
Hudi 原理 | Apache Hudi 如何处理小文件问题
1. 引入
Apache Hudi是一个流行的开源的数据湖框架,Hudi提供的一个非常重要的特性是自动管理文件大小,而不用用户干预。大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进行太多次文件的打开/读取/关闭。在流式场景中不断摄取数据,如果不进行处理,会产生很多小文件。
2. 写入时 vs 写入后
一种常见的处理方法先写入很多小文件,然后再合并成大文件以解决由小文件引起的系统扩展性问题,但由于暴露太多小文件可能导致不能保证查询的SLA。实际上对于Hudi表,通过Hudi提供的Clustering功能可以非常轻松的做到这一点,更多细节可参考之前一篇文章查询时间降低60%!Apache Hudi数据布局黑科技了解下。
本篇文章将介绍Hudi的文件大小优化策略,即在写入时处理。Hudi会自管理文件大小,避免向查询引擎暴露小文件,其中自动处理文件大小起很大作用。
在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小(注意:bulk_insert操作暂无此特性,其主要用于替换spark.write.parquet方式将数据快速写入Hudi)。
3. 配置
我们使用COPY_ON_WRITE表来演示Hudi如何自动处理文件大小特性。
关键配置项如下:
•hoodie.parquet.max.file.size[1]:数据文件最大大小,Hudi将试着维护文件大小到该指定值;•hoodie.parquet.small.file.limit[2]:小于该大小的文件均被视为小文件;•hoodie.copyonwrite.insert.split.size[3]:单文件中插入记录条数,此值应与单个文件中的记录数匹配(可以根据最大文件大小和每个记录大小来确定)
例如如果你第一个配置值设置为120MB,第二个配置值设置为100MB,则任何大小小于100MB的文件都将被视为一个小文件,如果要关闭此功能,可将hoodie.parquet.small.file.limit配置值设置为0。
4. 示例
假设一个指定分区下数据文件布局如下
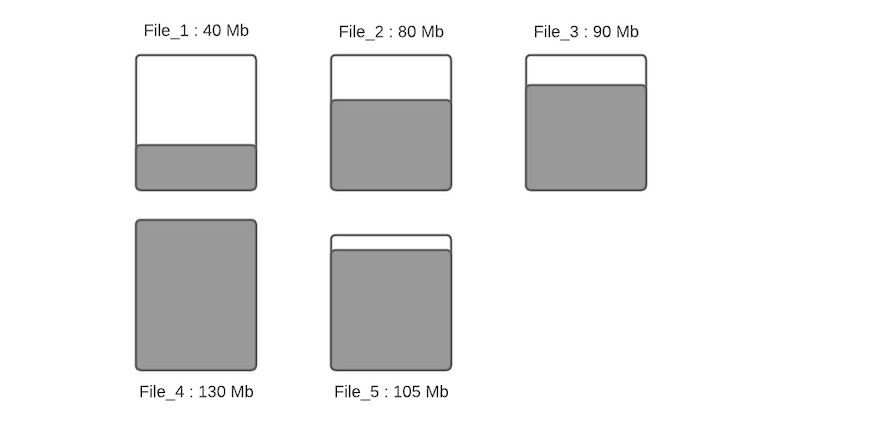
假设配置的hoodie.parquet.max.file.size为120MB,hoodie.parquet.small.file.limit为100MB。File_1大小为40MB,File_2大小为80MB,File_3是90MB,File_4是130MB,File_5是105MB,当有新写入时其流程如下:
