
Swin Transformer V2:通向视觉大模型之路
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
继Swin Transformer之后,微软在去年11月份发布了Swin Transformer V2,目前模型的实现以及预训练模型已经开源。Swin Transformer V2的核心是将模型扩展到更大的容量和分辨率,其中最大的模型SwinV2-G参数量达到了30亿,在物体检测任务上图像分辨率达到1536x1536,基于SwinV2-G的模型也在4个任务上达到了SOTA:在图像分类数据集ImageNet V2上达到了84.0%的top1准确度,在物体检测数据集COCO上达到了63.1/54.4的box/mask mAP,在语义分割数据集上ADE20K达到了59.9 mIoU,在视频分类数据集Kinetics-400上达到了86.8%,不过目前,只有COCO和ADE20K两个数据集上还保持SOTA。当将模型进行扩展时,作者发现面临两个主要的困难:一是大模型的训练变得不稳定,二是预训练模型增大窗口大小会出现性能下降。作者通过相应的优化策略来重点解决这两个问题,本文将结合论文和源码来介绍这些优化方法。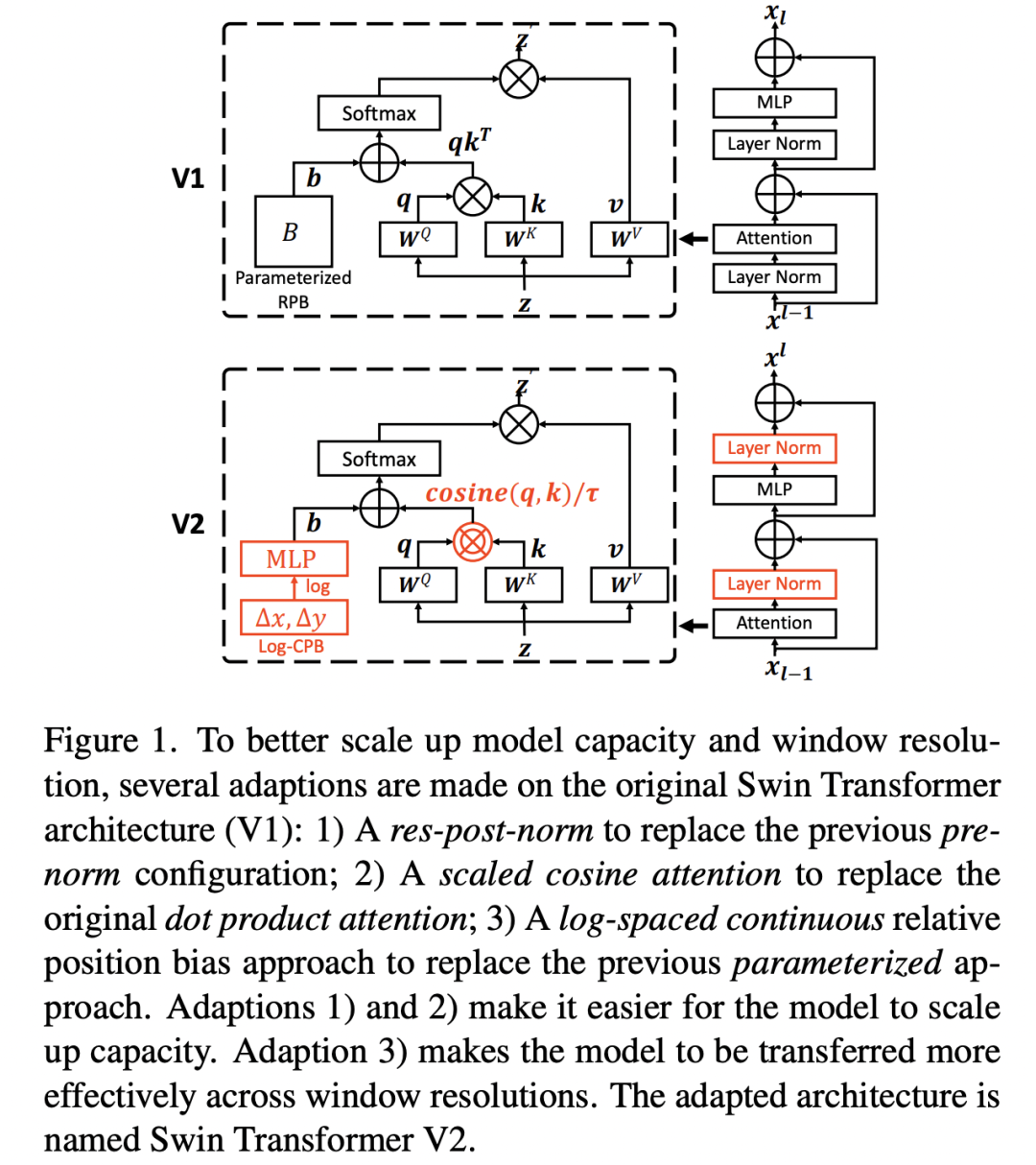
Post norm
将模型变大变深后往往出现训练难题,作者发现将Swin模型扩展到大模型后,激活值随着层数的加深大幅增长,如下图所示,其中最大值与最小值比例可高达,对于参数量为658M的的Swin-H模型(左图最上面红色曲线),这种差异使得模型无法完成训练(图右蓝色线,训练loss出现上升)。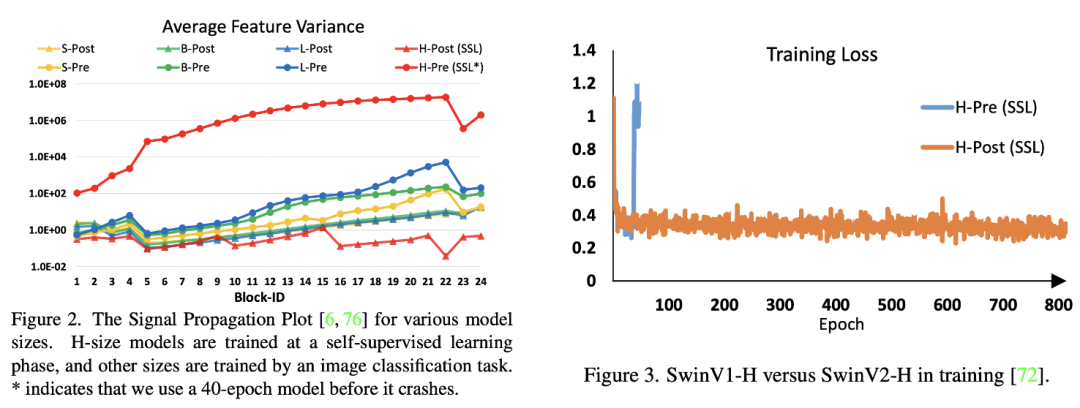 作者发现可以调整LayerNorm的位置来解决这个问题,vision transfomer默认采用的pre-norm的方式,即在Attention和FFN之前先进行LayerNorm,而SwinV2采用post-norm:将LayerNorm调整到Attention和FFN之后。采用post-norm,Attention或者FFN的输出经过LayerNorm之后才和shortcut相加,这样就尽量减少网络加深后的激活值积累,论文发现采用post-norm后,不同层的激活值确实也变得更平稳了,如上图所示。对于最大的模型Swin-G,还每6个transformer blocks之间再增加一个LayerNorm来进一步稳定训练和激活值。
