
15分钟看完:悉尼科技大学入选 CVPR 2021 的 9 篇论文,都研究什么?
共 6944字,需浏览 14分钟
·
2021-03-14 22:11

极市导读
本次接收论文共13篇,其中3篇oral,节选汇总了悉尼科技大学ReLER被本届CVPR接收的9篇论文,涉及领域包括语义分割,迁移学习,多模态识别,点云处理,网络结构搜索,姿势识别等。作者还在持续更新中~ >>加入极市CV技术交流群,走在计算机视觉的最前沿
近日,全球计算机视觉顶级会议 IEEE CVPR 2021(Computer Vision and Pattern Recognition) 即将于今年六月召开,本届大会总共录取来自全球论文 1663 篇。CVPR 作为计算机视觉领域级别最高的研究会议,其录取论文代表了计算机视觉领域在 2021 年最新和最高的科技水平以及未来发展潮流。
悉尼科技大学ReLER实验室共有13篇论文被本届 CVPR 大会接收,其中包括口头报告论文 3 篇。部分录取论文和百度,亚马逊等公司合作,在以下领域实现进展:语义分割,迁移学习,多模态识别,点云处理,网络结构搜索,姿势识别等。
1, Point 4D Transformer Networks for Spatio-Temporal Modeling in Point Cloud Videos [Oral]
Hehe Fan, Yi Yang and Mohan Kankanhalli
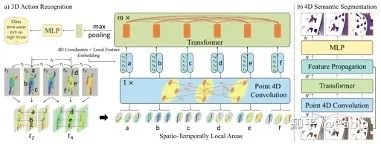
从2020年起,激光雷达(LiDAR)开始从大功率、价格昂贵走向低功耗、廉价和便携。例如微软推出了Azure Kinect (399美元),英特尔旗下的RealSense推出了L515(349美元),苹果在2020款的iPad Pro和iPhone Pro也搭载了LiDAR,使得LiDAR从无人车迈向日常应用。随着LiDAR的普及,三维点云 (3D Point Cloud)超出了无人车驾驶领域、开始在整个计算机视觉中得到广泛应用。点云本质上是无序、不规则的三维坐标集合{(x,y,z)}。比如{(1,1,1), (2,2,2), (3,3,3)}和{(2,2,2), (3,3,3), (1,1,1)}代表的是同一点云。如果可同时获得点的颜色等特征,可生成类似key-value的数据{(x,y,z: feature)}。不同于基于有序、规则像素网格的传统图像,这种无序、不规则的数据对深度神经网络提出了极大挑战。更为严重的是,在学习动态点云时,单帧点云的无序使得点在整个视频里出现的顺序无法做到一致。虽然可采用point tracking来获取点的轨迹,但tracking本身就极具挑战,很难获得准确的轨迹。因此,在这篇论文里,我们采用了Transformer,这一non-local技术来避免显式地track points(另一技术是建立spatio-temporal hierarchy,发表在ICLR2021的我们一篇名叫PSTNet [1] 的论文里)。我们的方法在3D action recognition和4D semantic segmentation上获得了不错的性能。
