
用Keras写出像PyTorch一样的DataLoader方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

数据导入、网络构建和模型训练永远是深度学习代码的主要模块。笔者此前曾写过PyTorch数据导入的pipeline标准结构总结PyTorch数据Pipeline标准化代码模板,本文参考PyTorch的DataLoader,给Keras也总结一套自定义的DataLoader框架。

Keras常规用法
按照正常人使用Keras的方法,大概就像如下代码一样:
import numpy as npfrom keras.models import Sequential# 导入全部数据X, y = np.load('some_training_set_with_labels.npy')# Design modelmodel = Sequential()[...] # 网络结构model.compile()# 模型训练model.fit(x=X, y=y)
虽然一次性导入训练数据一定程度上能够提高训练速度,但随着数据量增多,这种将数据一次性读入内存的方法很容易造成显存溢出的问题。所以,在开启一个深度学习项目时,一个较为明智的做法就是分批次读取训练数据。
数据存放方式
常规情况下,我们的训练数据要么是按照分类和阶段有组织的存放在硬盘目录下(多见于比赛和标准数据集),要么以csv格式将数据路径和对应标签给出(多见于深度学习项目情形)。

数据按照类别和使用阶段存放(kaggle猫狗分类数据集)

数据按照csv文件形式给出(花朵分类数据集)
ImageDataGenerator
Keras早就考虑到了按批次导入数据的需求,所以ImageDataGenerator模块提供了按批次导入的数据生成器方法,包括数据增强和分批训练等方法。如下所示,分别对训练集和验证集调用ImageDataGenerator函数,然后从目录下按批次导入。
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 数据增强train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)# 从目录下按批次读取train_generator = train_datagen.flow_from_directory('data/train',target_size=(150, 150),batch_size=32,class_mode='binary')validation_generator = test_datagen.flow_from_directory('data/validation',target_size=(150, 150),batch_size=32,class_mode='binary')
最后对模型调用fit_generator方法进行训练:
model.fit_generator(train_generator,steps_per_epoch=2000,epochs=50,validation_data=validation_generator,validation_steps=800)
以上Keras提供的数据生成器的方法读入数据虽然好,但还不够灵活,实际深度学习项目会碰到各种不同的数据存放情况,根据实际情况来自定义一套类似于PyTorch的DataLoader非常有必要。
Keras Sequence
Keras Sequence方法用于拟合一个数据序列,每一个Sequence必须提供__getitem__和__len__方法,这跟Torch的Dataset模块类似。Sequence是进行多进程处理的更安全的方法,这种结构保证网络在每个时期每个样本只训练一次,这与生成器不同。使用示例如下:
from skimage.io import imreadfrom skimage.transform import resizeimport numpy as npfrom keras.utils import Sequence# x_set是图像的路径列表# y_set是对应的类别class CIFAR10Sequence(Sequence):def __init__(self, x_set, y_set, batch_size):self.x, self.y = x_set, y_setself.batch_size = batch_sizedef __len__(self):return int(np.ceil(len(self.x) / float(self.batch_size)))def __getitem__(self, idx):batch_x = self.x[idx * self.batch_size:(idx + 1) * self.batch_size]batch_y = self.y[idx * self.batch_size:(idx + 1) * self.batch_size]return np.array([ resize(imread(file_name), (200, 200)) for file_name in batch_x]), np.array(batch_y)
Torch风格的Keras DataLoader
现在我们针对一个13分类的多标签图像分类问题来自定义Torch风格的DataLoader。数据以csv的形式存放图片路径和对应标签,具体如下:
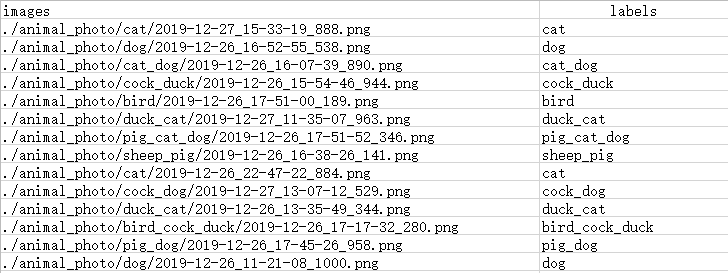
可以看到,每张图像都有至少一个、至多三个的动物标签。所以标签在处理的时候需要进行转化。首先定义继承Sequence的DataGenerator类和一些初始化方法。