作者发现可以调整LayerNorm的位置来解决这个问题,vision transfomer默认采用的pre-norm的方式,即在Attention和FFN之前先进行LayerNorm,而SwinV2采用post-norm:将LayerNorm调整到Attention和FFN之后。采用post-norm,Attention或者FFN的输出经过LayerNorm之后才和shortcut相加,这样就尽量减少网络加深后的激活值积累,论文发现采用post-norm后,不同层的激活值确实也变得更平稳了,如上图所示。对于最大的模型Swin-G,还每6个transformer blocks之间再增加一个LayerNorm来进一步稳定训练和激活值。
关于深度ViT的训练,其实meta AI也在CaiT中提出了一个简单的策略LayerScale,如下图d所示,FFN和SA之后每个channel乘以一个训练的系数,这个系数往往初始化值较小比如1e-4,这样看来其实LayerScale和post-norm一样也是来约束FFN和SA的输出,防止层数加深后出现激活值的增加。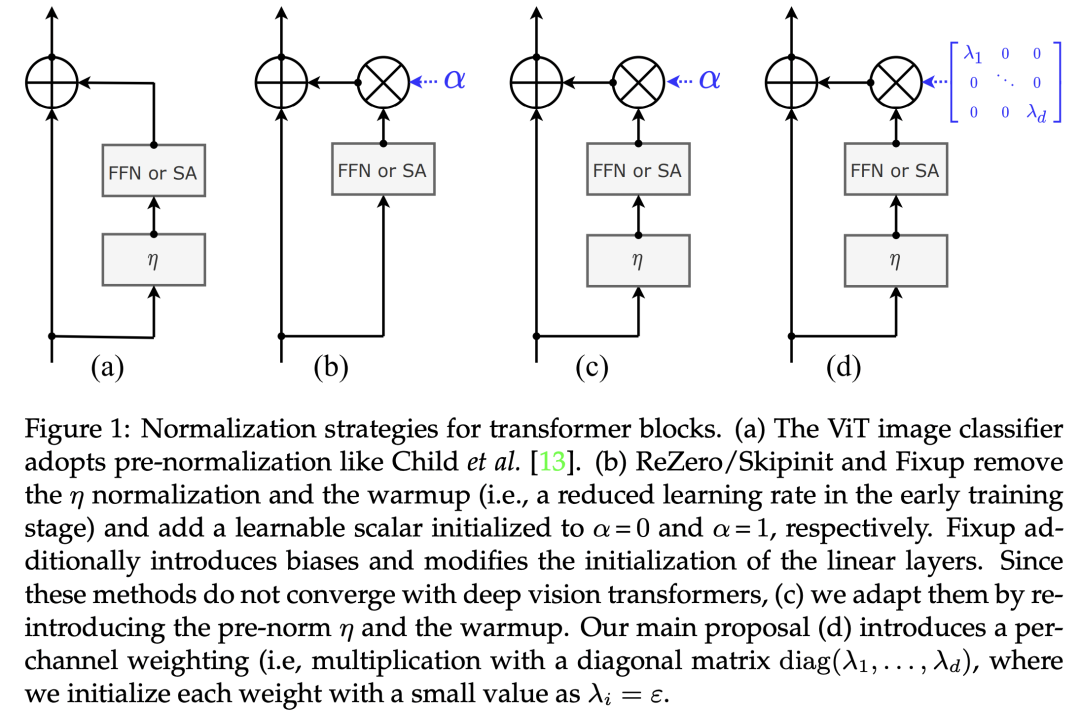 另外一点是,原始的Transformer模型采用的也是post-norm,不过和SwinV2里说的post-norm不一样,它是残差和shortcut相加后才执行LayerNorm,如下图a所示。论文On Layer Normalization in the Transformer Architecture也研究了pre-norm和post-norm在NLP任务上表现,发现同等条件下,pre-norm相比post-norm更容易训练,而post-norm需要一些额外的策略如warmup来达到较优的效果。不过也有论文如Understanding the Difficulty of Training Transformers指出post-norm往往可以比pre-norm获得更好的效果,关于这一点可以见博客为什么Pre Norm的效果不如Post Norm?一个简单的解释是pre-norm由于LayerNorm在残差结构里面,并没有破坏短路连接,所以更容易训练,但是同时也可能将网络退化到一个“宽网络”,降低网络的表达力。
另外一点是,原始的Transformer模型采用的也是post-norm,不过和SwinV2里说的post-norm不一样,它是残差和shortcut相加后才执行LayerNorm,如下图a所示。论文On Layer Normalization in the Transformer Architecture也研究了pre-norm和post-norm在NLP任务上表现,发现同等条件下,pre-norm相比post-norm更容易训练,而post-norm需要一些额外的策略如warmup来达到较优的效果。不过也有论文如Understanding the Difficulty of Training Transformers指出post-norm往往可以比pre-norm获得更好的效果,关于这一点可以见博客为什么Pre Norm的效果不如Post Norm?