GTID定位到需要发送的binary log位置,而不再需要指定binary log的文件名和位置,因此切换极为方便。关于DUMP线程是如何通过GTID定位到binary log位置的,我们将在第17节进行讨论。
Auto_Position=1 ,表示这对主备关系使用了 GTID 协议。Retrieved_Gtid_Set,是备库收到的所有日志的 GTID 集合;Executed_Gtid_Set,是备库所有已经执行完成的 GTID 集合。对比这两个集合对应的GTID相同就表示主备之间无延迟。
但是需要说明的是,这里的无延迟,指的其实是从库收到主库的数据已经全部执行结束。但可能有种情况,客户端已经收到数据,而对应的binlog并没有收到,这种情况下从库是不知道的。
如何解决这个问题呢?
我们现在的困境是不知道主库到底有没有新执行的数据,从库有没有把最新binlog收到并且执行,那如果主库执行完SQL我就拿到最新binlog位点呢?还有另一种思路,之所以产生这种情况,是因为5.7版本mysql默认采用了异步复制的方式。如果想要数据更精确,就有必要在复制方式上做出改变。
对于这两种思路又产生了后面几种解决方案。
从库等指定位点或GTID方案
对于前面提到的思路,刚好MySQL有这样一个命令。
select master_pos_wait(file, pos[, timeout]);
这条命令是在从库执行的,参数 file 和 pos 指的是主库上的文件名和位置,timeout 可选,设置为正整数 N 表示这个函数最多等待 N 秒。这个命令正常返回的结果是一个正整数 M,表示从命令开始执行,到应用完 file 和 pos 表示的 binlog 位置,执行了多少事务。
这样就产生了一个方案。
主库事务更新完成后,马上执行 show master status 得到当前主库执行到的 File 和 Position。 选定一个从库执行查询语句。 在从库上执行 select master_pos_wait(File, Position, 1)。 如果返回值是 >=0 的正整数,则在这个从库执行查询语句,否则,到主库执行查询语句。
同样的对于判断位点,可有一套判断GTID的方案。
select wait_for_executed_gtid_set(gtid_set, 1);
逻辑与前者相同,只需要等待GTID到指定数字即可,这里大家举一反三,不做赘述。
复制方式
下面就开始介绍关于复制方式方面的思路,从这些复制方式中,你会找到关于解决主备延迟问题的更优思路。先介绍一下异步复制模式。
异步复制
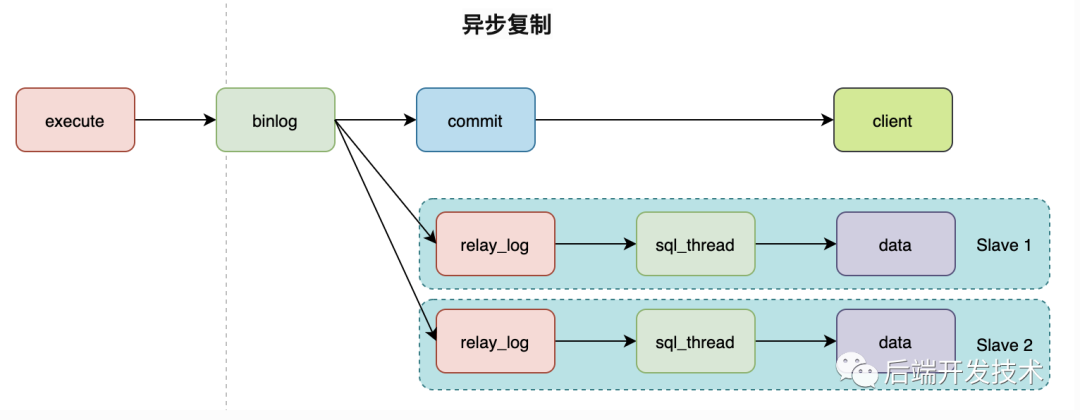
异步模式就是客户端提交 COMMIT 之后不需要等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而 Binlog 还没有同步到从库的情况,也就是此时的主库和从库数据不一致。这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,这种复制模式下的数据一致性是最弱的。
默认情况下,MySQL就是异步复制的模式。
半同步复制(增强半同步复制)
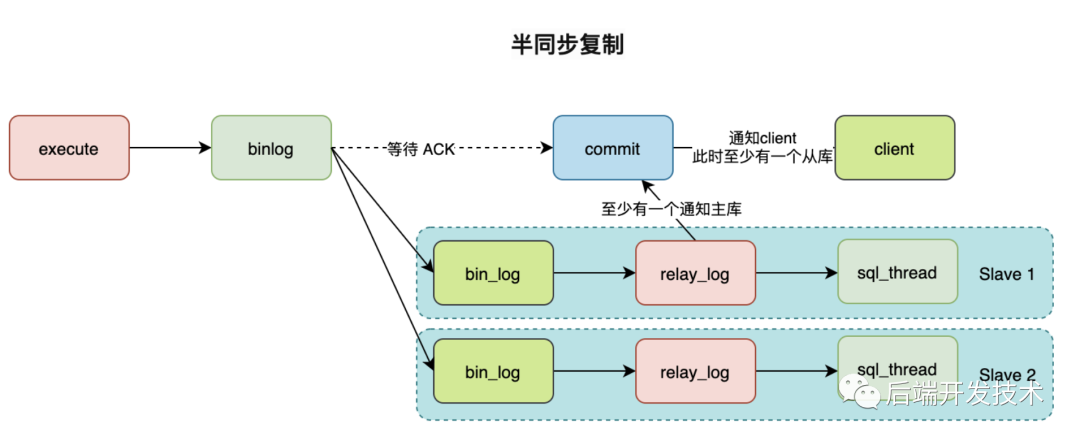
