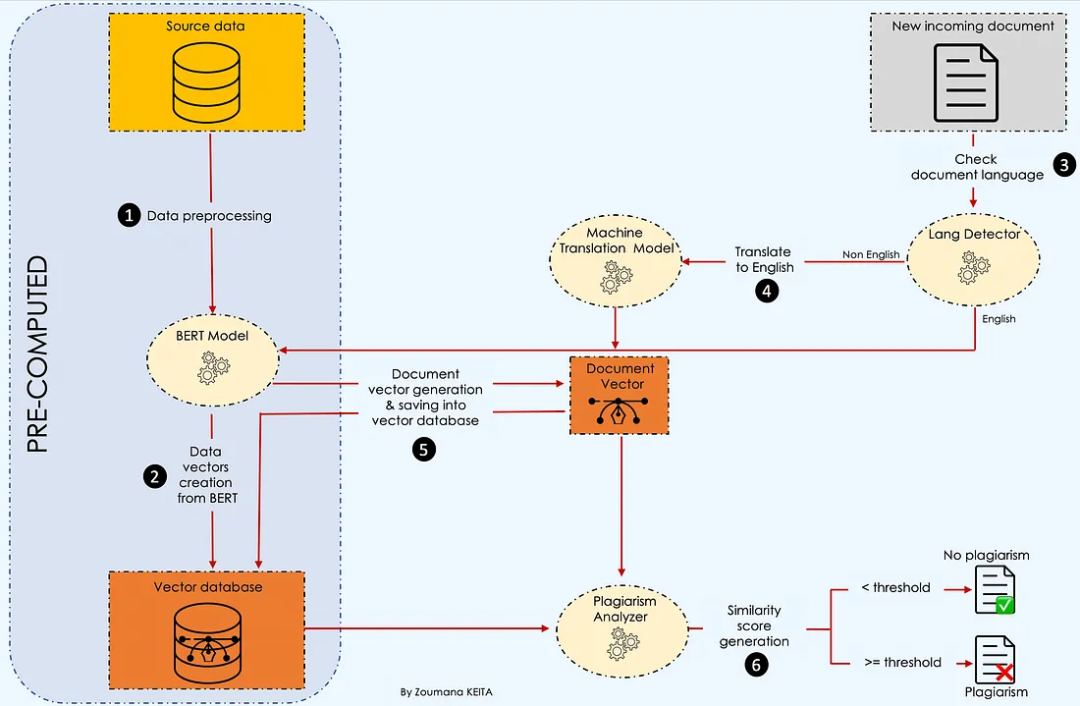
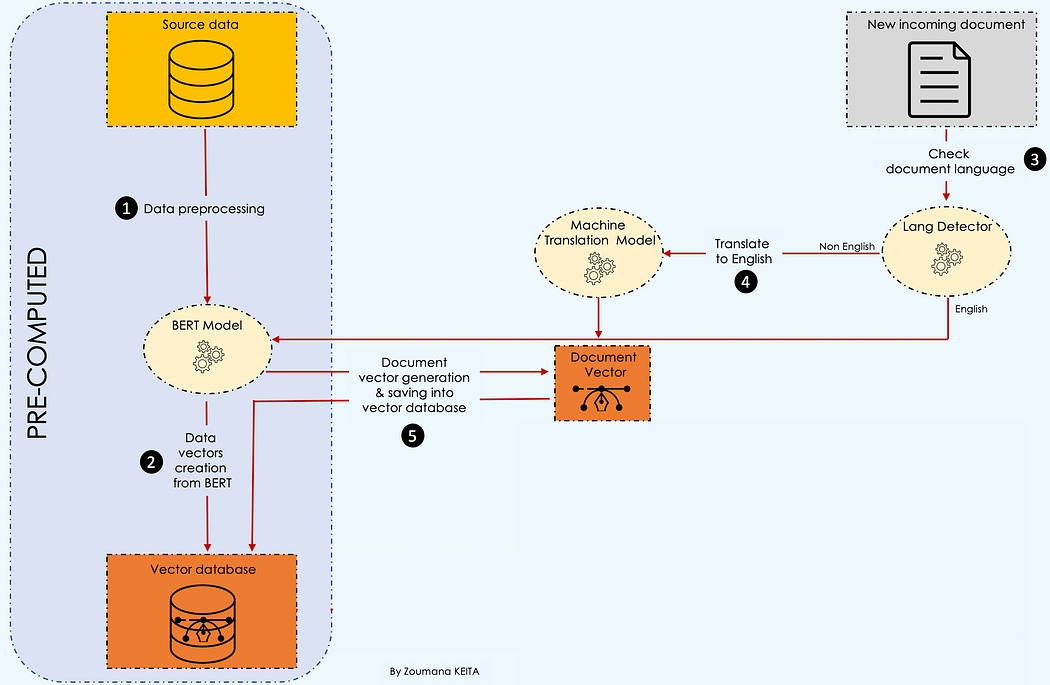
假设你有兴趣构建一个学术内容管理平台。你可能希望只接受在你的平台上没有共享过的文章。在这种情况下,你的目标将是拒绝所有与现有文章相似度超过某个阈值的新文章。为了说明这种情况,我们将使用cord-19数据集,这是由Allen Institute for AI在Kaggle上免费提供的开放研究挑战数据集。https://allenai.org/
import pandas as pd defpreprocess_data(data_path, sample_size): # Read the data from specific path data = pd.read_csv(data_path, low_memory=False) # Drop articles without Abstract data = data.dropna(subset = ['abstract']).reset_index(drop = True) # Get "sample_size" random articles data = data.sample(sample_size)[['abstract']] return data # Read data & preprocess itdata_path = "./data/cord19_source_data.csv"source_data = preprocess_data(data_path, 100)
# Useful librariesimport numpy as npimport torchfrom keras.preprocessing.sequence import pad_sequencesfrom transformers import BertTokenizer, AutoModelForSequenceClassification # Load bert modelmodel_path = "bert-base-uncased" tokenizer = BertTokenizer.from_pretrained(model_path, do_lower_case=True) model = AutoModelForSequenceClassification.from_pretrained(model_path, output_attentions=False, output_hidden_states=True) defcreate_vector_from_text(tokenizer, model, text, MAX_LEN = 510): input_ids = tokenizer.encode( text, add_special_tokens = True, max_length = MAX_LEN, ) results = pad_sequences([input_ids], maxlen=MAX_LEN, dtype="long", truncating="post", padding="post") # Remove the outer list. input_ids = results[0] # Create attention masks attention_mask = [int(i>0) for i in input_ids] # Convert to tensors. input_ids = torch.tensor(input_ids) attention_mask = torch.tensor(attention_mask) # Add an extra dimension for the "batch" (even though there is only one # input in this batch.) input_ids = input_ids.unsqueeze(0) attention_mask = attention_mask.unsqueeze(0) # Put the model in "evaluation" mode, meaning feed-forward operation. model.eval() # Run the text through BERT, and collect all of the hidden states produced# from all 12 layers. with torch.no_grad(): logits, encoded_layers = model( input_ids = input_ids, token_type_ids = None, attention_mask = attention_mask, return_dict=False) layer_i = 12# The last BERT layer before the classifier. batch_i = 0# Only one input in the batch. token_i = 0# The first token, corresponding to [CLS] # Extract the vector. vector = encoded_layers[layer_i][batch_i][token_i] # Move to the CPU and convert to numpy ndarray. vector = vector.detach().cpu().numpy() return(vector) defcreate_vector_database(data): # The list of all the vectors