一个简单的解释是pre-norm由于LayerNorm在残差结构里面,并没有破坏短路连接,所以更容易训练,但是同时也可能将网络退化到一个“宽网络”,降低网络的表达力。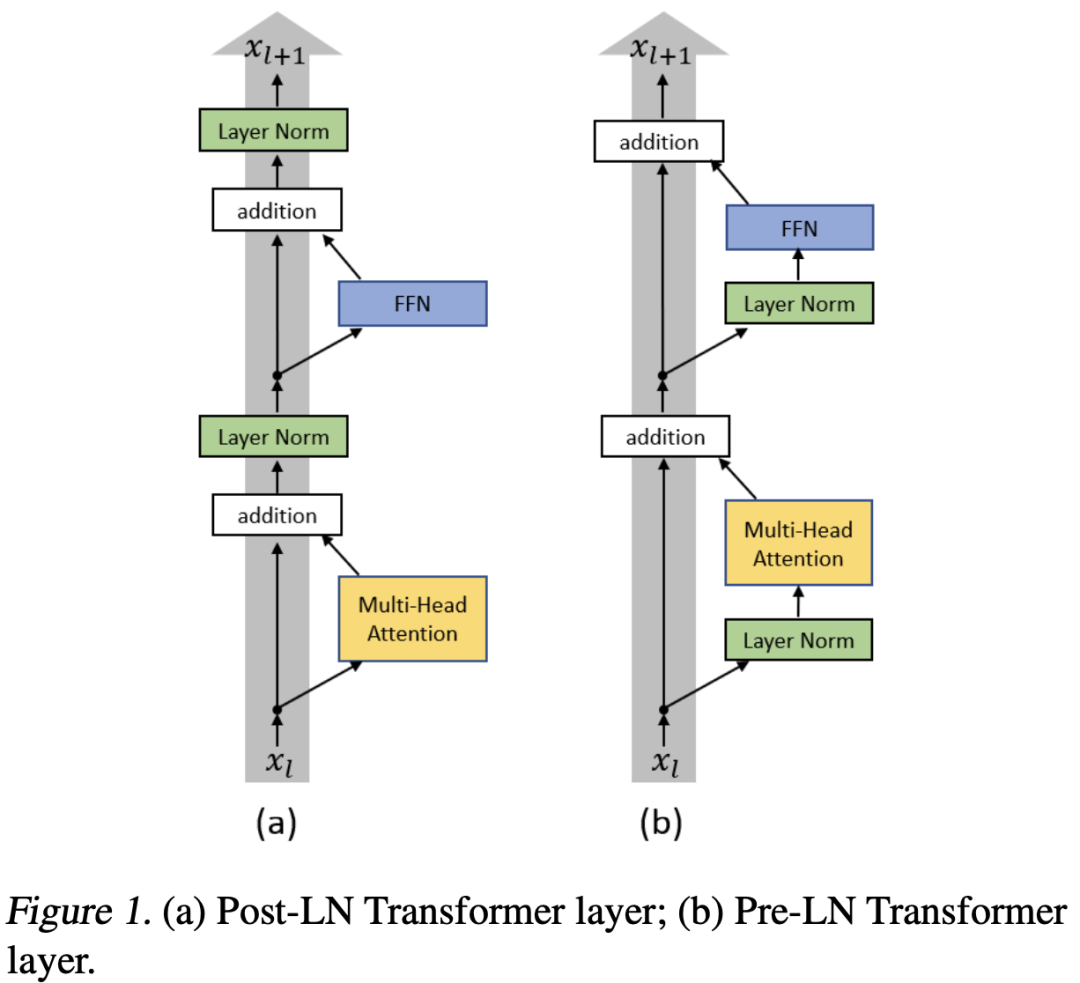 虽然post-norm或许效果较好,但是训练比较困难,特别是层数较深时,最近微软也提出了一个简单的优化策略来训练1000层的Transformer模型DeepNet,这个策略就是将shortcut乘以一个大于1的常量(依赖模型架构),如果再和残差部分相加后再进行LN。
虽然post-norm或许效果较好,但是训练比较困难,特别是层数较深时,最近微软也提出了一个简单的优化策略来训练1000层的Transformer模型DeepNet,这个策略就是将shortcut乘以一个大于1的常量(依赖模型架构),如果再和残差部分相加后再进行LN。 为了防止和原始Transformer的post-norm相混淆,论文的第2版将提出的post-norm重命名为res-post-norm(residual post normalization),也增加了基于Swin-S和Swin-B两个模型的对比实验,相比来看,还是res-post-norm效果更好一点。不过这里没有对比更大的模型
为了防止和原始Transformer的post-norm相混淆,论文的第2版将提出的post-norm重命名为res-post-norm(residual post normalization),也增加了基于Swin-S和Swin-B两个模型的对比实验,相比来看,还是res-post-norm效果更好一点。不过这里没有对比更大的模型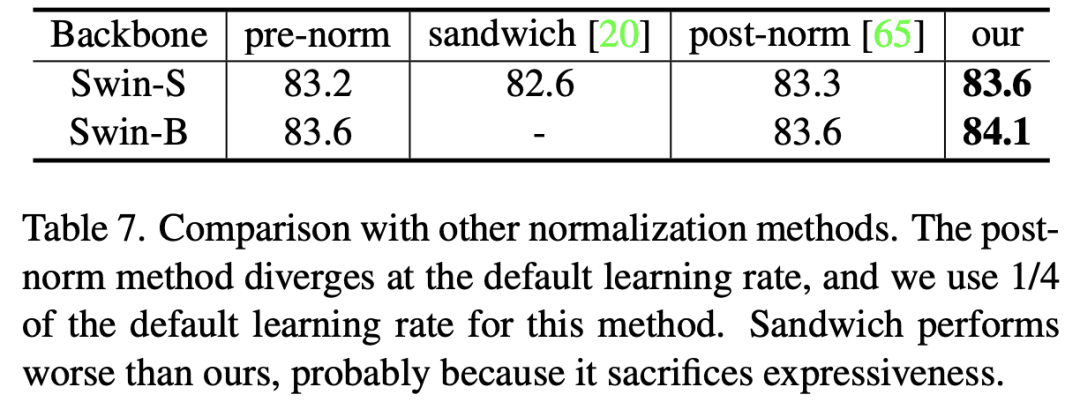
Scaled cosine attention
原始的self-attention采用scaled dot product来计算两个token的相似度:计算两个token特征的点积,然后除以特征维度大小的平方根。作者发现对于大模型,其学习到的attention map往往被较少的一部分token所主导,特别是采用post-norm后。为了解决这个问题,论文提出scaled cosine attention,即计算两个token的余弦相似度,然后除以一个可学习的标量:
其中是relative position bias,而是一个训练参数,不同层和attention head不共享,并且限制大于0.01。具体的实现如下所示:
# 初始化\tau
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale, max=torch.log(torch.tensor(1. / 0.01))).exp()