[1] PSTNet: Point Spatio-Temporal Convolution on Point Cloud Sequences
2, Faster Meta Update Strategy for Noise-Robust Deep Learning [Oral]
Youjiang Xu, Linchao Zhu, Lu Jiang, Yi Yang
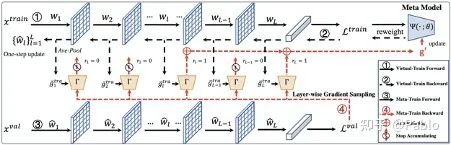
基于meta-learning的方法在有噪声标注的图像分类中取得了显著的效果。这类方法往往需要大量的计算资源,而计算瓶颈在于meta-gradient的计算上。本文提出了一种高效的meta-learning更新方式:Faster Meta Update Strategy (FaMUS),加快了meta-learning的训练速度 (减少2/3的训练时间),并提升了模型的性能。首先,我们发现meta-gradient的计算可以转换成一个逐层计算并累计的形式; 并且,meta-learning的更新只需少量层数在meta-gradient就可以完成。基于此,我们设计了一个layer-wise gradient sampler 加在网络的每一层上。根据sampler的输出,模型可以在训练过程中自适应地判断是否计算并收集该层网络的梯度。越少层的meta-gradient需要计算,网络更新时所需的计算资源越少,从而提升模型的计算效率。
并且,我们发现FaMUS使得meta-learning更加稳定,从而提升了模型的性能。最后,我们在有噪声的分类问题以及长尾分类问题都验证了我们方法的有效性。
3, VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild
Jiaxu Miao, Yu Wu, Chen Liang, Guangrui Li, Yunchao Wei, Yi Yang
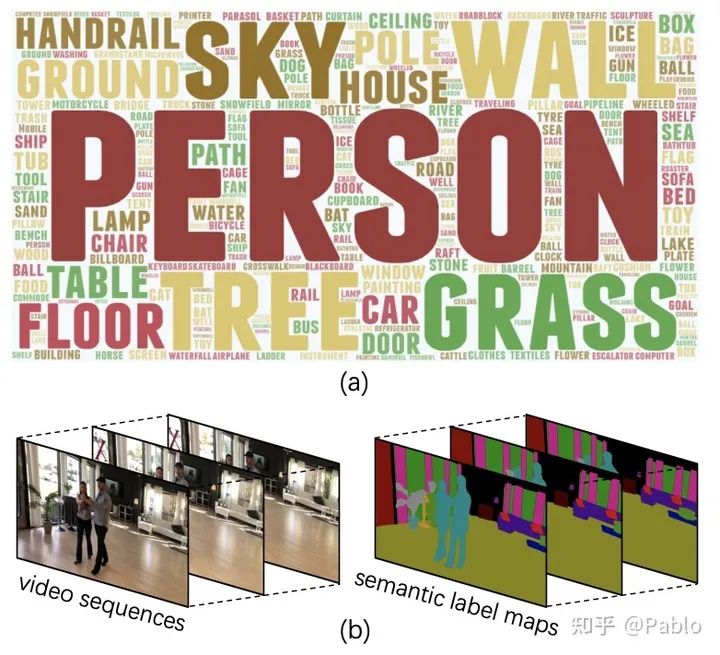
语义分割是计算机视觉领域的一个基本任务。近年来,图像语义分割方法已经有了长足的发展,而对视频语义分割的探索比较有限,一个原因是缺少足够规模的视频语义分割数据集。本文提出了一个大规模视频语义分割数据集,VSPW。VSPW 数据集有着以下特点:(1)大规模、多场景标注。本数据集共标注3536个视频,251632帧语义分割图片,涵盖了124个语义类别,标注数量远超之前的语义分割数据集(Cityscapes, CamVid)。与之前数据集仅关注街道场景不同,本数据集覆盖超过200种视频场景,极大丰富了数据集的多样性。(2)密集标注。之前数据集对视频数据标注很稀疏,比如Cityscapes,在30帧的视频片段中仅标注其中一帧。VSPW 数据集按照15f/s的帧率对视频片段标注,提供了更密集的标注数据。(3)高清视频标注。本数据集中,超过96%的视频数据分辨率在720P至4K之间。与图像语义分割相比,视频语义分割带来了新的挑战,比如,如何处理动态模糊的帧、如何高效地利用时序信息预测像素语义、如何保证预测结果时序上的稳定等等。