在MySQL5.5中加入了半同步复制(semisynchronous replication),主库上的事务在存储引擎层提交之后,需要等待从库返回ACK信号。并且在接收到从库返回ACK信号或者等待超时才会返回给客户端一个提交结果。但是这样会造成其他会话可以读取到这些记录,因为此时事务已经提交,这就造成了幻读。
在MySQL5.7中进一步对半同步复制做了增强,将等待从库返回ACK信号的时间点提前了,新特性中主库上的事务会在存储引擎层提交之前一直等待从库返回ACK信号。这就意味着,在主库crash的情况下,所有在主库上已经提交的事务已经被复制到至少一个从库上,这就解决了幻读的问题,数据的一致性获得了极大提升。
但是缺点也很明显,会造成同步过程多了一次网络连接,降低主库的写吞吐量。在 MySQL5.7 版本中还增加了rpl_semi_sync_master_wait_for_slave_count参数 ,可以对从库的应答数量进行设置,默认为 1,也就是说只要有 1 个从库进行了响应,就可以返回给客户端。在1主1从情况下,这接近同步复制,如果使用semi-sync+位点判断方案,这样我们前面提到的主从数据不一致问题引刃而解,但是如果多从还是有可能出现不一致的情况。
MGR 组复制
MySQL在5.7.17 版本中引入了组复制技术,简称 MGR(MySQL Group Replication),这种复制技术是基于 分布式一致性协议Paxos 协议的,实现了分布式下数据的最终一致性。
A transaction received by Source 1 is executed. Source 1 then sends a message to the replication group, consisting of itself, Source 2, and Source 3. When all three members have reached consensus, they certify the transaction. Source 1 then writes the transaction to its binary log, commits it, and sends a response to the client application. Sources 2 and 3 write the transaction to their relay logs, then apply it, write it to the binary log, and commit it.

MGR 由若干个节点共同组成一个复制组,一个写事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。如上图所示,由3个节点组成一个复制组,Consensus层为一致性协议层,在事务提交过程中,发生组间通讯,由2个节点决议(certify)通过这个事务,事务才能够最终得以提交并响应,其实就是过半投票。
而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。虽然半同步复制部分解决了一致性问题,但只能在简单架构下比如一主一从,MGR才真正解决了这个问题,并且MGR可以在多主的复杂情况下有效保证数据的一致性。
总结
总结一下,解决主从复制延迟一共可以有如下7种思路:
读写走主库方案 延迟查询方案 判断主备无延迟方案 判断同步位点方案 等待同步位点方案 半同步复制方案+等待位点 组复制MGR方案