attn = attn * logit_scale
由于余弦相似度范围在0~1,所以它使得不同的token间的相似度分布在同样的尺度下,从而减少attention map的过于集中的问题。下表为不同的模型使用scaled cosine attention后的对比实验,可以看到,在使用res-post-norm之后再使用scaled cosine attention可以进一步提升模型的分类准确度。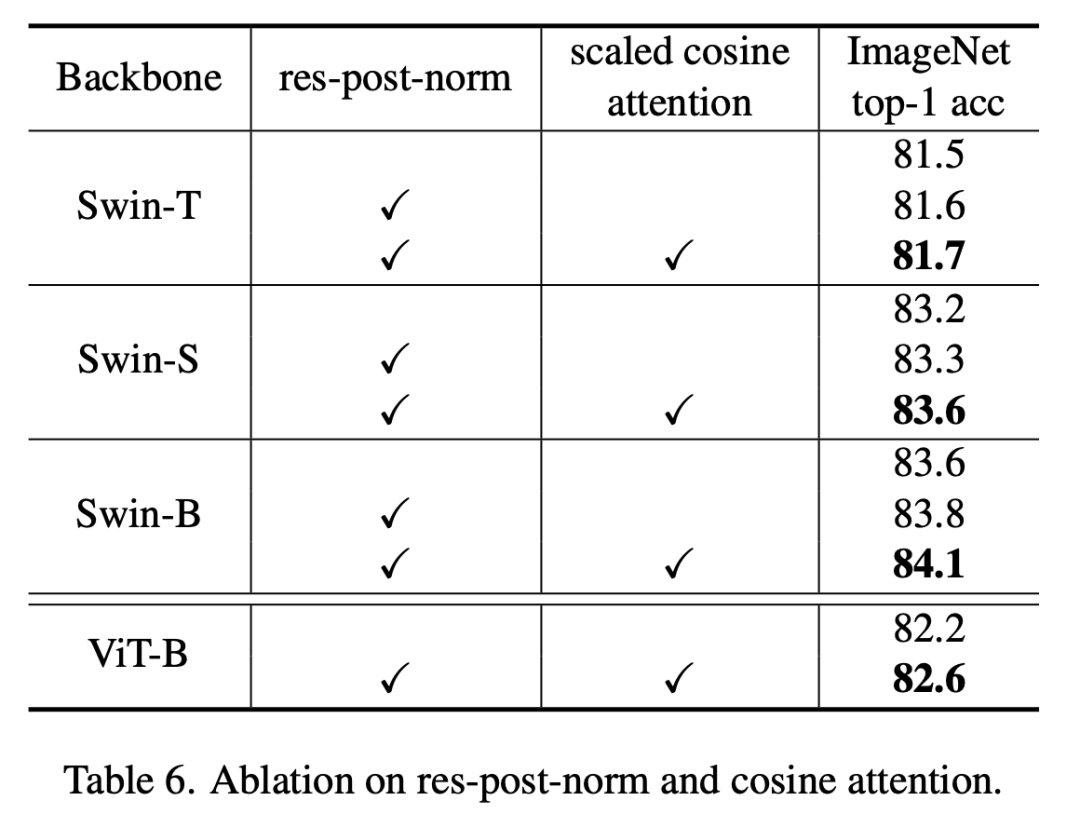
Log-spaced continuous position bias
分类模型的图像分辨率低,但是对于下游任务如检测和分割往往要采用更大的分辨率。由于Swin采用window attention和relative position bias,当采用分类预训练模型迁移到下游任务时如果要采用更大的window size,那么就需要对relative position bias进行插值。大的视觉模型往往同时需要提升图像的分辨率,那么此时也最好同时增大window来提升感受野。作者发现直接插值的话往往效果会下降,如下表所示,采用8x8的window和256x256分辨率的Swin-T模型在ImageNet1K上能达到81.7,但如果将这个预训练模型在12x12的window和384x384分辨率下,效果只有79.4,但是finetune之后能达到82.7%。论文提出了一种新的策略log-spaced continuous position bias(记为Log-CPB)来解决这个问题,如下表所示,基于Log-CPB的模型直接在同样的场景下迁移效果能达到82.4%,超过原来的81.8%,而且finetune之后可以达到83.2%,在COCO和ADE20k数据集上也表现更好。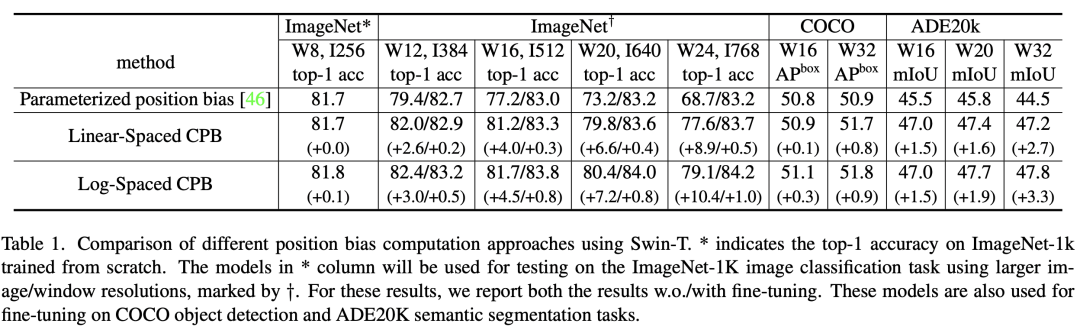 在介绍Log-CPB,我们先来回顾一下Swin所采用的relative position bias,它是在计算attention时加上一个bias项,如下所示:
在介绍Log-CPB,我们先来回顾一下Swin所采用的relative position bias,它是在计算attention时加上一个bias项,如下所示:
这里的就是relative position bias,它用来编码window中的各个tokens间的相对位置,为window的大小,总共有个tokens。而由于图像是2D结构,token在每个维度上的相对位置分布在范围内,总共有个值,那么通过定义一个训练的bias矩阵,就能通过索引的方式得到,这样处理的好处是参数量比较小。当改变window大小时,就需要对进行插值。而SwinT-V2的改进策略时采用连续的relative position bias,不再定义一个固定大小的,而是采用一个小网络来预测relative position bias,这里:
这里的G是一个包含2层的MLP模型,中间采用ReLU激活,采用网络G的好处是它可以生成任意相对位置的来得到relative position bias,这样在迁移到更大的window时就不需要任何更改。虽然网络G可以适应不同大小的window,但是当window size变化时,相对位置范围也发生了变化,这意味着网络G要接受和预训练模型不一样的输入范围,为了尽量减少输入范围的变化,论文进一步提出采用log空间下的坐标来替换原来的线性坐标,两者的转换公式如下所示:
采用对数坐标的好处是可以减少范围的变化,这对网络G的泛化要求就变低了。比如要将8x8大小的window迁移到16x16大小,对于线性坐标,其范围从原来的[-7, 7]到[-15, 15],此时相当于额外增加了(15 - 7)/7=1.14倍原来的坐标范围。如果采用对数坐标,其范围从原来的[-2.079, 2.079]到[-2.773, 2.773],此时只额外增加了(2.773 - 2.079)/2.079=0.33倍原来的范围。从上表的对比结果来看,Log-CPB效果也要优于Linear-CPB。Log-CPB的具体实现代码如下所示(和论文描述有部分细节不同):
# 网络G来生成连续的relative position bias
self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False))
# 获取relative_coords_table: (2M-1)x(2M-1)作为网络G的输入
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(
torch.meshgrid([relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
# 归一化,迁移预训练模型时用原来的window size
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # 归一化到 -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / np.log2(8) # 这里也同时除以np.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table)
# 得到相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
# 预测时先用网络G产生\hat B,然后根据相对位置索引生成B
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias) # 限制bias的大小范围?
