AI模型性能上不去?这真的不怪我,ImageNet等数据集每100个标签就错3个!
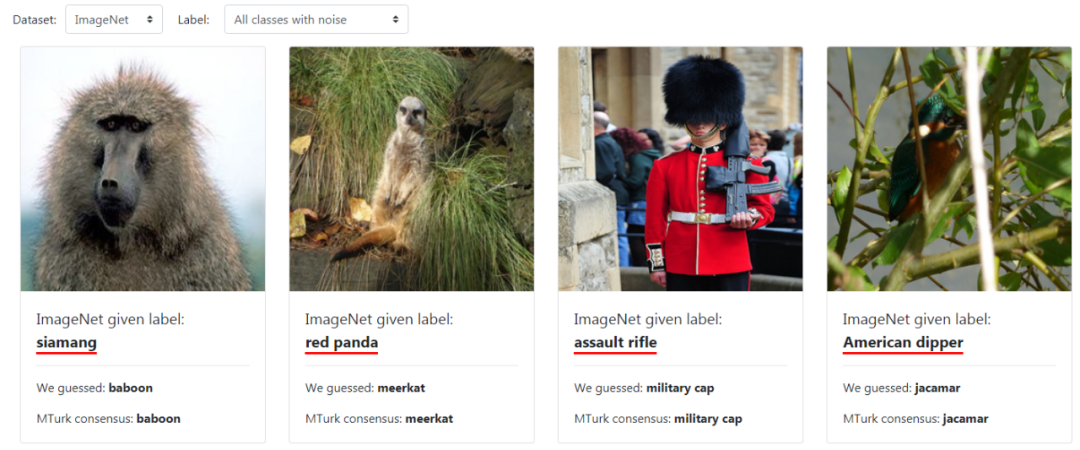
标签错误会破坏基准的稳定性,然而,令人没想到的是,大多数机器学习中使用的10个主流基准测试集普遍存在标签错误。比如,把“狮子”标记成“猴子”,把“青蛙”标记成“猫”。众所周知,机器学习数据集的标记并不是完全正确的,但是目前还没有系统的研究来量化机器学习数据集是否存在大量错误。MIT和亚马逊的研究人员近期就尝试了这项研究。机器学习数据集包括训练数据集和测试数据集,在以往的研究中,我们主要关注训练数据是否存在系统误差,而忽视了被引用最多的测试数据集。这些测试集是我们用来衡量机器学习进展的基准。在这项研究中,MIT和亚马逊的研究人员通过算法识别验证了10个常用的测试集中确实存在普遍的标签错误,并进一步确定了它们如何影响ML基准的稳定性。这10个数据集包括:MNIST、CIFAR-10、CIFAR-100、Caltech-256、ImageNet、QuickDraw、20news、IMDB、Amazon、AudioSet,它们不仅涉及图像数据集,还包括了文本、音频数据集。比如AudioSet是音频数据集,20news、IMDB和Amazon是文本数据集。下图就展示了一些被错误标记的样本。比如在CIFAR-10中的一张“青蛙”的图片被标记成了“猫”。在这个网站里,可以通过选择数据集和特定类别来查看被错误标记的数据。网站中相当详尽地列出了所有他们找到的标签错误,可谓是像素级找茬了。
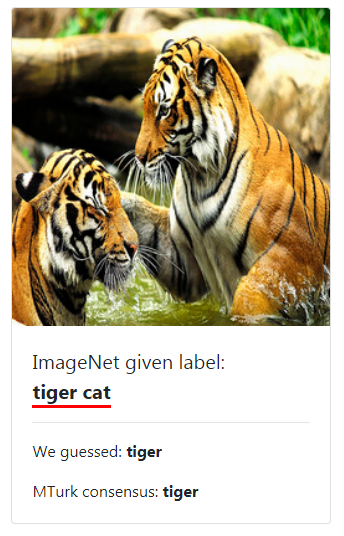
相关链接:https://labelerrors.com/比如,当选中ImageNet和Tiger Cat时,我们能看到ImageNet将老虎标记成了虎猫。研究人员将相关成果发表在论文“Pervasive Label Errors in Test Sets Destabilize ML Benchmarks”上,我们接下来简单介绍一下论文的主要内容。主要发现
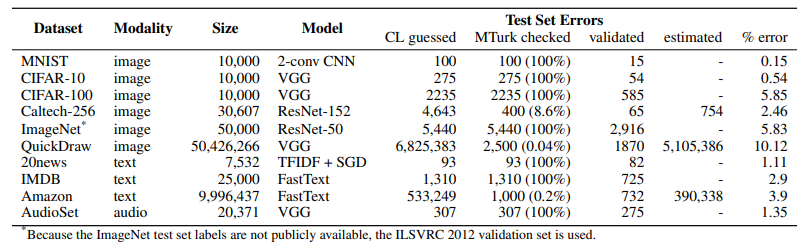
研究人员估计10个数据集的平均错误率为3.4%,例如2916个标签错误在ImageNet中占比6%;39万个标签错误在亚马逊评论中占比4%。此外,即使在MNIST数据集——已被成千上万的同行评审用于ML研究的基准测试,在其测试集中也包含了15个(人类验证的)标签错误。QuickDraw测试集的错误标签达到了500万个,约占整个测试集的10%。高容量/复杂模型(例如ResNet-50)在含错误标记的测试数据(即传统测量的数据)上表现良好,低容量模型(如ResNet-18)在手动更正标记的数据上有更好的表现。这可能是高容量模型在训练时过度拟合训练集的错误标签,或在调整测试集上的超参数时过度拟合测试集所导致的结果。(4)多少噪声会破坏ImageNet和CIFAR基准测试的稳定性?