本文提供了一个基础的视频语义分割算法,利用时序的上下文信息来提升分割精度。同时,本文还提出了针对视频分割时序稳定性的新的度量标准。期待VSPW 能促进针对视频语义分割领域的新算法不断涌现,解决上文提出的视频语义分割带来的新挑战。
4, Domain Consensus Clustering for Universal Domain Adaptation
Guangrui Li, Guoliang Kang, Yi Zhu, Yunchao Wei, Yi Yang
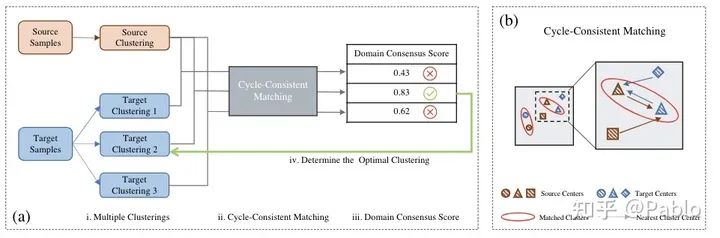
域适应问题是要将在一个有标注的域学习到的特征和表示迁移到另一个无标注的目标与中。在本文中,我们主要关注域适应问题在两个域的标签空间不对齐的情况下的特征迁移, 即两个域中都有从未在另一个域中出现的 ’未知类‘,这被称作通用域适应(Universal Domain Adaptation)。以往的文章中通常将’未知类‘当做一个类来处理,而忽略了其内在的分布。尤其是当’未知类‘较多的时候,简单得将其当做一个类会使得其在特征空间中不够紧凑,从而导致其与共有类混淆。为了解决这个问题,本文提出了域共识聚类(domain consensus clustering),来同时将共有类和未知类进行聚类,以更好的发掘隐空间(latent space)中的信息。具体来讲,我们首先在两个层面来计算域共识,语义层面,和样本层面。在语义层面,我们通过源域和目标域中聚类的最近邻一致性来识别可能的共有类的聚类(cycle-consistency)。在样本层面,我们设计了域共识分数(domain consensus score)来评估通过最近邻一致性匹配到的聚类的匹配程度。基于以上的设计,我们可以根据两个域的聚类间的匹配程度动态的调整目标域中聚类的数目,从而在完全没有先验信息和标注的情况下在目标域进行聚类。实验 证明我们的方法具有很好地优越性和泛化性,在Universal/Open-set/Partial Domain Adaptation 三个场景下的多个数据集上达到了最优性能。
5, T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
Xiaohan Wang, Linchao Zhu, Yi Yang
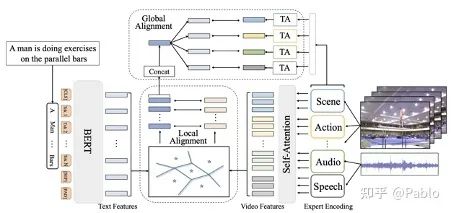
随着各种互联网视频尤其是短视频的火热,文本视频检索在近段时间获得了学术界和工业界的广泛关注。特别是在引入多模态视频信息后,如何精细化地配准局部视频特征和自然语言特征成为一大难点。在近期的顶会上有一些优秀的工作通过解析query文本并利用cross- attention的思路做Matching来解决这一问题。但在实际应用过程中,Matching操作会带来巨大的计算开销。我们提出自动化学习文本和视频信息共享的语义中心,并对聚类后的局部特征做对应匹配,避免了复杂的计算,同时赋予了模型精细化理解语言和视频局部信息的能力。此外,我们的模型可以直接将多模态的视频信息(声音、动作、场景、speech、OCR、人脸等)映射到同一空间,利用同一组语义中心来做聚类融合,也在一定程度上解决了多模态信息难以综合利用的问题。我们的模型在三个标准的Text-Video Retrieval Dataset上均取得了SoTA。对比Google在ECCV 2020上的发表的最新工作MMT,我们的模型能在将运算时间降低一半的情况下,仅利用小规模标准数据集,在两个benchmark上超过MMT在亿级视频文本数据(Howto100M)上pretrain模型的检索结果。我们会在CVPR后在arxiv上挂出论文并开源代码,欢迎大家关注。
