
机器学习的通俗讲解!
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达



我决定写一篇酝酿已久的文章,对那些想了解机器学习的人做一个简单的介绍。不涉及高级原理,只用简单的语言来谈现实世界的问题和实际的解决方案。不管你是一名程序员还是管理者,都能看懂。
那我们开始吧!
为什么我们想要机器去学习?
现在出场的是Billy,Billy想买辆车,他想算出每月要存多少钱才付得起。浏览了网上的几十个广告之后,他了解到新车价格在2万美元左右,用过1年的二手车价格是1.9万美元,2年车就是1.8万美元,依此类推。
作为聪明的分析师,Billy发现一种规律:车的价格取决于车龄,每增加1年价格下降1000美元,但不会低于10000美元。
用机器学习的术语来说,Billy发明了“回归”(regression)——基于已知的历史数据预测了一个数值(价格)。当人们试图估算eBay上一部二手iPhone的合理价格或是计算一场烧烤聚会需要准备多少肋排时,他们一直在用类似Billy的方法——每人200g? 500?
是的,如果能有一个简单的公式来解决世界上所有的问题就好了——尤其是对于烧烤派对来说——不幸的是,这是不可能的。
让我们回到买车的情形,现在的问题是,除了车龄外,它们还有不同的生产日期、数十种配件、技术条件、季节性需求波动……天知道还有哪些隐藏因素……普通人Billy没法在计算价格的时候把这些数据都考虑进去,换我也同样搞不定。
人们又懒又笨——我们需要机器人来帮他们做数学。因此,这里我们采用计算机的方法——给机器提供一些数据,让它找出所有和价格有关的潜在规律。
终~于~见效啦。最令人兴奋的是,相比于真人在头脑中仔细分析所有的依赖因素,机器处理起来要好得多。
就这样,机器学习诞生了。
机器学习的3个组成部分
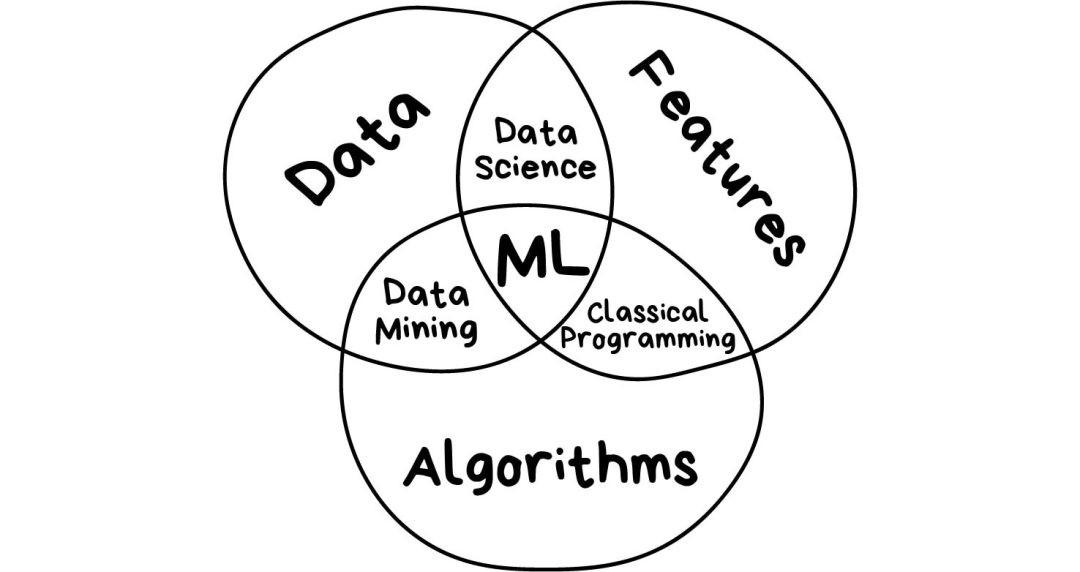
抛开所有和人工智能(AI)有关的扯淡成分,机器学习唯一的目标是基于输入的数据来预测结果,就这样。所有的机器学习任务都可以用这种方式来表示,否则从一开始它就不是个机器学习问题。
样本越是多样化,越容易找到相关联的模式以及预测出结果。因此,我们需要3个部分来训练机器:
数据
想检测垃圾邮件?获取垃圾信息的样本。想预测股票?找到历史价格信息。想找出用户偏好?分析他们在Facebook上的活动记录(不,Mark,停止收集数据~已经够了)。数据越多样化,结果越好。对于拼命运转的机器而言,至少也得几十万行数据才够吧。
