
Python实现 ! 千万级别数据处理
今天分享一个数据清洗小技巧,可以让你在遇到 百万、千万级别数据 的时候游刃有余。
先来说说问题的背景
现在有一个 csv 格式的数据集,大概 2千万条 左右的样子,存储的是用户的网络交互数据,其中电话号码作为用户的唯一标识。
再来看看我们要做啥
首先我们需要针对这批用户确定所属运营商,其次根据交互数据对各运营商的用户感知情况进行分析,最后给出各运营商的相应优化解决措施。
这个目标的第一部分:确定用户归属运营商,正好可以用今天这个小技巧去解决。
判断两千万个号码中每个号码归属的运营商,你应该首先会想到循环遍历。
但是你如果真的挨个号码去遍历一次,你会发现读一遍数据都需要好久,甚至可能会需要几分钟、十几分钟。
所以今天会用到 Pandas 中的矢量化操作,通过 isin 函数进行筛选过滤,完成上面这个任务 只需要一两秒
矢量化操作
矢量化,有别于对每一个单独的值(标量)进行操作,是 Pandas 底层支持的对于整个 Array 进行的操作,也是Pandas 中执行的最快的方法。
这种操作适用于对某一列的全体数据进行普适的操作,即矢量化是对整个数组执行操作的过程。
矢量化操作适用于 Pandas 的 Dataframe,Series 对象
Pandas 对于常用的函数,例如求和、平均值等常用统计函数做了非常好的矢量化支持。
在大多数场景下,我们需要做的只是 把一整列的元素,当成一个元素去处理,Pandas 会自动把函数应用到每一个单元格上。例如
df_data['age'] = df_data['age'] + 5
这就是最简单的矢量化操作,就算你的数据集是 2 千万条,执行一次简单矢量化操作最多几秒也就可以搞定。
isin 方法可以通过矢量化操作,完成简单的数据筛选
isin函数
常用的是 DataFrame 的 isin 函数,它的官方定义是这样的:
def isin(self, values):
"""
Whether each element in the DataFrame is contained in values.
Parameters
----------
values : iterable, Series, DataFrame or dict
The result will only be true at a location if all the
labels match. If `values` is a Series, that's the index. If
`values` is a dict, the keys must be the column names,
which must match. If `values` is a DataFrame,
then both the index and column labels must match.
Returns
-------
DataFrame
DataFrame of booleans showing whether each element in the DataFrame
is contained in values.
"""
可以看到需要传入一个参数 values,函数会返回一个 DataFrame。
其中参数 values 大致解释如下:
values :iterable, Series, DataFrame 或 dict
如果所有标签都匹配,则结果仅在某个位置为 true。 如果 values 是 Series,那就是索引。 如果 values 是一个 dict,则键必须是必须匹配的列名。 如果值是 DataFrame,则索引标签和列标签都必须匹配。
返回值是一个布尔的 DataFrame,显示 DataFrame 中的每个元素是否包含在值 values 中。
大致解释一下:
当 values 是列表时,将会检查列表中是否存在 DataFrame 中的每个值
当 values 是 dict 时,可以通过传递值以分别检查每一列
当 values 是 Series 或 DataFrame 时,索引和列必须匹配
"""创建 DataFrame"""
df = pd.DataFrame({'num_legs': [2, 4], 'num_wings': [2, 0]}, index=['falcon', 'dog'])
df
num_legs num_wings
falcon 2 2
dog 4 0
# values 是列表
df.isin([0, 2])
num_legs num_wings
falcon True True
dog False True
# values 是 dict
df.isin({'num_wings': [0, 3]})
num_legs num_wings
falcon False False
dog False True
# values 是 DataFrame
other = pd.DataFrame({'num_legs': [8, 2], 'num_wings': [0, 2]}, index=['spider','falcon'])
df.isin(other)
num_legs num_wings
falcon True True
dog False False
isin 函数的用法就这些,很简单,下面针对我们遇到的问题试试用 isin 快速解决
isin 实战
首先在判断号码归属运营商时需要借助一个表
对!各运营商对应的号段表
这个号段在网上应该都能查到,另外,需要注意还有一些运营商对应的虚拟号段
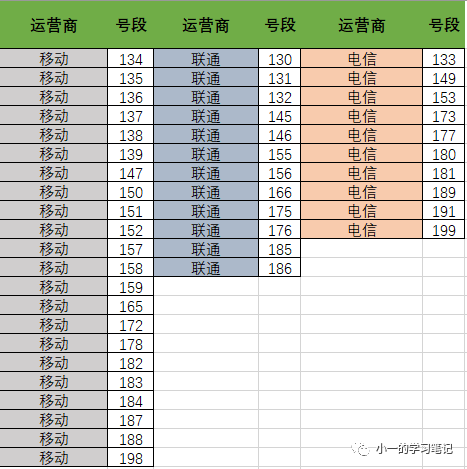
根据号段去确定每个用户号码的运营商归属即可
具体实现代码如下:
# 获取移动运营商的号段
mobile_list = df_data.loc[df_data['运营商'] == '移动', '号段'].drop_duplicates().tolist()
# 根据移动号段匹配所有移动用户
df_data_mobile = df_data.loc[df_data['号段'].str.slice(0, 3).isin(mobile_list), :]
# 获取联通运营商的号段
unicom_list = df_data.loc[df_data['运营商'] == '联通', '号段'].drop_duplicates().tolist()
# 根据联通号段匹配所有联通用户
df_data_unicom = df_data.loc[df_data['号段'].str.slice(0, 3).isin(unicom_list), :]
# 匹配电信用户
df_data_net = df_data.loc[~df_data['号段'].str.slice(0, 3).isin(mobile_list) &
~df_data['号段'].str.slice(0, 3).isin(unicom_list)
, :]
【左右滑动查看更多】
代码中通过 isin 方法和 loc 结合,实现了对 DataFrame 的过滤筛选。
稍微解释一下:首先根据移动号段确定移动用户,其次根据联通号段确定联通用户,最后通过 isin 的反方法确定非移动和联通的号段,即电信号段,确定电信用户。
需要注意,isin 方法的反方法是在其前面加上 ~,不存在 isnotin 方法,
写在后面的话
巧用 isin 方法,可以极大的提高数据处理效率,还能提高打工人的代码素养。
另外,类似的方法还有 where、cut 等,都可直接进行矢量化操作,下次遇到具体案例了再分享。

推荐阅读
欢迎长按扫码关注「数据管道」