6, Exploring Heterogeneous Clues for Weakly-Supervised Audio-Visual Video Parsing
Yu Wu, Yi Yang
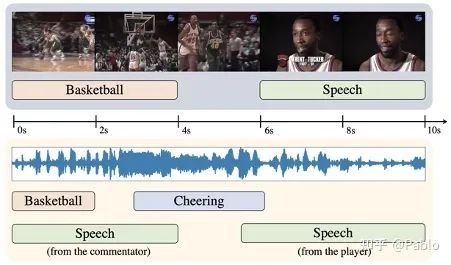
现有的音视频研究常常假设声音和视频信号中的事件是天然同步的,然而在日常视频中,同一时间可能音视频会存在不同的事件内容。比如一个视频画面播放的是足球赛,而声音听到的是解说员的话音。本文旨在精细化的研究分析视频中的事件,从视频和音频中分析出事件类别和其时间定位。我们针对通用视频,设计一套框架来从弱标签中学习这种精细化解析能力。该弱标签只是视频的标签(比如篮球赛、解说),并没有针对音视频轨道有区分标注,也没用时间位置标注。我们使用MIL(Multiple-instance Learning)来训练模型。然而,因为缺少时间标签,这种总体训练会损害网络的预测能力,可能在不同的时间上都会预测同样的事件。因此我们提出引入跨模态对比学习,来引导注意力网络关注到当前时刻的底层信息,避免被全局上下文信息主导。此外,我们希望能精准地分析出到底是视频还是音频中包含这个弱标签信息。因此,我们设计了一套通过交换音视频轨道来获取与模态相关的标签的算法,来去除掉模态无关的监督信号。具体来说,我们将一个视频与一个无关视频(标签不重合的视频)进行音视频轨道互换。我们对互换后的新视频进行标签预测。如果他对某事件类别的预测还是非常高的置信度,那么我们认为这个仅存的模态轨道里确实可能包含这个事件。否则,我们认为这个事件只在另一个模态中出现。通过这样的操作,我们可以为每个模态获取不同的标签。我们用这些改过的标签重新训练网络,避免了网络被模糊的全局标签误导,从而获得了更高的视频解析性能。
7, DSC-PoseNet: Learning 6DoF Object Pose Estimation via Dual-scale Consistency
Zongxin Yang, Xin Yu, Yi Yang
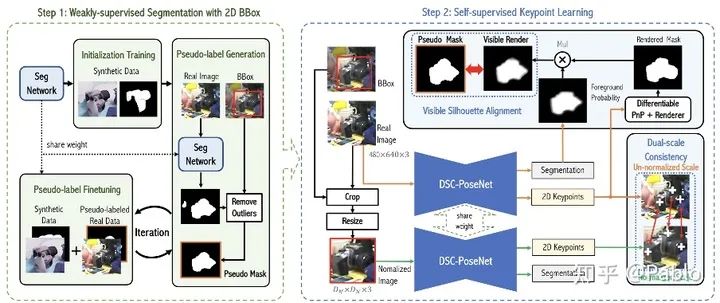
相比较于标注目标物体的二维外接框,人工标注三维姿态非常困难,特别是当物体的深度信息缺失的时候。为了减轻人工标注的压力,我们提出了一个两阶段的物体姿态估计框架来从物体的二维外接框中学习三维空间中的六自由度物体姿态。在第一阶段中,网络通过弱监督学习的方式从二维外接框中提取像素级别的分割掩模。在第二阶段中,我们设计了两种自监督一致性来训练网络预测物体姿态。这两种一致性分别为:1、双尺度预测一致性;2、分割-渲染的掩模一致性。为验证方法的有效性和泛化能力,我们在多个常用的基准数据集上进行了大量的实验。在只使用合成数据以及外接框标注的条件下,我们大幅超越了许多目前的最佳方法,甚至性能上达到了许多全监督方法的水平。