获取数据有两种主要途径——手动或者自动。手动采集的数据混杂的错误少,但要耗费更多的时间——通常花费也更多。自动化的方法相对便宜,你可以搜集一切能找到的数据(但愿数据质量够好)。
一些像Google这样聪明的家伙利用自己的用户来为他们免费标注数据,还记得ReCaptcha(人机验证)强制你去“选择所有的路标”么?他们就是这样获取数据的,还是免费劳动!干得漂亮。如果我是他们,我会更频繁地展示这些验证图片,不过,等等……
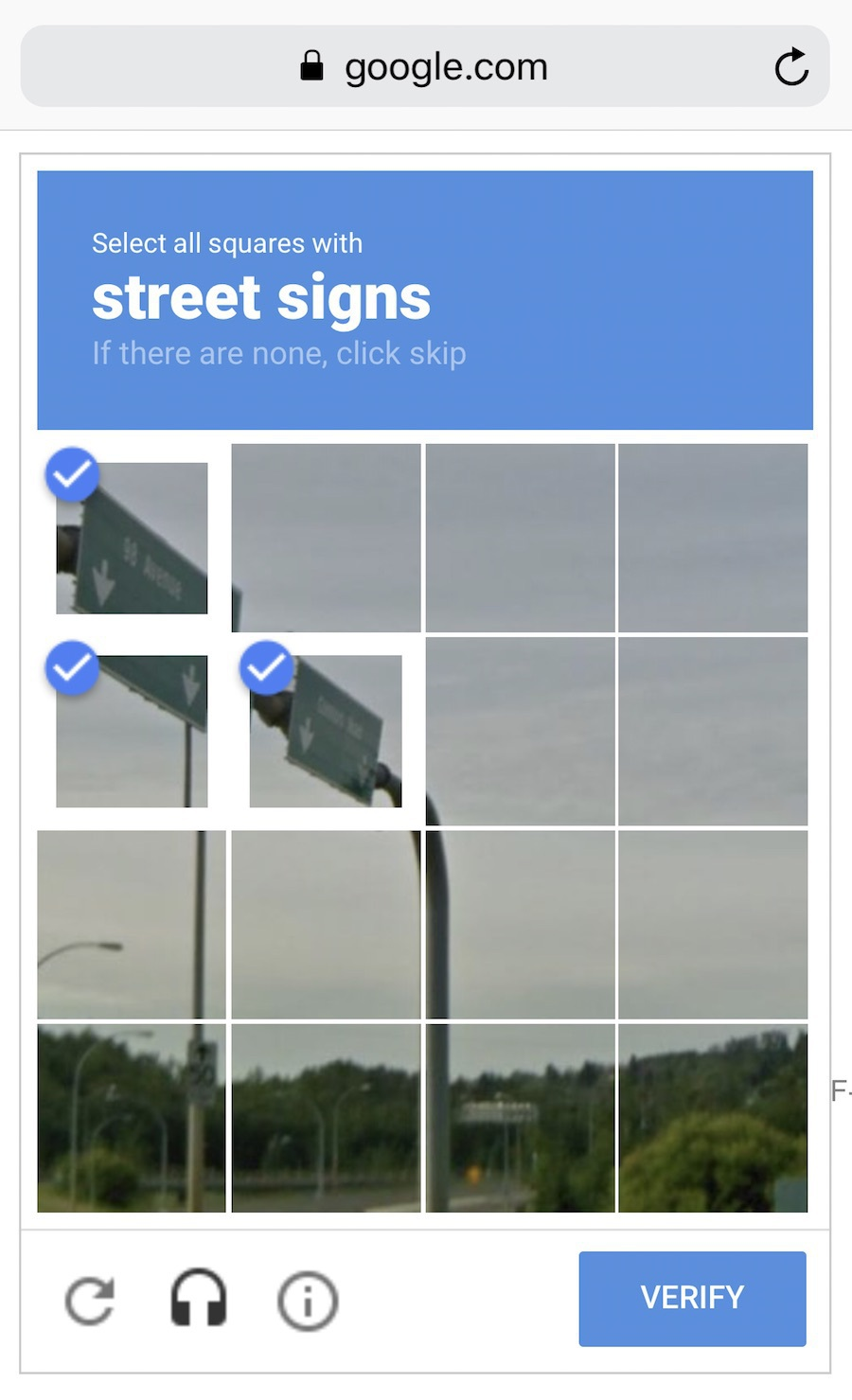
好的数据集真的很难获取,它们是如此重要,以至于有的公司甚至可能开放自己的算法,但很少公布数据集。
特征
也可以称为“参数”或者“变量”,比如汽车行驶公里数、用户性别、股票价格、文档中的词频等。换句话说,这些都是机器需要考虑的因素。
如果数据是以表格的形式存储,特征就对应着列名,这种情形比较简单。但如果是100GB的猫的图片呢?我们不能把每个像素都当做特征。这就是为什么选择适当的特征通常比机器学习的其他步骤花更多时间的原因,特征选择也是误差的主要来源。人性中的主观倾向,会让人去选择自己喜欢或者感觉“更重要”的特征——这是需要避免的。
算法
最显而易见的部分。任何问题都可以用不同的方式解决。你选择的方法会影响到最终模型的准确性、性能以及大小。需要注意一点:如果数据质量差,即使采用最好的算法也无济于事。这被称为“垃圾进,垃圾出”(garbae in - garbage out,GIGO)。所以,在把大量心思花到正确率之前,应该获取更多的数据。
学习 V.S. 智能
我曾经在一些流行媒体网站上看到一篇题为“神经网络是否会取代机器学习?”的文章。这些媒体人总是莫名其妙地把线性回归这样的技术夸大为“人工智能”,就差称之为“天网”了。下图展示了几个容易混淆的概念之间的关系。
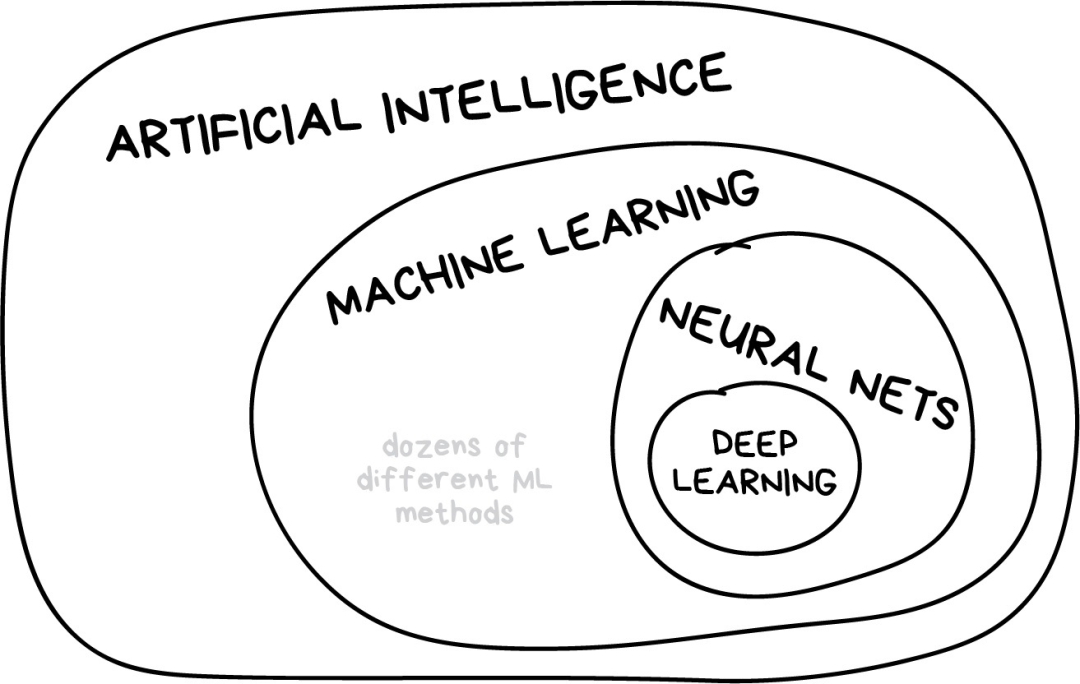
“人工智能”是整个学科的名称,类似于“生物学”或“化学”。 “机器学习”是“人工智能”的重要组成部分,但不是唯一的部分。 “神经网络”是机器学习的一种分支方法,这种方法很受欢迎,不过机器学习大家庭下还有其他分支。 “深度学习”是关于构建、训练和使用神经网络的一种现代方法。本质上来讲,它是一种新的架构。在当前实践中,没人会将深度学习和“普通网络”区分开来,使用它们时需要调用的库也相同。为了不让自己看起来像个傻瓜,你最好直接说具体网络类型,避免使用流行语。