在含有更正标签的ImageNet上:如果错误标记的示例仅占6%,那么ResNet-18的性能表现将优于ResNet-50。在含有更正标签的CIFAR-10上:如果错误标记的示例的占比为5%,那么VGG-11的性能表现优于VGG-19。传统意义上,ML从业者需要根据测试的准确性来选择部署模型。通过这项研究,研究者指出,在正确标记的测试集上判断模型可能更有用。因此,研究者提出了几个建议:研究方法
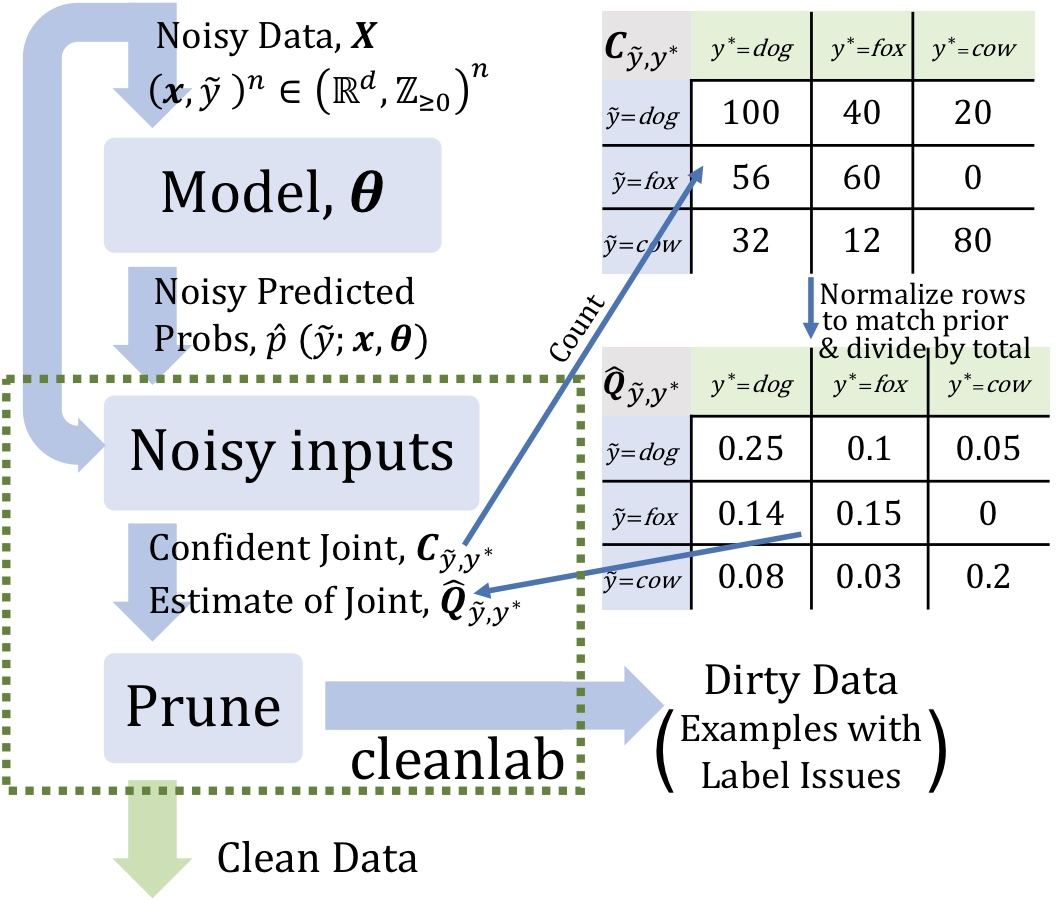
那么,这些错误是怎么被发现的呢?主要分为两个步骤,即算法识别和人工验证。在所有10个数据集中,研究人员首先通过置信学习算法进行初步识别标签错误(准确率可达54%),然后再通过众包的形式进行人工验证。需要说明的是,由于置信学习框架不与特定的数据模式或模型耦合,它支持在多种数据集中发现标签错误。置信学习(CL)已成为监督学习和弱监督中的一个子领域,用于:CL 基于噪声数据剪枝的原理,通过计数对噪声进行评估,并对实例进行排序以进行置信训练。- 估计给定噪声标签和潜在(未知)未损坏标签的联合分布,以充分描述类条件标签噪声
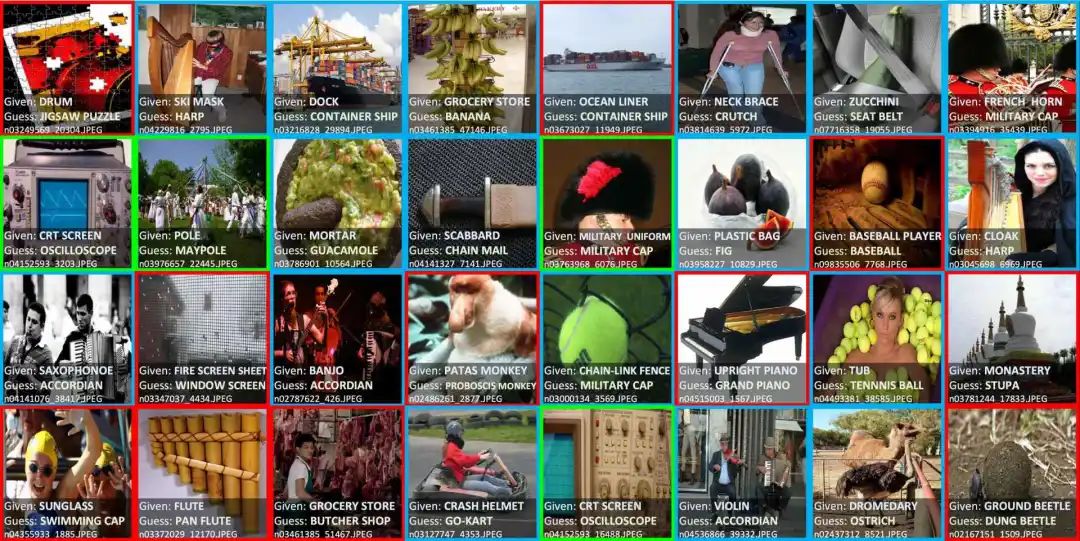