8, OpenMix: Reviving Known Knowledge for Discovering Novel Visual Categories in an Open World
Zhun Zhong, Linchao Zhu, Zhiming Luo, Shaozi Li, Yi Yang, Nicu Sebe
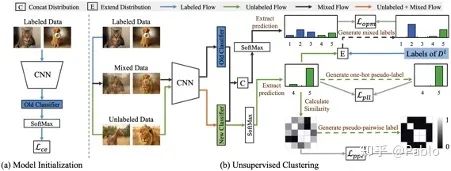
本文旨在解决``新类别发掘’’问题:给定已标注的数据集,识别出无标注数据集中未见过的类别(我们称之为新类别)。现有的方法通常只将已标注数据用于模型的预训练以提供一个较好的初始化特征,却忽略了其在新类别识别过程中的作用。本文着重于如何在识别新类别的过程中,利用已标注数据中的知识和监督信息,以提升模型对新类别的识别准确率。在本文中,我们提出了 OpenMix 方法,其特定地将已标注样本与无标注样本进行Mix操作,与此同时,我们将它们对应的标签(或伪标签)在一个联合标签分布下进行 Mix。OpenMix 使模型能够在识别新类别的训练过程中利用已标注数据的知识,从而生成具有更可信标签的训练样本,并有效防止模型过拟合到被错分类的样本中。此外,我们发现 OpenMix 使模型对具有高分类置信度的样本保持了一个很高的分类准确率。基于此,我们选取这些样本为 anchors,并将它们与其他样本进行 Mix 操作,使我们在新类中产生更多样的样本进行模型的训练。最后,我们在三个公开数据集中验证了OpenMix 的有效性,并取得了优于当前最好方法的性能。
9, Removing Raindrops and Rain Streaks in One Go.
Ruijie Quan,Xin Yu,Yuanzhi Liang,Yi Yang
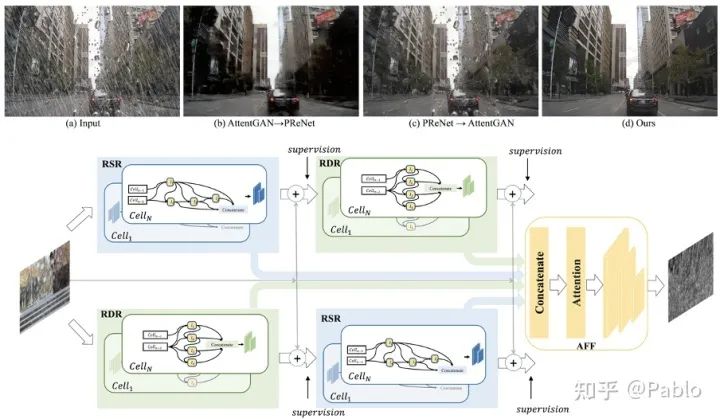
现有的去雨算法一般针对的是单一的去除雨线或者是去除雨滴问题,但是在现实场景中两种不同类型的雨往往同时存在。尤其是在下雨的自动驾驶场景中,空气中线条状的雨线和挡风玻璃上的椭圆形水滴都会严重影响车载摄像头捕捉的画面的清晰度,从而大幅降低了自动驾驶算法准确性。在这篇文章中,我们从以下两个方面去解决上述的现实生活中去雨问题。首先,我们设计一种complementary cascaded网络结构—CCN,能够在一个整体网络中以互补的方式去除两种形状和结构差异较大的雨。其次,目前公开数据集缺少同时含有雨线和雨滴的数据,对此我们提出了一个新的数据集RainDS,其中包括了雨线和雨滴数据以及它们相应的Ground Truth,并且该数据集同时包含了合成数据以及现实场景中拍摄的真实数据以用来弥合真实数据与合成数据之间的领域差异。实验表明,我们的方法在现有的雨线或者雨滴数据集以及提出的RainDS上都能实现很好的去雨效果。
推荐阅读
2021-03-09

2021-03-08

2021-03-07


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