一般原则是在同一水平上比较事物。这就是为什么“神经网络将取代机器学习”听起来就像“车轮将取代汽车”。亲爱的媒体们,这会折损一大截你们的声誉哦。
| 机器能 | 机器不能 |
|---|---|
| 预测 | 创造新事物 |
| 记忆 | 快速变聪明 |
| 复制 | 超出任务范围 |
| 选择最优项 | 消灭全人类 |
机器学习世界的版图
如果你懒得阅读大段文字,下面这张图有助于获得一些认识。
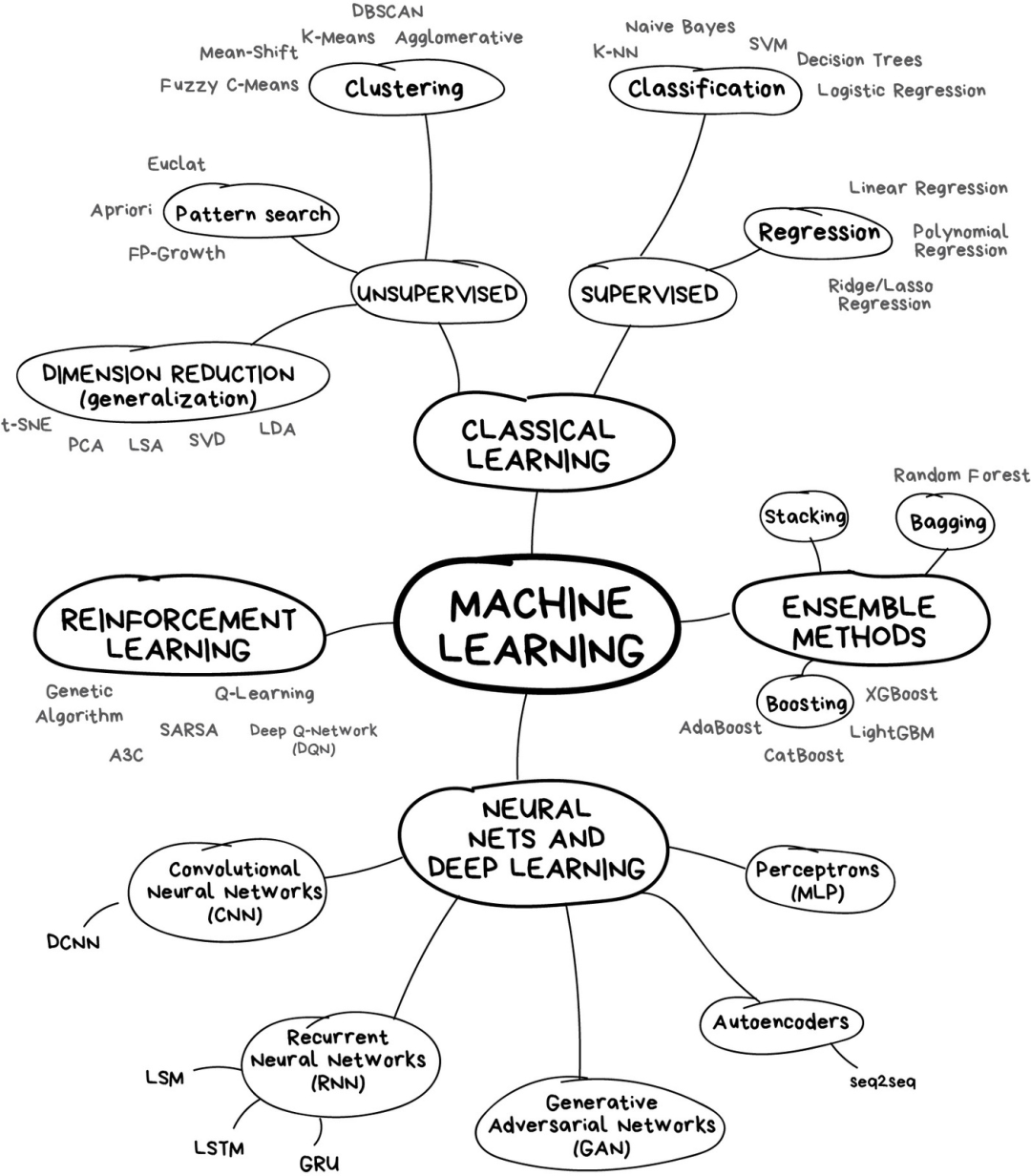
在机器学习的世界里,解决问题的方法从来不是唯一的——记住这点很重要——因为你总会发现好几个算法都可以用来解决某个问题,你需要从中选择最适合的那个。当然,所有的问题都可以用“神经网络”来处理,但是背后承载算力的硬件成本谁来负担呢?
我们先从一些基础的概述开始。目前机器学习主要有4个方向。
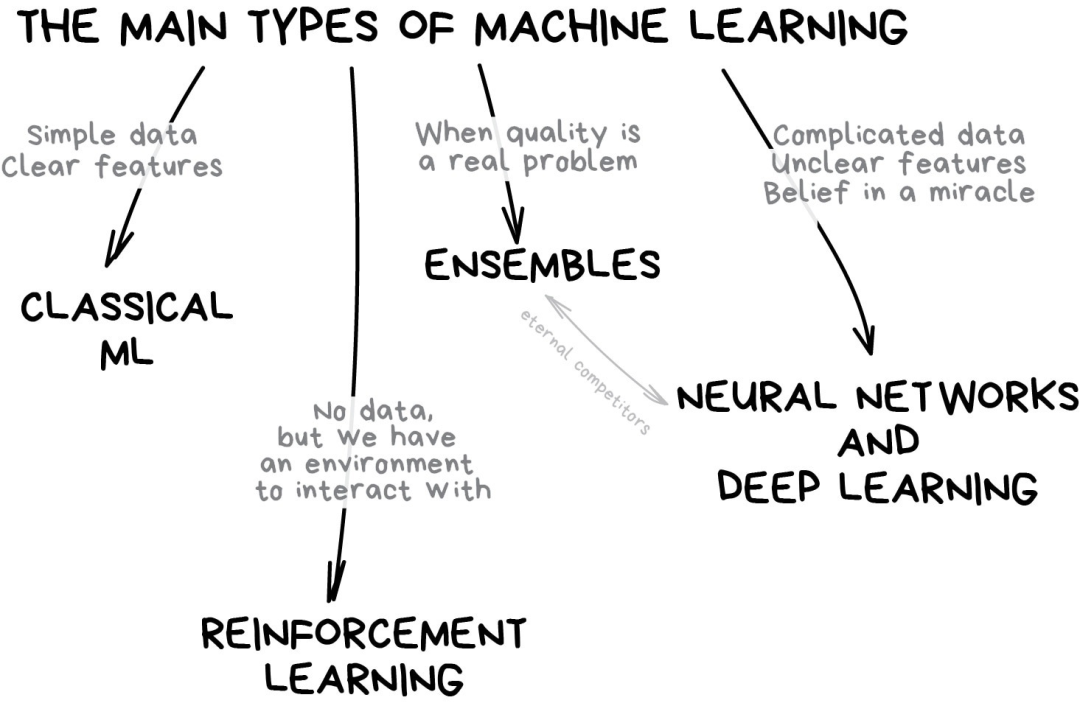
Part 1
经典机器学习算法
经典机器学习算法源自1950年代的纯统计学。统计学家们解决的是诸如寻找数字中的模式、估计数据点间的距离以及计算向量方向这样的形式数学(formal math)问题。
今天,一半的互联网都在研究这些算法。当你看到一列“继续阅读”的文章,或者在某个偏僻的加油站发现自己的银行卡被锁定而无法使用时,很可能是其中的一个小家伙干的。
大型科技公司是神经网络的忠实拥趸。原因显而易见,对于这些大型企业而言,2%的准确率提升意味着增加20亿的收入。但是公司业务体量小时,就没那么重要了。我听说有团队花了1年时间来为他们的电商网站开发新的推荐算法,事后才发现网站上99%的流量都来自搜索引擎——他们搞出来的算法毫无用处,毕竟大部分用户甚至都不会打开主页。
尽管经典算法被广泛使用,其实原理很简单,你可以很容易地解释给一个蹒跚学步的孩子听。它们就像是基本的算术——我们每天都在用,甚至连想都不想。
1.1 有监督学习
经典机器学习通常分为两类:有监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。
在“有监督学习”中,有一个“监督者”或者“老师”提供给机器所有的答案来辅助学习,比如图片中是猫还是狗。“老师”已经完成数据集的划分——标注“猫”或“狗”,机器就使用这些示例数据来学习,逐个学习区分猫或狗。
无监督学习就意味着机器在一堆动物图片中独自完成区分谁是谁的任务。数据没有事先标注,也没有“老师”,机器要自行找出所有可能的模式。后文再讨论这些。