https://l7.curtisnorthcutt.com/confident-learning研究人员曾经用置信学习在2012 ILSVRC ImageNet训练集中发现的标签错误示例。- 本体论问题(绿色):包括“是”或 “有”两种关系,在这些情况下,数据集应该包含其中一类。
- 标签错误(红色):存在比给定类标签更适合某一示例的类标签。
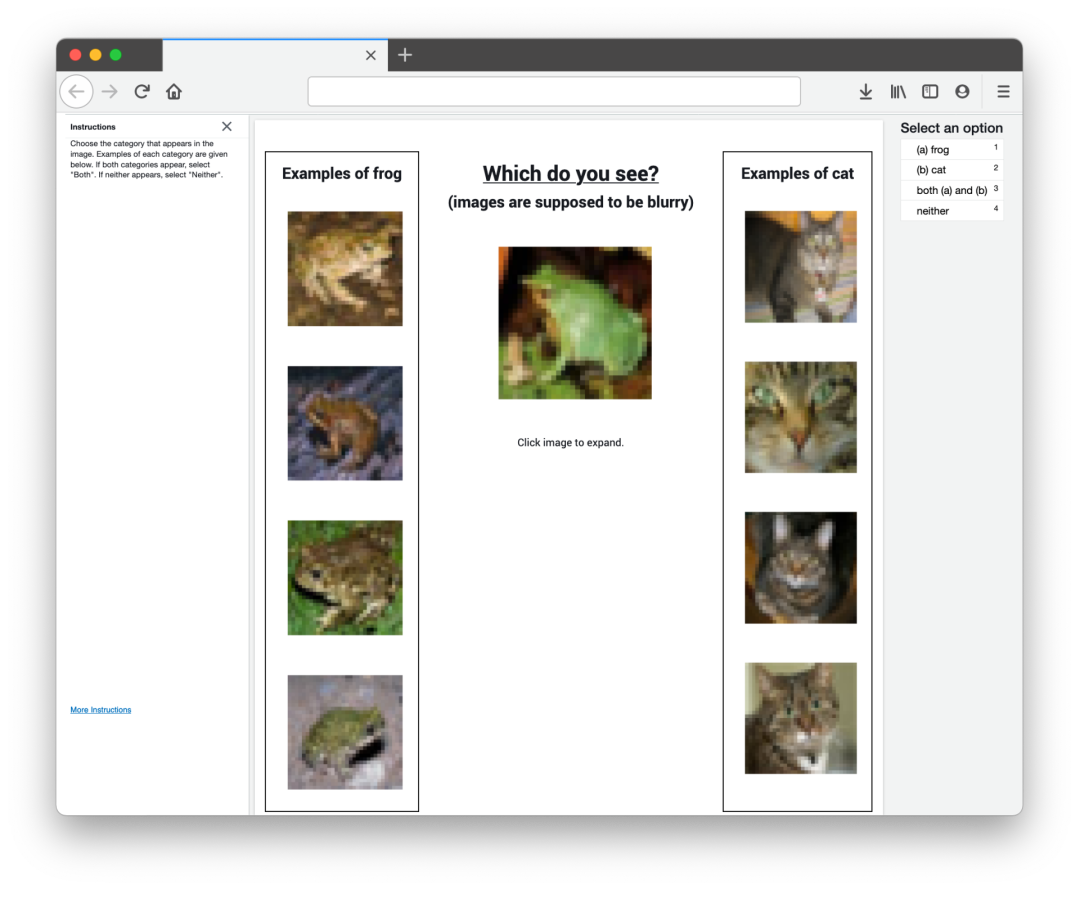
接下来是人工验证。研究人员基于算法识别的错误标签,进一步采用众包平台Mechanical Turk展开了研究。在三个(Caltech-256、QuickDraw和Amazon Reviews)含大量错误标签的数据集中,研究人员随机检查了部分样本(分别是8.6%、0.04%、0.02%),对其它数据集则对所有识别到的错误标签进行检查,如下表所示。(注意,由于ImageNet测试集不公开,所以这里使用的是ILSVRC 2012 ImageNet验证集)研究者向验证人员展示了这些错误标记的数据,并询问他们,这些数据的标记应该是:(1)给定标签,(2)CL预测标签,(3)上述两个标签都对,(4)两个标签都不对。
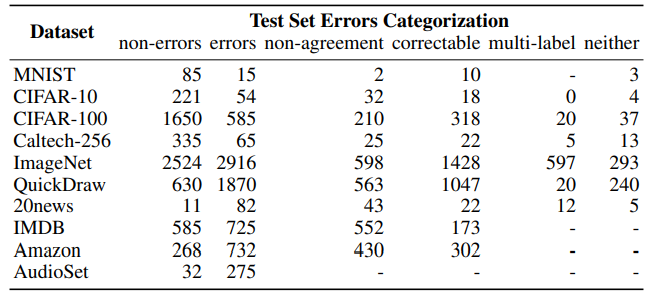
为了协助验证人员,验证的界面中还展示了原标签类别和CL预测类别的训练集示例,如下图所示。Mechanical Turk的工作界面显示了CIFAR-100的一个示例(图片带有给定错误标签“ cat”)。界面中会展示错误类别“cat”的训练集示例,以及CL预测类别“frog”的训练集示例。如下表所示,Mechanical Turk验证确认了普遍存在的标记错误,并对标签问题的类型进行了分类。这些修正是否全部都对呢?并不是。在某些案例中,验证人员也会同意错误的标签。由于研究人员只验证了一小部分数据集,所以检测到的错误标签可能也只是一小部分。https://github.com/cgnorthcutt/label-errors/tree/main/cleaned_test_sets研究人员表示,希望未来的基准测试能够使用这些改进的测试数据,而不是原来含有错误标签的数据集。- https://www.reddit.com/r/MachineLearning/comments/mfsn18/r_pervasive_label_errors_in_test_sets_destabilize/
- https://l7.curtisnorthcutt.com/label-errors
- https://l7.curtisnorthcutt.com/confident-learning

点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报