class DataGenerator(Sequence):"""基于Sequence的自定义Keras数据生成器"""def __init__(self, df, list_IDs,to_fit=True, batch_size=8, dim=(256, 472),n_channels=3, n_classes=13, shuffle=True):""" 初始化方法:param df: 存放数据路径和标签的数据框:param list_IDs: 数据索引列表:param to_fit: 设定是否返回标签y:param batch_size: batch size:param dim: 图像大小:param n_channels: 图像通道:param n_classes: 标签类别:param shuffle: 每一个epoch后是否打乱数据"""self.df = dfself.list_IDs = list_IDsself.to_fit = to_fitself.batch_size = batch_sizeself.dim = dimself.n_channels = n_channelsself.n_classes = n_classesself.shuffle = shuffleself.on_epoch_end()
然后定义on_epoch_end方法来在每个epoch之后shuffle数据,以及底层数据读取和标签编码方法。
def on_epoch_end(self):"""每个epoch之后更新索引"""self.indexes = np.arange(len(self.list_IDs))if self.shuffle == True:np.random.shuffle(self.indexes)
图像读取方法:
def _load_image(self, image_path):"""cv2读取图像"""# img = cv2.imread(image_path)img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)w, h, _ = img.shapeif w>h:img = np.rot90(img)img = cv2.resize(img, (472, 256))return img
标签编码转换方法:
def _labels_encode(self, s, keys):"""标签one-hot编码转换"""cs = s.split('_')y = np.zeros(13)for i in range(len(cs)):for j in range(len(keys)):for c in cs:if c == keys[j]:y[j] = 1return y
然后定义每个批次生成图片和标签的方法:
def _generate_X(self, list_IDs_temp):"""生成每一批次的图像:param list_IDs_temp: 批次数据索引列表:return: 一个批次的图像"""# 初始化X = np.empty((self.batch_size, *self.dim, self.n_channels))# 生成数据for i, ID in enumerate(list_IDs_temp):# 存储一个批次X[i,] = self._load_image(self.df.iloc[ID].images)return Xdef _generate_y(self, list_IDs_temp):"""生成每一批次的标签:param list_IDs_temp: 批次数据索引列表:return: 一个批次的标签"""y = np.empty((self.batch_size, self.n_classes), dtype=int)# Generate datafor i, ID in enumerate(list_IDs_temp):# Store sampley[i,] = self._labels_encode(self.df.iloc[ID].labels, config.LABELS)return y
底层读取和生成方法定义完成后,即可定义__getitem__和__len__方法:
def __getitem__(self, index):"""生成每一批次训练数据:param index: 批次索引:return: 训练图像和标签"""# 生成批次索引indexes = self.indexes[index * self.batch_size:(index + 1) * self.batch_size]# 索引列表list_IDs_temp = [self.list_IDs[k] for k in indexes]# 生成数据X = self._generate_X(list_IDs_temp)if self.to_fit:y = self._generate_y(list_IDs_temp)return X, yelse:return Xdef __len__(self):"""每个epoch下的批次数量"""return int(np.floor(len(self.list_IDs) / self.batch_size))
完整的Keras DataLoader代码如下:
class DataGenerator(Sequence):"""基于Sequence的自定义Keras数据生成器"""def __init__(self, df, list_IDs,to_fit=True, batch_size=8, dim=(256, 472),n_channels=3, n_classes=13, shuffle=True):""" 初始化方法:param df: 存放数据路径和标签的数据框:param list_IDs: 数据索引列表:param to_fit: 设定是否返回标签y:param batch_size: batch size:param dim: 图像大小:param n_channels: 图像通道:param n_classes: 标签类别:param shuffle: 每一个epoch后是否打乱数据"""self.df = dfself.list_IDs = list_IDsself.to_fit = to_fitself.batch_size = batch_sizeself.dim = dimself.n_channels = n_channelsself.n_classes = n_classesself.shuffle = shuffleself.on_epoch_end()def __getitem__(self, index):"""生成每一批次训练数据:param index: 批次索引:return: 训练图像和标签"""# 生成批次索引indexes = self.indexes[index * self.batch_size:(index + 1) * self.batch_size]# 索引列表list_IDs_temp = [self.list_IDs[k] for k in indexes]# 生成数据X = self._generate_X(list_IDs_temp)if self.to_fit:y = self._generate_y(list_IDs_temp)return X, yelse:return Xdef __len__(self):"""每个epoch下的批次数量"""return int(np.floor(len(self.list_IDs) / self.batch_size))def _generate_X(self, list_IDs_temp):"""生成每一批次的图像:param list_IDs_temp: 批次数据索引列表:return: 一个批次的图像"""# 初始化X = np.empty((self.batch_size, *self.dim, self.n_channels))# 生成数据for i, ID in enumerate(list_IDs_temp):# 存储一个批次X[i,] = self._load_image(self.df.iloc[ID].images)return Xdef _generate_y(self, list_IDs_temp):"""生成每一批次的标签:param list_IDs_temp: 批次数据索引列表:return: 一个批次的标签"""y = np.empty((self.batch_size, self.n_classes), dtype=int)# Generate datafor i, ID in enumerate(list_IDs_temp):# Store sampley[i,] = self._labels_encode(self.df.iloc[ID].labels, config.LABELS)return ydef on_epoch_end(self):"""每个epoch之后更新索引"""self.indexes = np.arange(len(self.list_IDs))if self.shuffle == True:np.random.shuffle(self.indexes)def _load_image(self, image_path):"""cv2读取图像"""# img = cv2.imread(image_path)img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)w, h, _ = img.shapeif w>h:img = np.rot90(img)img = cv2.resize(img, (472, 256))return imgdef _labels_encode(self, s, keys):"""标签one-hot编码转换"""cs = s.split('_')y = np.zeros(13)for i in range(len(cs)):for j in range(len(keys)):for c in cs:if c == keys[j]:y[j] = 1return y
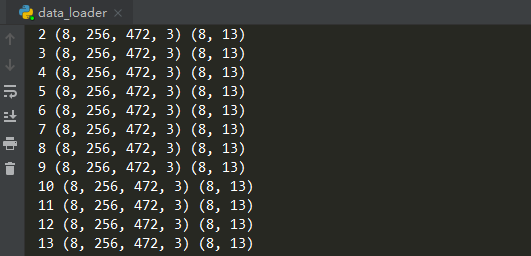
使用效果如下(打印每一批次输入输出的shape):
实际训练时,我们可以大致编写如下训练代码框架:
import numpy as npfrom keras.models import Sequentialimport DataGenerator# Parametersparams = {'batch_size': 64,'n_classes': 6,'n_channels': 1,'shuffle': True}# Generatorstraining_generator = DataGenerator(train_df, train_idx, **params)validation_generator = DataGenerator(val_df, val_idx, **params)# Design modelmodel = Sequential()[...] # Architecturemodel.compile()# Train model on datasetmodel.fit_generator(generator=training_generator,validation_data=validation_generator,use_multiprocessing=True,workers=4)
以上就是本文主要内容。本文提供的Keras DataLoader方法仅供参考使用,自定义Keras DataLoader还应根据具体数据组织形式来灵活决定。
参考资料:
https://towardsdatascience.com/keras-data-generators-and-how-to-use-them-b69129ed779c
小白团队出品:零基础精通语义分割↓↓↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~