很明显,有“老师”在场时,机器学的更快,因此现实生活中有监督学习更常用到。有监督学习分为两类:
分类(classification),预测一个对象所属的类别; 回归(regression),预测数轴上的一个特定点;
分类(Classification)
“基于事先知道的一种属性来对物体划分类别,比如根据颜色来对袜子归类,根据语言对文档分类,根据风格来划分音乐。”
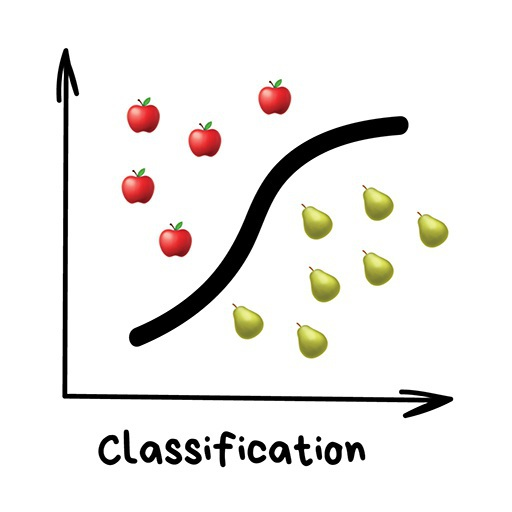
分类算法常用于:
过滤垃圾邮件; 语言检测; 查找相似文档; 情感分析 识别手写字母或数字 欺诈侦测
常用的算法:
朴素贝叶斯(Naive Bayes) 决策树(Decision Tree) Logistic回归(Logistic Regression) K近邻(K-Nearest Neighbours) 支持向量机(Support Vector Machine)
机器学习主要解决“分类”问题。这台机器好比在学习对玩具分类的婴儿一样:这是“机器人”,这是“汽车”,这是“机器-车”……额,等下,错误!错误!
在分类任务中,你需要一名“老师”。数据需要事先标注好,这样机器才能基于这些标签来学会归类。一切皆可分类——基于兴趣对用户分类,基于语言和主题对文章分类(这对搜索引擎很重要),基于类型对音乐分类(Spotify播放列表),你的邮件也不例外。
朴素贝叶斯算法广泛应用于垃圾邮件过滤。机器分别统计垃圾邮件和正常邮件中出现的“伟哥”等字样出现的频次,然后套用贝叶斯方程乘以各自的概率,再对结果求和——哈,机器就完成学习了。
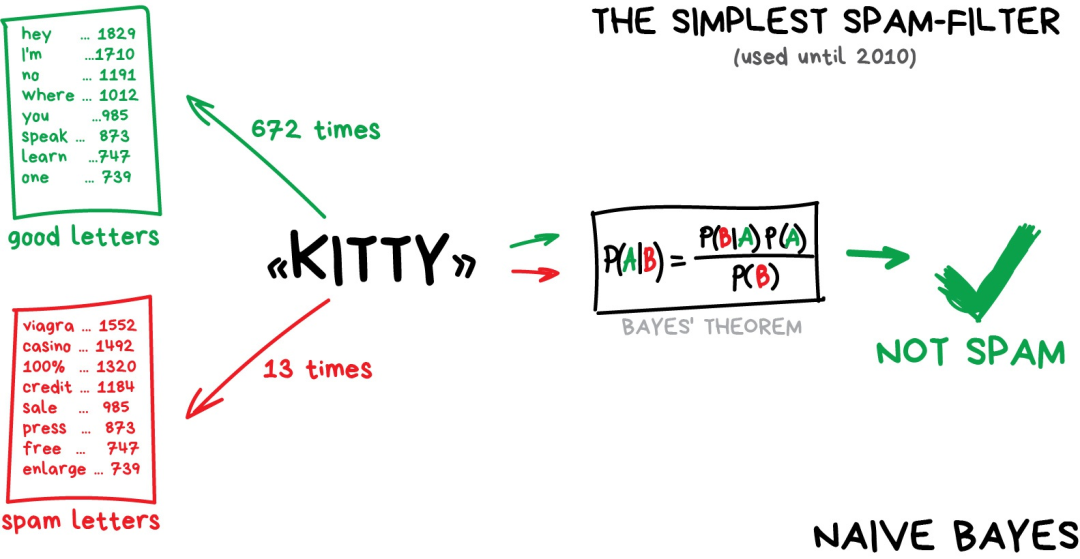
后来,垃圾邮件制造者学会了如何应对贝叶斯过滤器——在邮件内容后面添加很多“好”词——这种方法被讽称为“贝叶斯中毒”(Bayesian poisoning)。朴素贝叶斯作为最优雅且是第一个实用的算法而载入历史,不过现在有其他算法来处理垃圾邮件过滤问题。
再举一个分类算法的例子。
假如现在你需要借一笔钱,那银行怎么知道你将来是否会还钱呢?没法确定。但是银行有很多历史借款人的档案,他们拥有诸如“年龄”、“受教育程度”、“职业”、“薪水”以及——最重要的——“是否还钱”这些数据。
利用这些数据,我们可以训练机器找到其中的模式并得出答案。找出答案并不成问题,问题在于银行不能盲目相信机器给出的答案。如果系统出现故障、遭遇黑客攻击或者喝高了的毕业生刚给系统打了个应急补丁,该怎么办?
