
如何对txt文本中的不规则行进行数据分列
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python交流白银群【空翼】问了一道Pandas数据处理的问题,如下图所示。
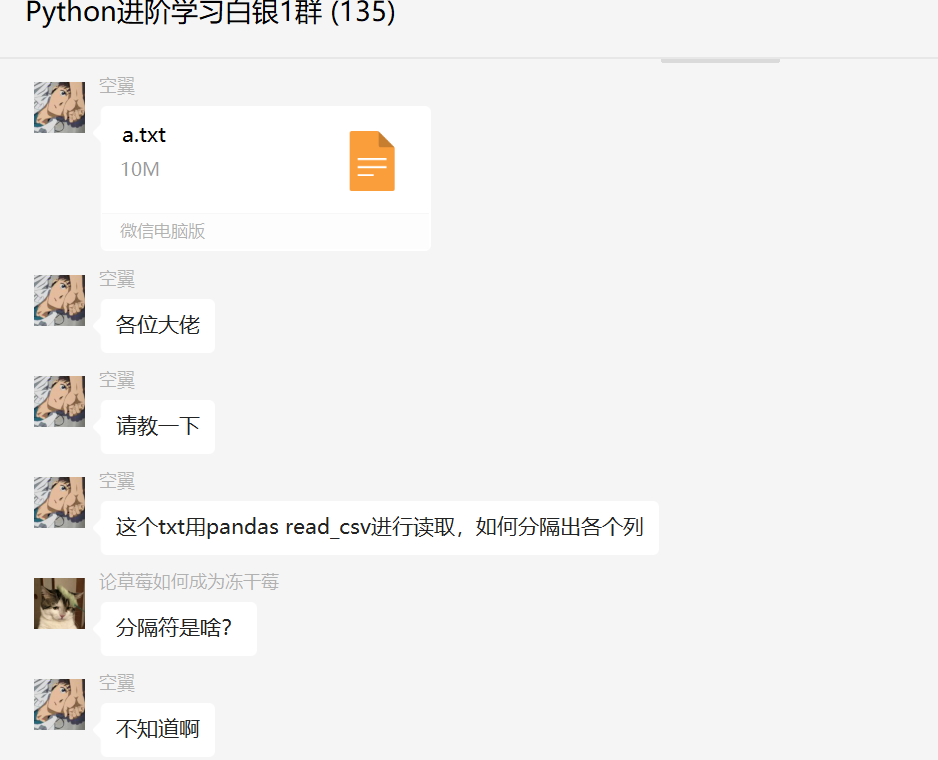
文本文件中的数据格式如下图所示:
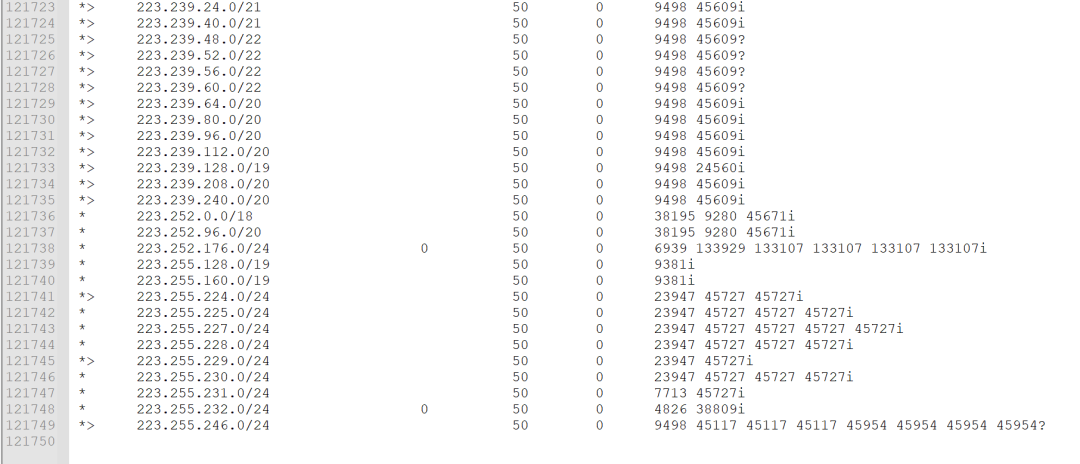
里边有12万多条数据。
二、实现过程
这个问题还是稍微有些挑战性的,这里【瑜亮老师】给了一个解答,思路确实非常不错。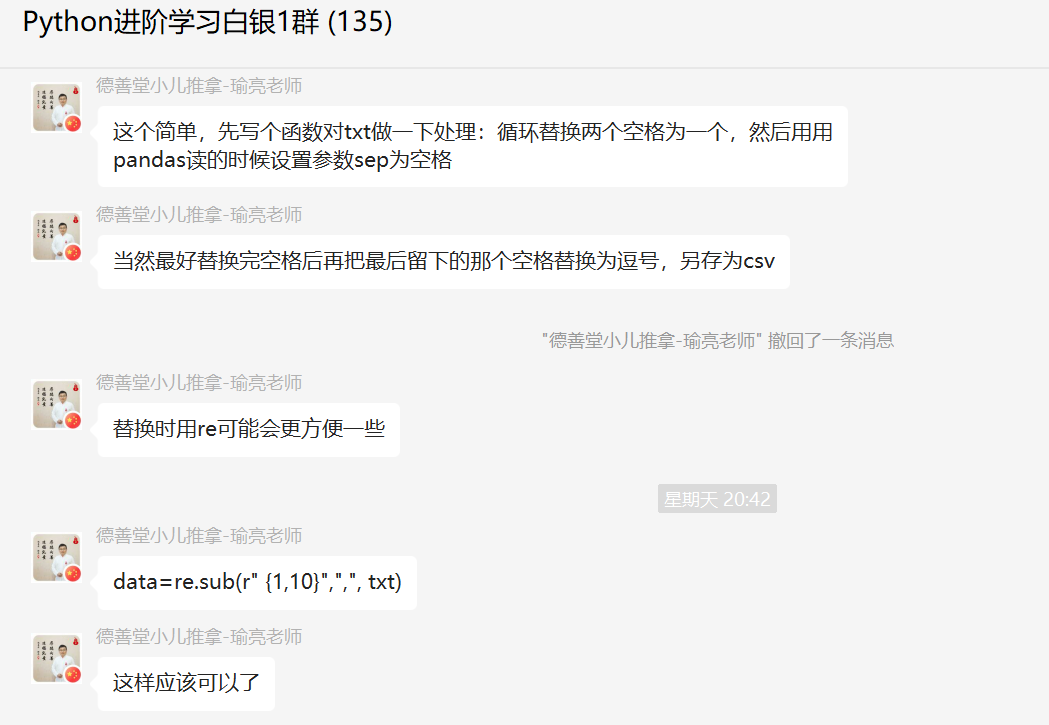
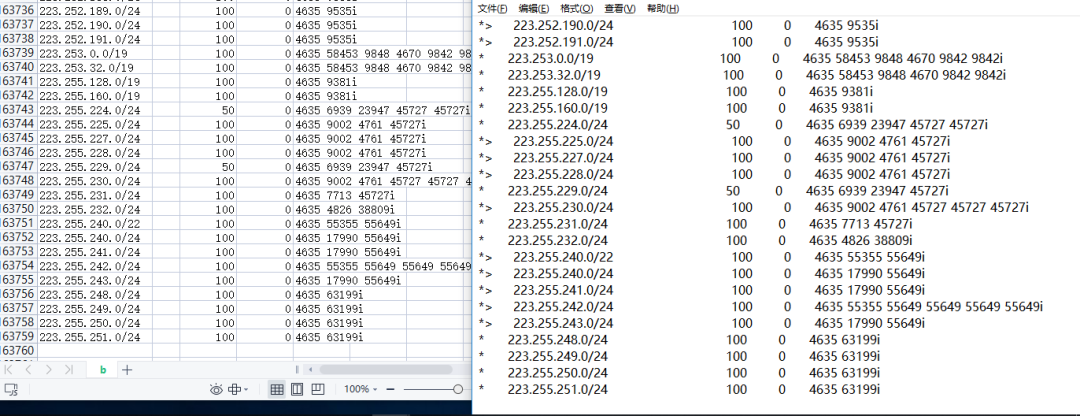
后来【flag != flag】给了一个清晰后的数据,如图所示。
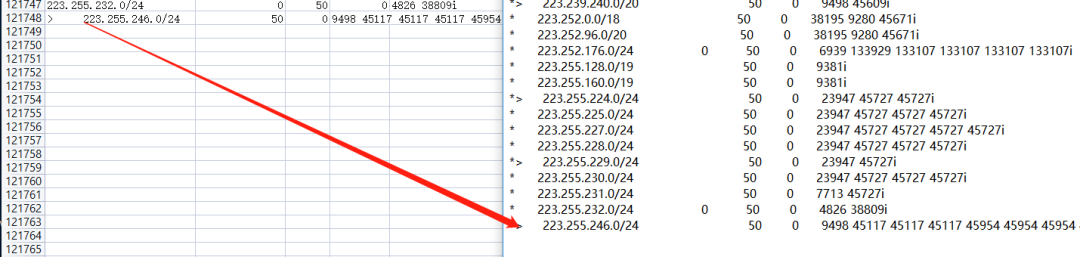
看上去清晰很多了,剩下的交给粉丝自己去处理了。