步骤一:将更新分配到指定文件,这一步将查找索引来找到相应的文件,假设更新会增加文件的大小,会导致文件变大。当更新减小文件大小时(例如使许多字段无效),则随后的写入将文件将越来越小。
步骤二:根据hoodie.parquet.small.file.limit决定每个分区下的小文件,我们的示例中该配置为100MB,所以小文件为File_1、File_2和File_3;
步骤三:确定小文件后,新插入的记录将分配给小文件以便使其达到120MB,File_1将会插入80MB大小的记录数,File_2将会插入40MB大小的记录数,File_3将插入30MB大小的记录数。
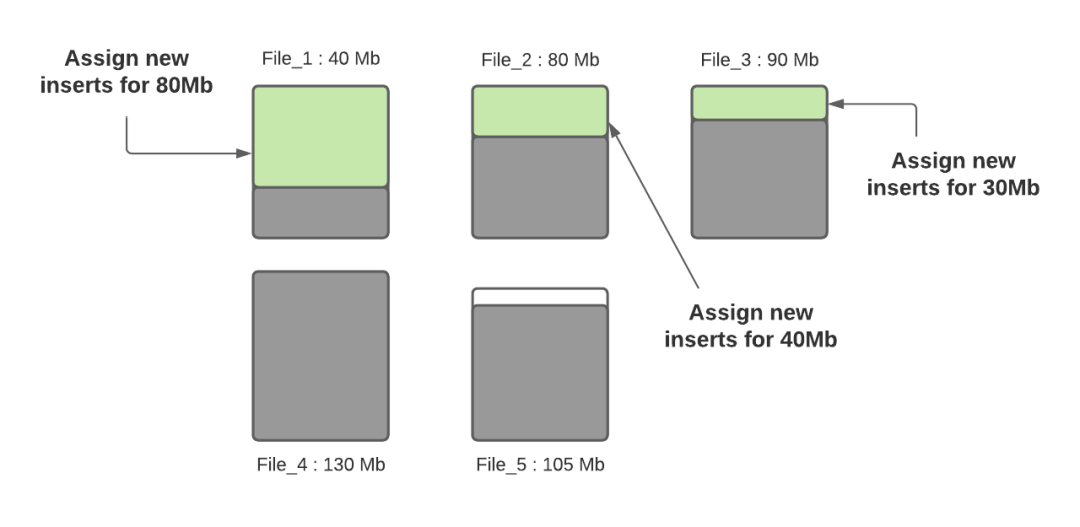
步骤四:当所有小文件都分配完了对应插入记录数后,如果还有剩余未分配的插入记录,这些记录将分配给新创建的FileGroup/数据文件。数据文件中的记录数由hoodie.copyonwrite.insert.split.size(或者由之前的写入自动推算每条记录大小,然后根据配置的最大文件大小计算出来可以插入的记录数)决定,假设最后得到的该值为120K(每条记录大小1K),如果还剩余300K的记录数,将会创建3个新文件(File_6,File_7,File_8),File_6和File_7都会分配120K的记录数,File_8会分配60K的记录数,共计60MB,后面再写入时,File_8会被认为小文件,可以插入更多数据。
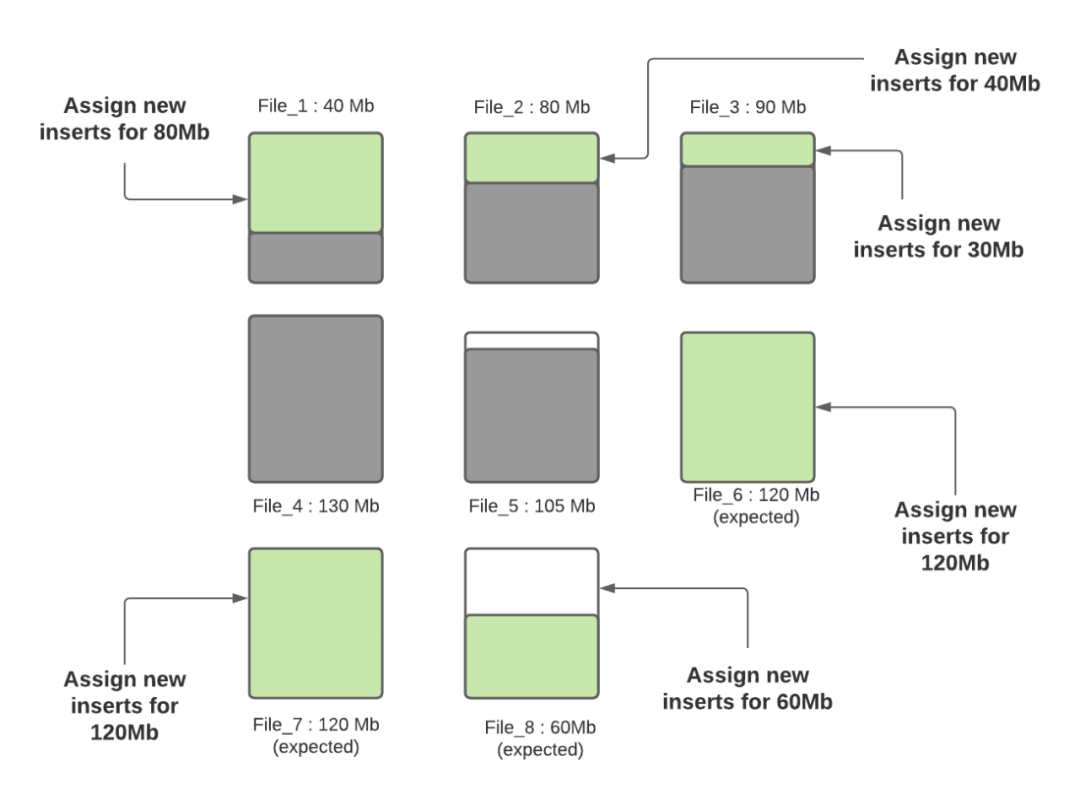
Hudi利用诸如自定义分区之类的机制来优化记录分配到不同文件的能力,从而执行上述算法。在这轮写入完成之后,除File_8以外的所有文件均已调整为最佳大小,每次写入都会遵循此过程,以确保Hudi表中没有小文件。
5. 总结
本文介绍了Apache Hudi如何智能地管理小文件问题,即在写入时找出小文件并分配指定大小的记录数来规避小文件问题,基于该设计,用户再也不用担心Apache Hudi数据湖中的小文件问题了。
引用链接
[1] hoodie.parquet.max.file.size: http://hudi.apache.org/docs/configurations.html#limitFileSize[2] hoodie.parquet.small.file.limit: (http://hudi.apache.org/docs/configurations.html#compactionSmallFileSize)[3] hoodie.copyonwrite.insert.split.size: http://hudi.apache.org/docs/configurations.html#insertSplitSize