要处理这个问题,我们需要用到决策树(Decision Trees),所有数据自动划分为“是/否”式提问——比如“借款人收入是否超过128.12美元?”——听起来有点反人类。不过,机器生成这样的问题是为了在每个步骤中对数据进行最优划分。
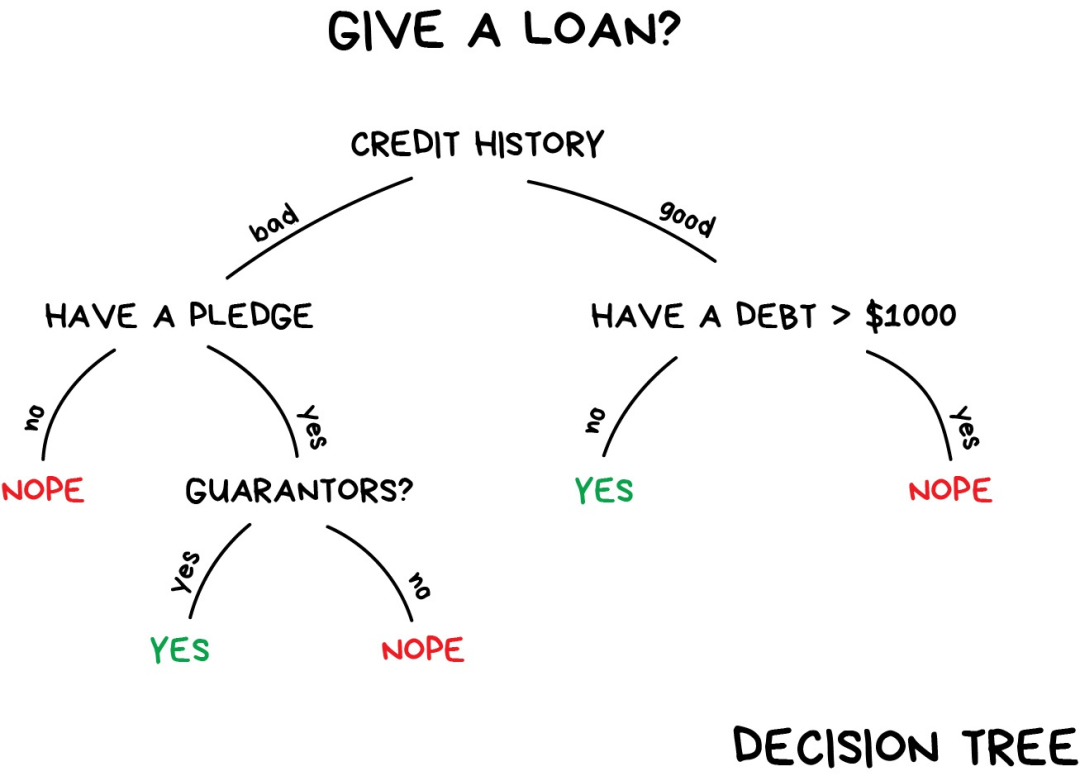
“树”就是这样产生的。分支越高(接近根节点),问题的范围就越广。所有分析师都能接受这种做法并在事后给出解释,即使他并不清楚算法是怎么回事,照样可以很容易地解释结果(典型的分析师啊)!
决策树广泛应用于高责任场景:诊断、医药以及金融领域。
最广为人知的两种决策树算法是 CART 和 C4.5.
如今,很少用到纯粹的决策树算法。不过,它们是大型系统的基石,决策树集成之后的效果甚至比神经网络还要好。这个我们后面再说。
当你在Google上搜索时,正是一堆笨拙的“树”在帮你寻找答案。搜索引擎喜欢这类算法,因为它们运行速度够快。
按理说,支持向量机(SVM) 应该是最流行的分类方法。只要是存在的事物都可以用它来分类:对图片中的植物按形状归类,对文档按类别归类等。
SVM背后的思想很简单——它试图在数据点之间绘制两条线,并尽可能最大化两条线之间的距离。如下图示:
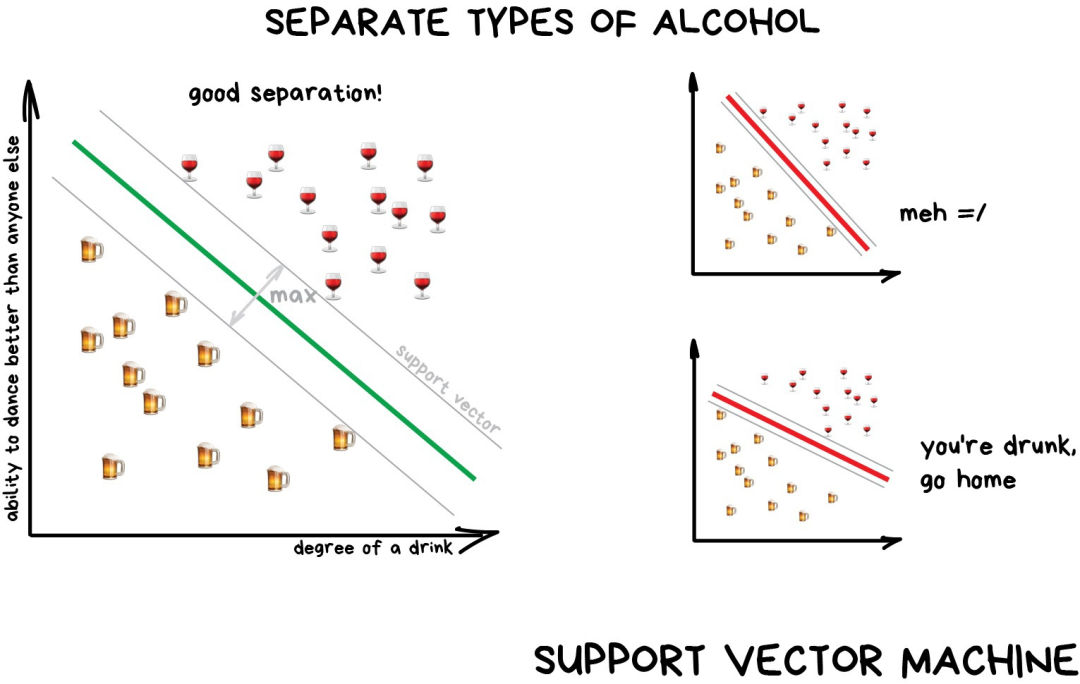
分类算法有一个非常有用的场景——异常检测(anomaly detection),如果某个特征无法分配到所有类别上,我们就把它标出来。现在这种方法已经用于医学领域——MRI(磁共振成像)中,计算机会标记检测范围内所有的可疑区域或者偏差。股票市场使用它来检测交易人的异常行为以此来找到内鬼。在训练计算机分辨哪些事物是正确时,我们也自动教会其识别哪些事物是错误的。
经验法则(rule of thumb)表明,数据越复杂,算法就越复杂。对于文本、数字、表格这样的数据,我会选择经典方法来操作。这些模型较小,学习速度更快,工作流程也更清晰。对于图片、视频以及其他复杂的大数据,我肯定会研究神经网络。
就在5年前,你还可以找到基于SVM的人脸分类器。现在,从数百个预训练好的神经网络模型中挑选一个模型反而更容易。不过,垃圾邮件过滤器没什么变化,它们还是用SVM编写的,没什么理由去改变它。甚至我的网站也是用基于SVM来过滤评论中的垃圾信息的。
回归(Regression)
“画一条线穿过这些点,嗯~这就是机器学习”
回归算法目前用于:
股票价格预测 供应和销售量分析 医学诊断 计算时间序列相关性
线性回归(Linear Regression) 多项式回归(Polynomial Regression)
“回归”算法本质上也是“分类”算法,只不过预测的是不是类别而是一个数值。比如根据行驶里程来预测车的价格,估算一天中不同时间的交通量,以及预测随着公司发展供应量的变化幅度等。处理和时间相关的任务时,回归算法可谓不二之选。
回归算法备受金融或者分析行业从业人员青睐。它甚至成了Excel的内置功能,整个过程十分顺畅——机器只是简单地尝试画出一条代表平均相关的线。不过,不同于一个拿着笔和白板的人,机器是通过计算每个点与线的平均间隔这样的数学精确度来完成的这件事。
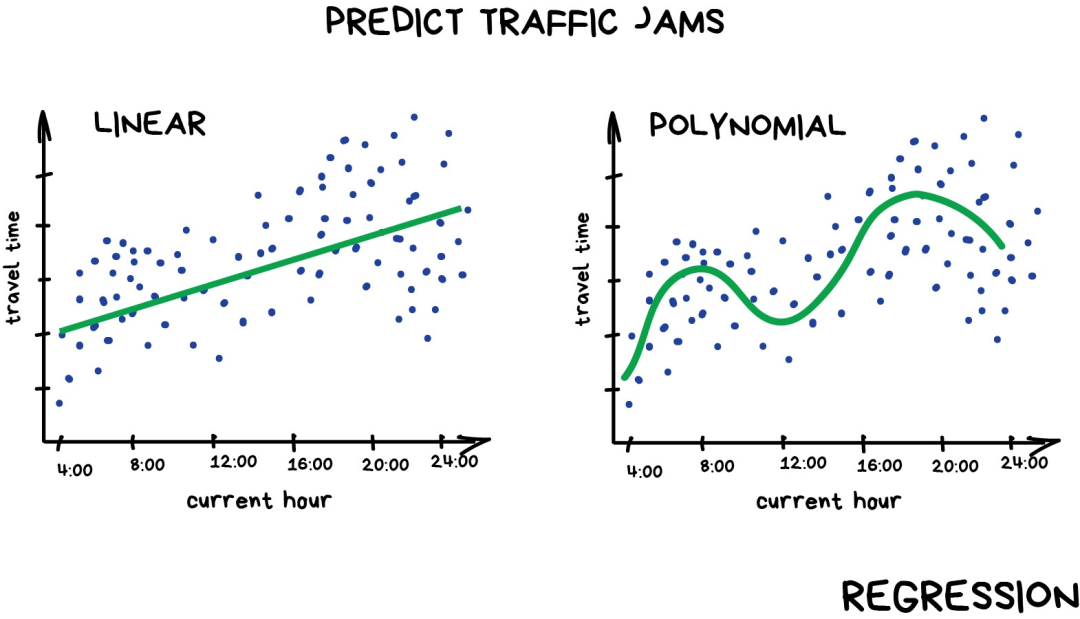
如果画出来的是直线,那就是“线性回归”,如果线是弯曲的,则是“多项式回归”。它们是回归的两种主要类型。其他类型就比较少见了。不要被Logistics回归这个“害群之马”忽悠了,它是分类算法,不是回归。
不过,把“回归”和“分类”搞混也没关系。一些分类器调整参数后就变成回归了。除了定义对象的类别外,还要记住对象有多么的接近该类别,这就引出了回归问题。
如果你想深入研究,可以阅读文章《写给人类的机器学习》[1](强烈推荐)。
1.2 无监督学习
无监督学习比有监督学习出现得稍晚——在上世纪90年代,这类算法用的相对较少,有时候仅仅是因为没得选才找上它们。
有标注的数据是很奢侈的。假设现在我要创建一个——比如说“公共汽车分类器”,那我是不是要亲自去街上拍上几百万张该死的公共汽车的照片,然后还得把这些图片一一标注出来?没门,这会花费我毕生时间,我在Steam上还有很多游戏没玩呢。
这种情况下还是要对资本主义抱一点希望,得益于社会众包机制,我们可以得到数百万便宜的劳动力和服务。比如Mechanical Turk[2],背后是一群随时准备为了获得0.05美元报酬来帮你完成任务的人。事情通常就是这么搞定的。
或者,你可以尝试使用无监督学习。但是印象中,我不记得有什么关于它的最佳实践。无监督学习通常用于探索性数据分析(exploratory data analysis),而不是作为主要的算法。那些拥有牛津大学学位且经过特殊训练的人给机器投喂了一大堆垃圾然后开始观察:有没有聚类呢?没有。可以看到一些联系吗?没有。好吧,接下来,你还是想从事数据科学工作的,对吧?