vectors = [] # Get overall text data source_data = data.abstract.values # Loop over all the comment and get the embeddingsfor text in tqdm(source_data): # Get the embedding vector = create_vector_from_text(tokenizer, model, text) #add it to the list vectors.append(vector) data["vectors"] = vectors data["vectors"] = data["vectors"].apply(lambda emb: np.array(emb)) data["vectors"] = data["vectors"].apply(lambda emb: emb.reshape(1, -1)) return data # Create the vector database vector_database = create_vector_database(source_data)vector_database.sample(5)
from langdetect import detect, DetectorFactoryDetectorFactory.seed = 0 deftranslate_text(text, text_lang, target_lang='en'): # Get the name of the model model_name = f"Helsinki-NLP/opus-mt-{text_lang}-{target_lang}" # Get the tokenizer tokenizer = MarianTokenizer.from_pretrained(model_name) # Instantiate the model model = MarianMTModel.from_pretrained(model_name) # Translation of the text formated_text = ">>{}<< {}".format(text_lang, text) translation = model.generate(**tokenizer([formated_text], return_tensors="pt", padding=True)) translated_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translation][0] return translated_text
english_article_to_check = "The need for multidisciplinary research to address today's complex health and environmental challenges has never been greater. The One Health (OH) approach to research ensures that human, animal, and environmental health questions are evaluated in an integrated and holistic manner to provide a more comprehensive understanding of the problem and potential solutions than would be possible with siloed approaches. However, the OH approach is complex, and there is limited guidance available for investigators regarding the practical design and implementation of OH research. In this paper we provide a framework to guide researchers through conceptualizing and planning an OH study. We discuss key steps in designing an OH study, including conceptualization of hypotheses and study aims, identification of collaborators for a multi-disciplinary research team, study design options, data sources and collection methods, and analytical methods. We illustrate these concepts through the presentation of a case study of health impacts associated with land application of biosolids. Finally, we discuss opportunities for applying an OH approach to identify solutions tocurrentglobal health issues, and the need forcross-disciplinary funding sources to foster an OH approach to research."