attn = attn + relative_position_bias.unsqueeze(0)
论文还采用SwinV2-S和SwinV2-B对Log-CPB做了对比实验,可以看到使用Log-CPB后迁移到更大的window和更大的分辨率下,效果更好。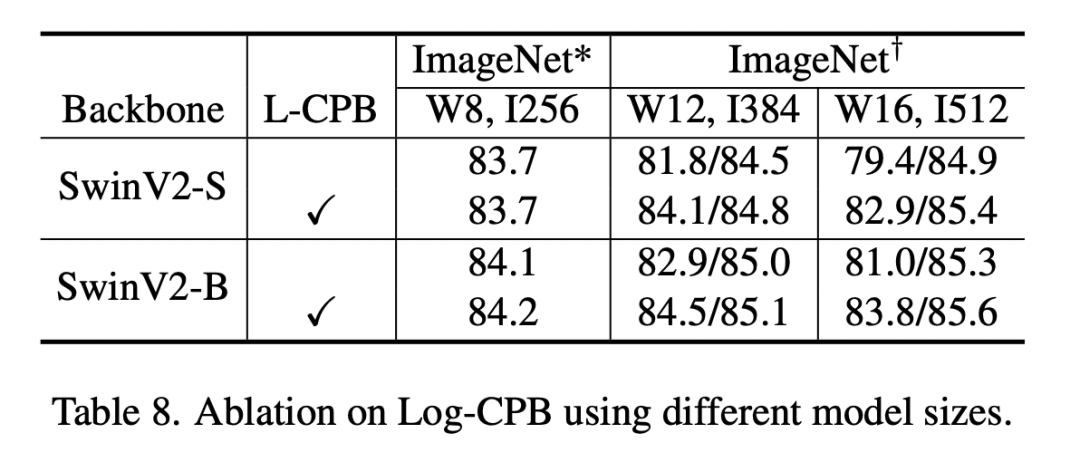 除此之外,论文还对不同方法得到的relative position bias矩阵(应该是relative position table,即)进行了可视化,可以看到采用连续的relative position bias更光滑。
除此之外,论文还对不同方法得到的relative position bias矩阵(应该是relative position table,即)进行了可视化,可以看到采用连续的relative position bias更光滑。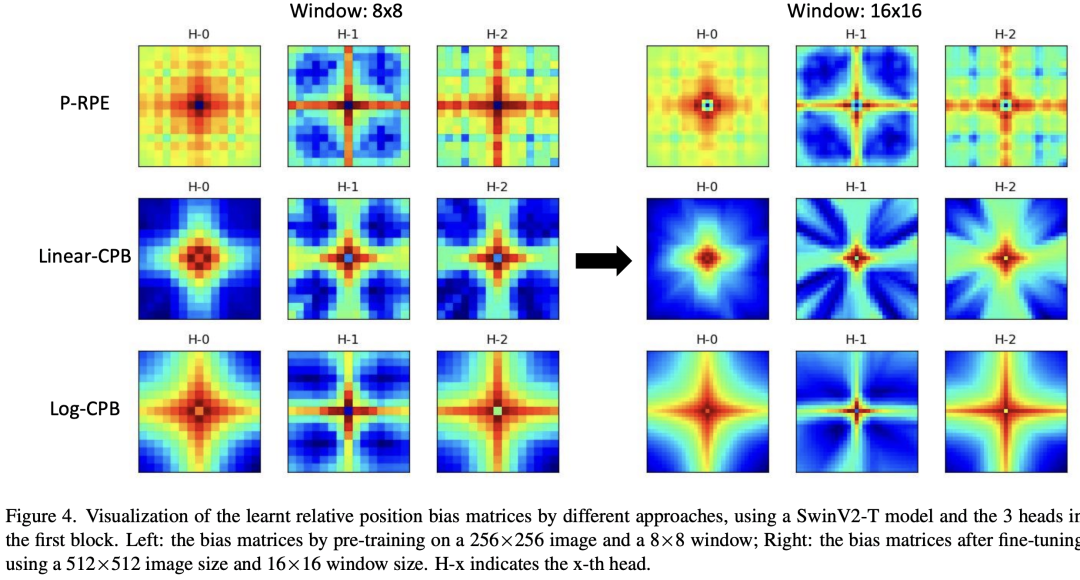
其它策略
对于大模型来说,显存消耗是一个大的挑战,论文也采用了一些优化策略来降低显存消耗,主要包括以下方法:
ZeRO优化器:ZeRO是将模型参数和优化器状态参数均分到不同的GPU上,这样就可以降低显存使用,这里采用DeepSpeed库的ZeRO-1,它可以降低显存消耗但是几乎不影响训练速度。 Activation check-pointing:模型的中间特征也会消耗大量的GPU,可以采用activation check-pointing来缓解这个问题,目前PyTorch已经支持,具体见https://pytorch.org/docs/stable/checkpoint.html。这个优化虽然降低了显存消耗,但是也将训练速度降低了30%。 Sequential self-attention computation:不再对self-attention进行batch运算,而是序列地逐个执行,从而降低显存使用,不过这个优化只在前两个stages使用,对训练速度只有少量的影响。