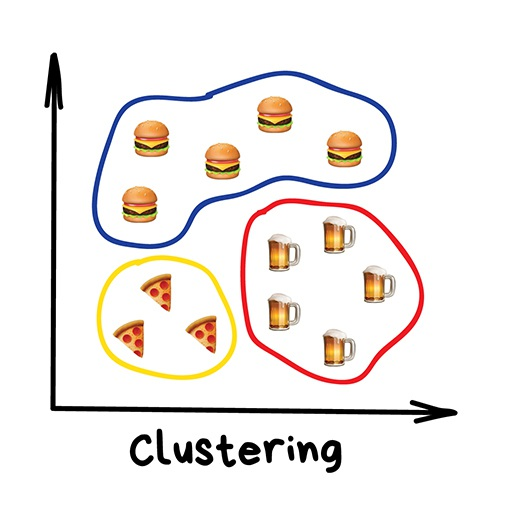
聚类(Clustering)
“机器会选择最好的方式,基于一些未知的特征将事物区分开来。”
聚类算法目前用于:
市场细分(顾客类型,忠诚度) 合并地图上邻近的点 图像压缩 分析和标注新的数据 检测异常行为
K均值聚类 Mean-Shift DBSCAN
聚类是在没有事先标注类别的前提下来进行类别划分。好比你记不住所有袜子的颜色时照样可以对袜子进行分类。聚类算法试图找出相似的事物(基于某些特征),然后将它们聚集成簇。那些具有很多相似特征的对象聚在一起并划分到同一个类别。有的算法甚至支持设定每个簇中数据点的确切数量。
这里有个示范聚类的好例子——在线地图上的标记。当你寻找周围的素食餐厅时,聚类引擎将它们分组后用带数字的气泡展示出来。不这么做的话,浏览器会卡住——因为它试图将这个时尚都市里所有的300家素食餐厅绘制到地图上。
Apple Photos和Google Photos用的是更复杂的聚类方式。通过搜索照片中的人脸来创建你朋友们的相册。应用程序并不知道你有多少朋友以及他们的长相,但是仍可以从中找到共有的面部特征。这是很典型的聚类。
另一个常见的应用场景是图片压缩。当图片保存为PNG格式时,可以将色彩设置为32色。这就意味着聚类算法要找出所有的“红色”像素,然后计算出“平均红色”,再将这个均值赋给所有的红色像素点上。颜色更少,文件更小——划算!
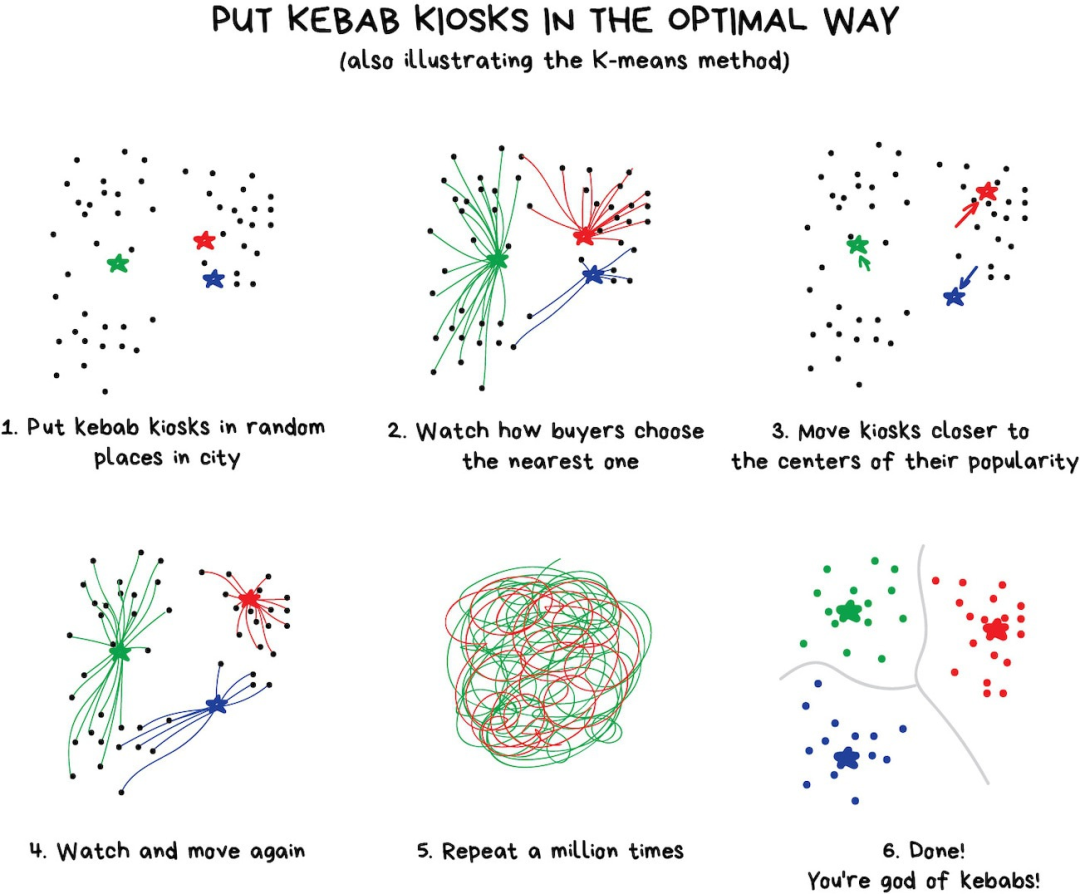
但是,遇到诸如 这样的颜色时就麻烦了。这是绿色还是蓝色?此时就需要K-Means算法出场啦。
先随机从色彩中选出32个色点作为“簇心”,剩余的点按照最近的簇心进行标记。这样我们就得到了围绕着32个色点的“星团”。接着我们把簇心移动到“星团”的中心,然后重复上述步骤知道簇心不再移动为止。
完工。刚好聚成32个稳定的簇形。
给大家看一个现实生活中的例子:
寻找簇心这种方法很方便,不过,现实中的簇并不总是圆形的。假如你是一名地质学家,现在需要在地图上找出一些类似的矿石。这种情形下,簇的形状会很奇怪,甚至是嵌套的。甚至你都不知道会有多少个簇,10个?100个?
K-means算法在这里就派不上用场了,但是DBSCAN算法用得上。我们把数据点比作广场上的人,找到任何相互靠近的3个人请他们手拉手。接下来告诉他们抓住能够到的邻居的手(整个过程人的站立位置不能动),重复这个步骤,直到新的邻居加入进来。这样我们就得到了第一个簇,重复上述过程直到每个人都被分配到簇,搞定。
一个意外收获:一个没有人牵手的人——异常数据点。
整个过程看起来很酷。

有兴趣继续了解下聚类算法?可以阅读这篇文章《数学科学家需要知道的5种聚类算法》[3].