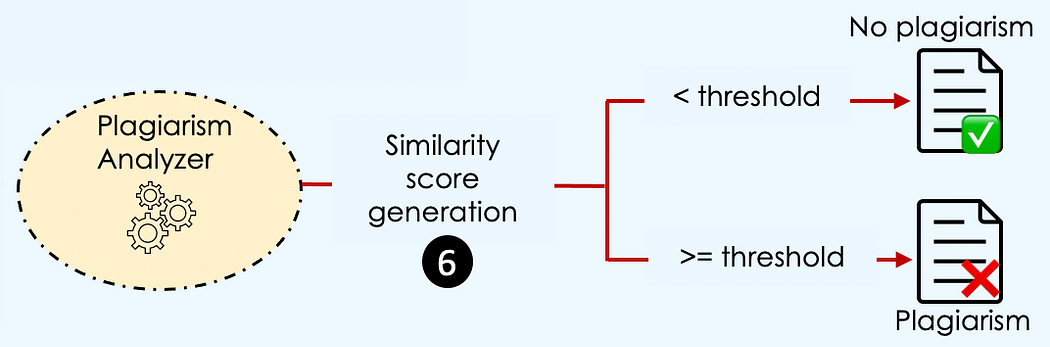
# Select an existing article from the databasenew_incoming_text = source_data.iloc[0]['abstract'] # Run the plagiarism detectionanalysis_result = run_plagiarism_analysis(new_incoming_text, vector_database, plagiarism_threshold=0.8)
french_article_to_check = """Les Réseaux d’Innovation et de Transfert Agricole (RITA) ont été créés en 2011 pour mieux connecter la recherche et le développement agricole, intra et inter-DOM, avec un objectif d’accompagnement de la diversification des productions locales. Le CGAAER a été chargé d'analyser ce dispositif et de proposer des pistes d'action pour améliorer la chaine Recherche – Formation – Innovation – Développement – Transfert dans les outre-mer dans un contexte d'agriculture durable, au profit de l'accroissement de l'autonomie alimentaire."""
german_article_to_check = """Derzeit ist eine Reihe strukturell und funktionell unterschiedlicher temperaturempfindlicher Elemente wie RNA-Thermometer bekannt, die eine Vielzahl biologischer Prozesse in Bakterien, einschließlich der Virulenz, steuern. Auf der Grundlage einer Computer- und thermodynamischen Analyse der vollständig sequenzierten Genome von 25 Salmonella enterica-Isolaten wurden ein Algorithmus und Kriterien für die Suche nach potenziellen RNA-Thermometern entwickelt. Er wird es ermöglichen, die Suche nach potentiellen Riboschaltern im Genom anderer gesellschaftlich wichtiger Krankheitserreger durchzuführen. Für S. enterica wurden neben dem bekannten 4U-RNA-Thermometer vier Hairpin-Loop-Strukturen identifiziert, die wahrscheinlich als weitere RNA-Thermometer fungieren. Sie erfüllen die notwendigen und hinreichenden Bedingungen für die Bildung von RNA-Thermometern und sind hochkonservative nichtkanonische Strukturen, da diese hochkonservativen Strukturen im Genom aller 25 Isolate von S. enterica gefunden wurden. Die Hairpins, die eine kreuzförmige Struktur in der supergewickelten pUC8-DNA bilden, wurden mit Hilfe der Rasterkraftmikroskopie sichtbar gemacht."""