通过上述优化,可以用40GB的A100在COCO任务上(1536x1536大小)或Kinetics-400任务(320x320x8大小)训练最大的模型Swin-G。大模型往往也需要更大的数据集来进行训练,作者将ImageNet-22K数据集扩展了5倍达到了70M,并基于自监督学习方法SimMIM来进行预训练。
模型设置
SwinV2和SwinV1一样,也首先包含4个不同大小的模型:
SwinV2-T:C = 96,block = {2, 2, 6, 2} SwinV2-S/B/L:C=96/128/192,block={2, 2, 18, 2}
除了这个4个模型外,还包括2个更大的模型:SwinV2-H和SwinV2-G,它们的参数量分别达到了658M和3B:
SwinV2-H: C = 352,block = {2, 2, 18, 2} SwinV2-G: C = 512,block = {2, 2, 42, 4}
对于最大的两个模型,如前面所述,为了提升训练的稳定性,每6个transformer层间增加一个LayerNorm层。
实验结果
由于是研究大模型,所以论文的主要实验结果是基于最大的模型SwinV2-G,这里共对比了4个不同的任务:图像分类ImageNet-1K (V1 and V2)数据集,物体检测COCO数据集,语义分割ADE20K数据集,以及视频理解Kinetics-400数据集。SwinV2-G首先采用2阶段的预训练策略来进行预训练,首先基于自监督方法SimMIM在70M的ImageNet-22K-ext数据集上训练20个epochs,然后在这个数据集上基于有监督再训练20个epochs。为了减少训练成本,采用192x192的分辨率进行预训练。在图像分类任务上,SwinV2-G在ImageNet-1K上达到了90.17%,这也是继谷歌之后第一个超过90%的模型,而在ImageNet-1K-V2上达到了84.0%,是当时的SOTA,目前最好的结果是谷歌的Model soups。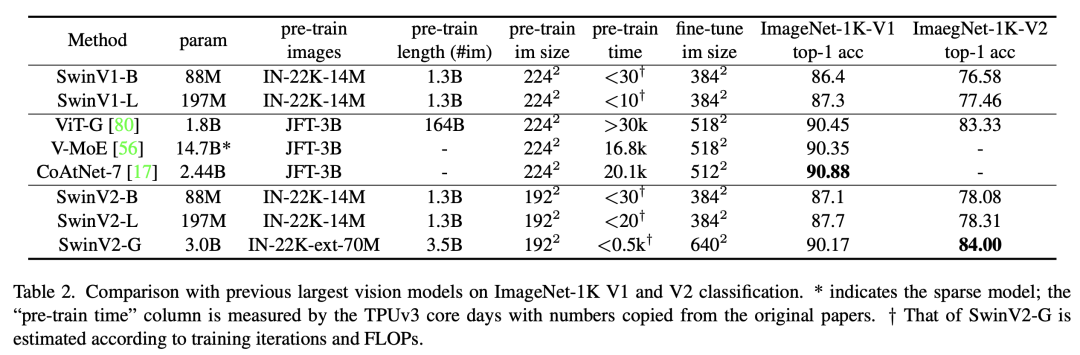 在物体检测任务上,基于SwinV2-G的HTC++达到了63.1/54.4的box/mask mAP,对于实例分割目前是SOTA,但是检测效果低于DINO,这里的分辨率采用1536x1536,而窗口大小采用32x32。