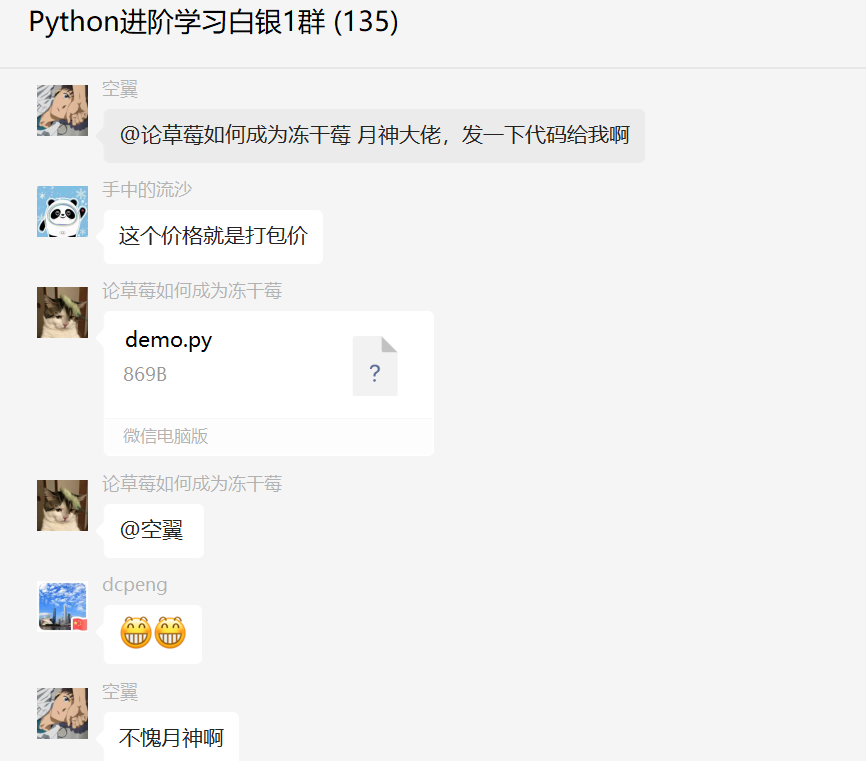
后来【月神】给了一个代码,直接拿下了这个有偿的需求。代码如下所示:
import pandas as pd
def read_csv(path):
df = pd.read_csv(path, header=1)
pattern = r'(\d+\.\d+\.\d+\.\d+/\d+)\s\s+(\d+)?\s\s+(\d+)\s\s+(\d+)\s\s+([\d\S ]+)'
values = df.iloc[:, 0].str.extract(pattern).values
columns = df.columns.str.strip().str.split('\s+')[0]
return pd.DataFrame(values, columns=columns)
def get_lower_prf(df1, df2):
pass # 付费的代码内容,这里摘除了,嘻嘻
path_A = r"Route_A.txt"
path_B = r"Route_B.txt"