就像分类算法一样,聚类可以用来检测异常。用户登陆之后的有不正常的操作?让机器暂时禁用他的账户,然后创建一个工单让技术支持人员检查下是什么情况。说不定对方是个“机器人”。我们甚至不必知道“正常的行为”是什么样,只需把用户的行为数据传给模型,让机器来决定对方是否是个“典型的”用户。
这种方法虽然效果不如分类算法那样好,但仍值得一试。
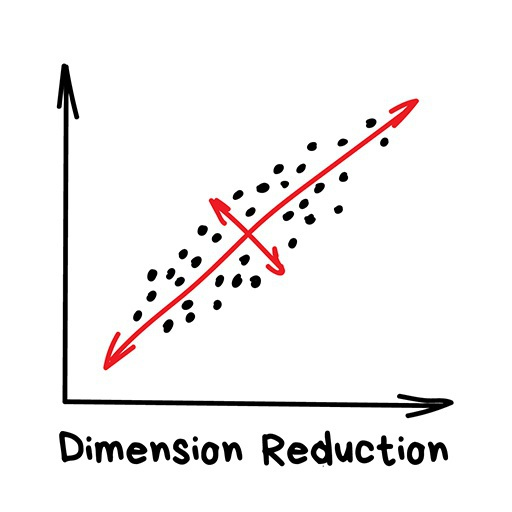
降维(Dimensionality Reduction)
“将特定的特征组装成更高级的特征 ”
“降维”算法目前用于:
推荐系统 漂亮的可视化 主题建模和查找相似文档 假图识别 风险管理
主成分分析(Principal Component Analysis ,PCA) 奇异值分解(Singular Value Decomposition ,SVD) 潜在狄里克雷特分配( Latent Dirichlet allocation, LDA) 潜在语义分析( Latent Semantic Analysis ,LSA, pLSA, GLSA), t-SNE (用于可视化)
早年间,“硬核”的数据科学家会使用这些方法,他们决心在一大堆数字中发现“有趣的东西”。Excel图表不起作用时,他们迫使机器来做模式查找的工作。于是他们发明了降维或者特征学习的方法。
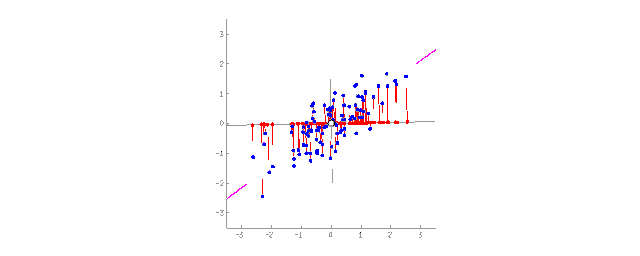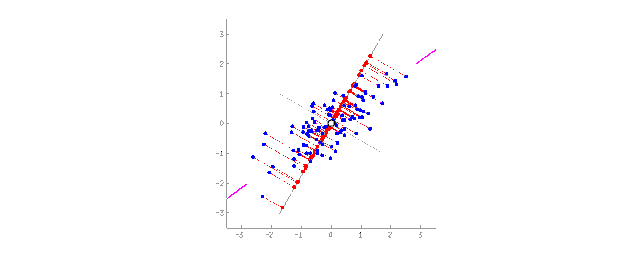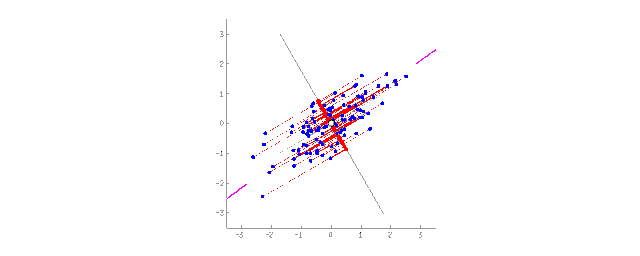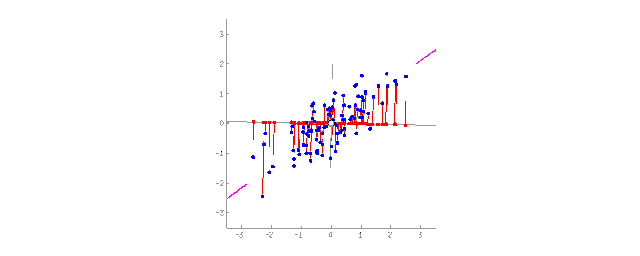
将2D数据投影到直线上(PCA)
对人们来说,相对于一大堆碎片化的特征,抽象化的概念更加方便。举个例子,我们把拥有三角形的耳朵、长长的鼻子以及大尾巴的狗组合出“牧羊犬”这个抽象的概念。相比于特定的牧羊犬,我们的确丢失了一些信息,但是新的抽象概念对于需要命名和解释的场景时更加有用。作为奖励,这类“抽象的”模型学习速度更快,训练时用到的特征数量也更少,同时还减少了过拟合。
这些算法在“主题建模”的任务中能大显身手。我们可以从特定的词组中抽象出他们的含义。潜在语义分析(LSA)就是搞这个事情的,LSA基于在某个主题上你能看到的特定单词的频次。比如说,科技文章中出现的科技相关的词汇肯定更多些,或者政治家的名字大多是在政治相关的新闻上出现,诸如此类。
我们可以直接从所有文章的全部单词中来创建聚类,但是这么做就会丢失所有重要的连接(比如,在不同的文章中battery 和 accumulator的含义是一样的),LSA可以很好地处理这个问题,所以才会被叫做“潜在语义”(latent semantic)。
因此,需要把单词和文档连接组合成一个特征,从而保持其中的潜在联系——人们发现奇异值分解(SVD)能解决这个问题。那些有用的主题簇很容易从聚在一起的词组中看出来。

推荐系统和协同过滤是另一个高频使用降维算法的领域。如果你用它从用户的评分中提炼信息,你就会得到一个很棒的系统来推荐电影、音乐、游戏或者你想要的任何东西。
这里推荐一本我最爱的书《集体编程智慧》(Programming Collective Intelligence),它曾是我大学时代的枕边书。
要完全理解这种机器上的抽象几乎不可能,但可以留心观察一些相关性:有些抽象概念和用户年龄相关——小孩子玩“我的世界”或者观看卡通节目更多,其他则可能和电影风格或者用户爱好有关。
仅仅基于用户评分这样的信息,机器就能找出这些高等级的概念,甚至不用去理解它们。干得漂亮,电脑先生。现在我们可以写一篇关于“为什么大胡子的伐木工喜欢我的小马驹”的论文了。
关联规则学习(Association rule learning)
“在订单流水中查找模式”
“关联规则”目前用于:
预测销售和折扣 分析“一起购买”的商品 规划商品陈列 分析网页浏览模式
常用的算法:
Apriori Euclat FP-growth
用来分析购物车、自动化营销策略以及其他事件相关任务的算法都在这儿了。如果你想从某个物品序列中发现一些模式,试试它们吧。
比如说,一位顾客拿着一提六瓶装的啤酒去收银台。我们应该在结账的路上摆放花生吗?人们同时购买啤酒和花生的频次如何?是的,关联规则很可能适用于啤酒和花生的情形,但是我们还可以用它来预测其他哪些序列? 能否做到在商品布局上的作出微小改变就能带来利润的大幅增长?
这个思路同样适用电子商务,那里的任务更加有趣——顾客下次要买什么?
不知道为啥规则学习在机器学习的范畴内似乎很少提及。经典方法是在对所有购买的商品进行正面检查的基础上套用树或者集合方法。算法只能搜索模式,但没法在新的例子上泛化或再现这些模式。
现实世界中,每个大型零售商都会建立了自己专属的解决方案,所以这里不会为你带来革命。本文提及的最高水平的技术就是推荐系统。不过,我可能没意识到这方面有什么突破。如果你有什么想分享的,请在评论中告诉我。

推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!