在物体检测任务上,基于SwinV2-G的HTC++达到了63.1/54.4的box/mask mAP,对于实例分割目前是SOTA,但是检测效果低于DINO,这里的分辨率采用1536x1536,而窗口大小采用32x32。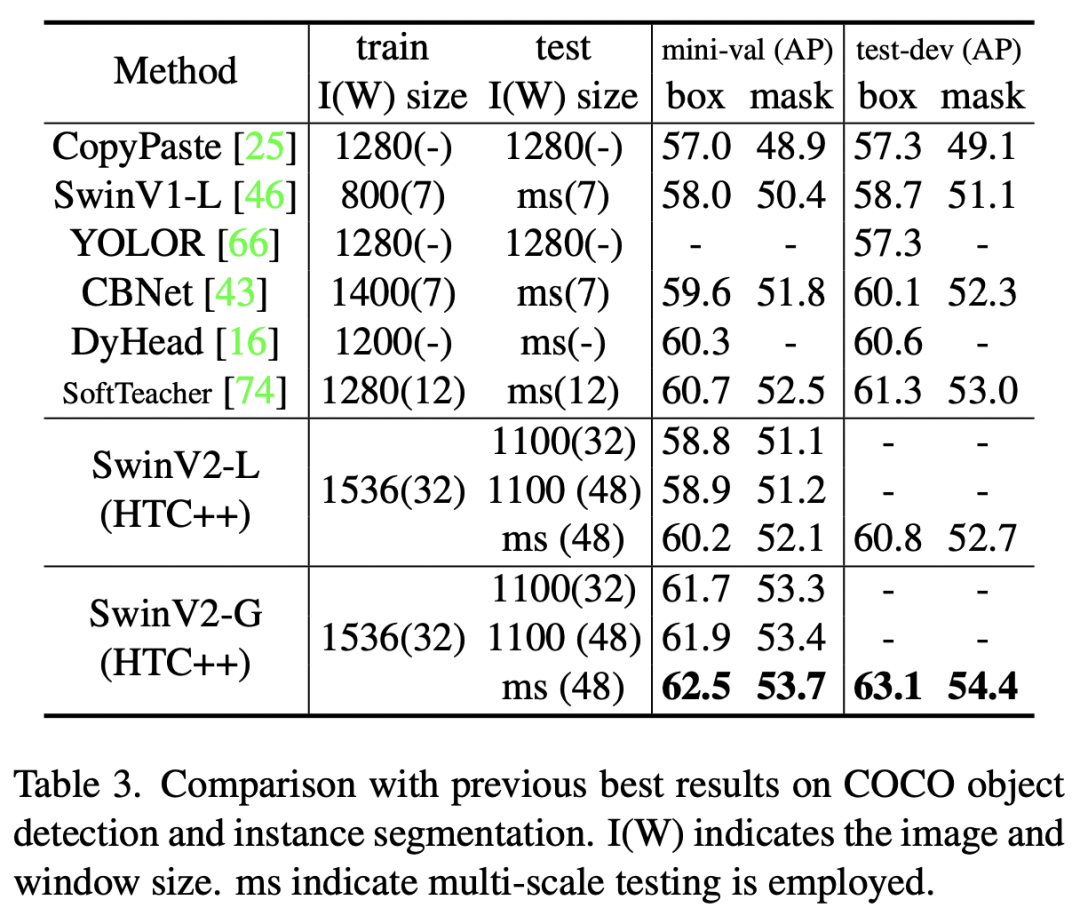 在语义分割上,基于UperNet的分割模型在AD E20K上达到了59.9 mIoU。
在语义分割上,基于UperNet的分割模型在AD E20K上达到了59.9 mIoU。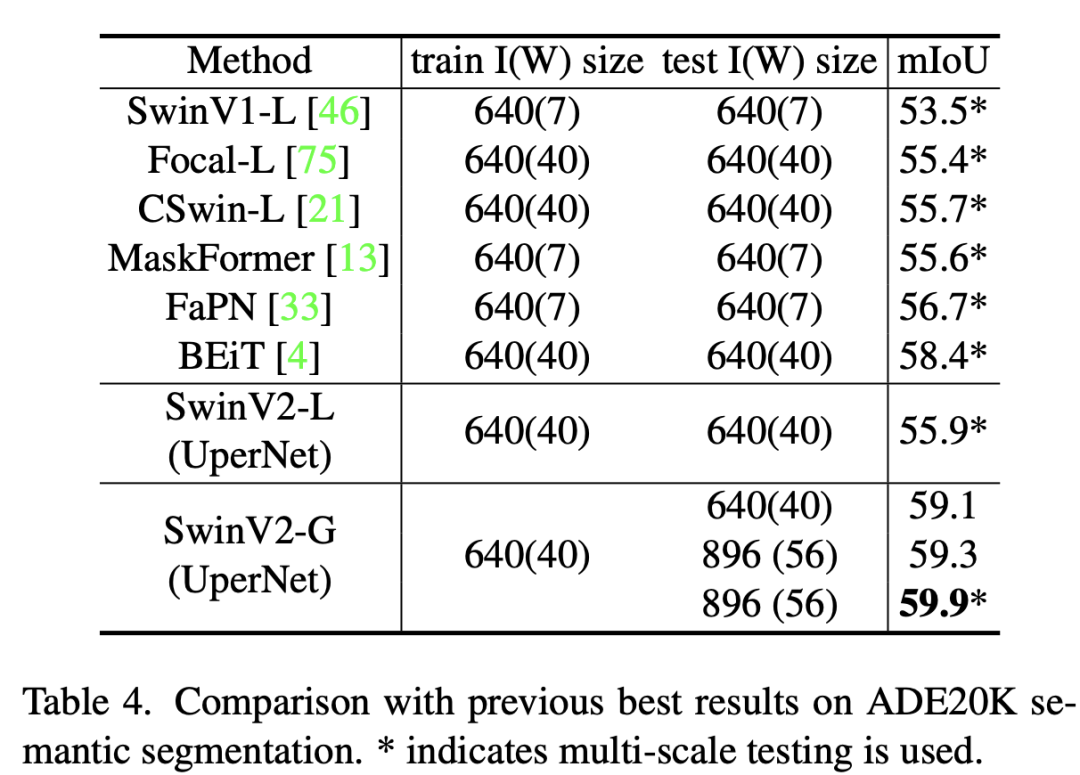 在视频分类上,基于Video-SwinV2-G的模型分类准确度达到了86.8%。
在视频分类上,基于Video-SwinV2-G的模型分类准确度达到了86.8%。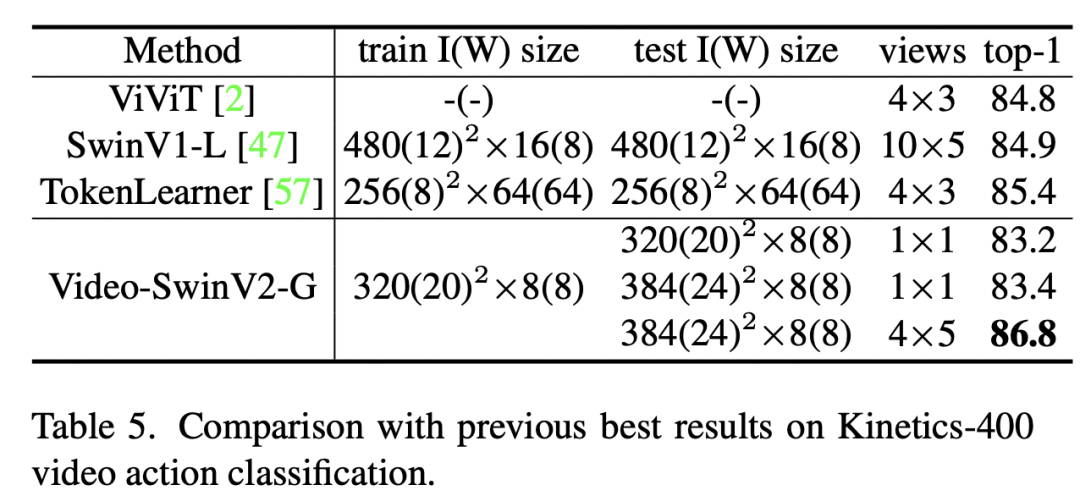
小结
SwinV1是让我们看到Vision Transformer在下游分割和检测任务上应用的可能,而SwinV2让我们看到了Vision Transformer扩展到大模型的应用可能。
参考
Swin Transformer V2: Scaling Up Capacity and Resolution https://github.com/microsoft/Swin-Transformer Swin Transformer: Hierarchical Vision Transformer using Shifted Windows DeepNet: Scaling Transformers to 1,000 Layers On Layer Normalization in the Transformer Architecture Going deeper with Image Transformers
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