dfA = read_csv(path_A)
dfB = read_csv(path_B)
data = get_lower_prf(dfA, dfB)
data.to_csv('result.txt', '\t', index=False)
运行之后的结果如下所示:
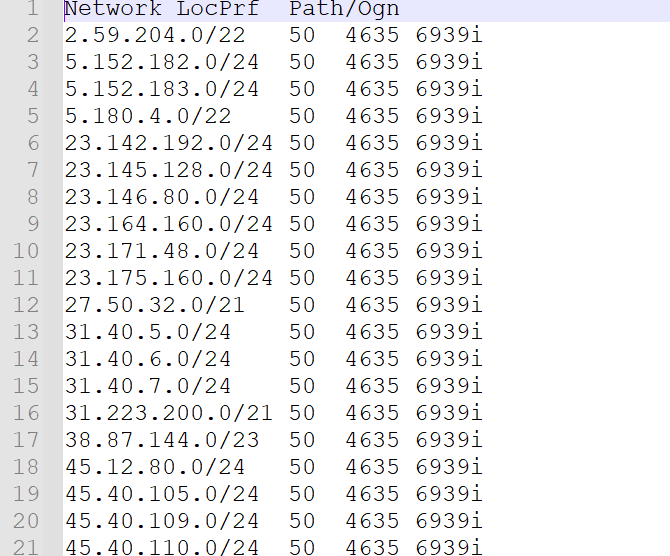
顺利解决粉丝的问题。
如果有遇到问题,随时联系我解决,欢迎加入我的Python学习交流群。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道Python函数处理的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空翼】提问,感谢【瑜亮老师】、【手中的流沙】、【月神】、【flag != flag】给出的思路和代码解析,感谢【此类生物】、【dcpeng】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论