
常用图像分类功能包
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
为了能够有效地识别位置,我们需要提取表征图像的特征,之后将相同的特征分成一组,并搜索相似的图像。当然位置识别也可以应用于其他程序,例如在图像恢复我们也需要查找相似图像。
Bag of Feature是一种图像特征提取方法。它借鉴了文本分类(Bag of Words)的思想,从图像中提取出许多具有代表性的关键词,形成字典,然后对每个图像中出现的关键词数量进行计数,以获得图片的特征向量。
获得特征向量后,我们通过聚类算法得到这些特征向量的聚类中心。将这些聚类中心组合在一起,形成字典。
对于图像中的每个特征,我们可以在字典中找到最相似的聚类中心,计算这些聚类中心的出现次数,并获得一个称为Bag的矢量表示。因此,对于区别越大的图片此矢量的区分度越大。
索引本地特征
为了获得词汇量,我们需要大量数据,即需要足够大的数据集。然后,对于每个图像,通常使用SIFT提取特征和描述符特征,并将其映射到描述符空间中。
提取特征后,使用一些聚类算法对这些特征向量进行聚类。最常用的聚类算法是k-means。它将样本数据的自然类别分为k个聚类,以便每个点都属于与最近的聚类中心相对应的聚类。用作聚类标准的类满足使聚类中心与属于该中心的数据点之间的平方距离之和最小的要求。
K-Means方法实际上需要确定两个参数c和δ。其中,ci表示每个聚类中心的位置,δij的值为{0,1},表示点xj是否分配给第i个聚类中心。
然后,目标函数可以编写如下。
为了优化ci,我们需要给出每个点所属的类,另一方面,为了优化δij,我们需要给我们聚类中心。
在实际使用中,K-Means的迭代过程实际上是EM算法的特例。K-Means算法的流程如下所示。

假设我们有N个样本点{ x 1,…,xN },并给出聚类数k。
首先,随机选择一系列聚类中心点μi,i = 1,…,k。然后,根据最近距离的原理为每个数据点指定相应的聚类中心,并计算新的数据点均值以更新聚类中心。如此反复,直到收敛。
聚类完成后,我们得到由这k个向量组成的字典。这k个向量具有称为视觉词的一般表达。
对于图像中的每个SIFT功能,我们都可以在字典中找到最相似的视觉单词。这样,我们可以计算一个k维直方图,它表示字典中图像的SIFT特征。
将视觉单词应用于图像检索
当我们使用进行图像搜索时,将会查看哪些视觉单词出现在该图像中。对于每个出现的单词,我们检查哪些其他图像具有相同的单词。对于有相同特征向量的图像,我们在数组计数器中添加一个。该数组是一个列表,其中每个图像都有一个包含计数器变量的变量。最后,我们将数组中计数器值最高的图像作为该图像的匹配项。
但是,图像中的每个功能仍需要与词汇表中的所有可视单词进行比较。加快此过程的解决方案是层次聚类。
分层聚类
代替聚类为k个聚类,可以将先聚类成b个类,然后将每个聚类再次聚类为b个聚类,依此类推。
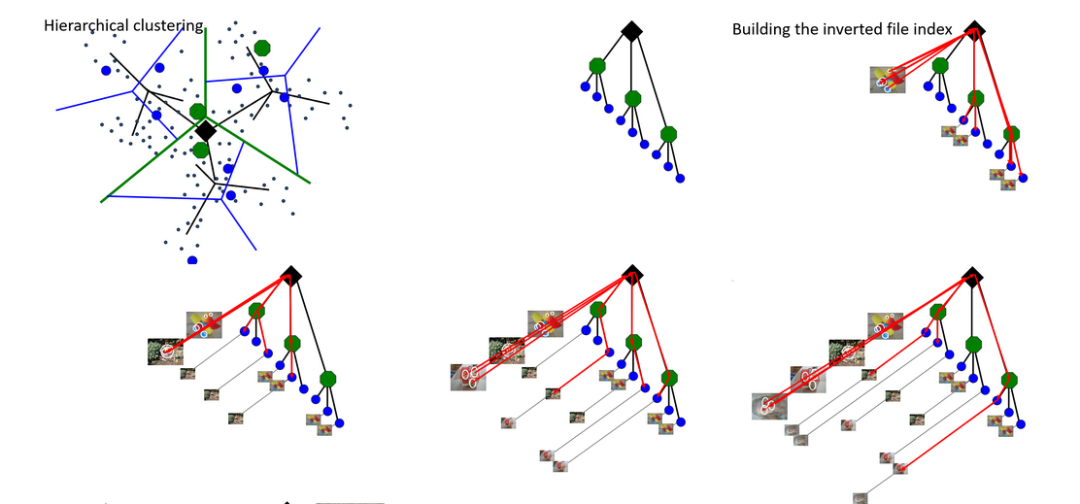
我们获得了一个类似树的结构,从而可以更快地进行视觉特征词的比较。对于每个特征向量,沿着该聚类树向下到达叶子节点,然后该叶子节点描述了视觉单词。这也意味着我们不必将每个向量与每个视觉单词联系在一起。
结论
提取特征时,功能袋不需要学习相关的标签,因此是一种弱监督的学习方法,另一方面它根本不考虑特征之间的位置关系。
如果有几种可能的比赛是合理的,但仍然选择其中一项,因为它的得分要好一些,这尤其不幸。在这种情况下,找到一种有效的方法来区分可能的解决方案以找到最佳解决方案是有利的。如果我们还包括地心信息,我们可以克服这一问题。
参考资料
1. AmanbirSandhu and Aarti Kochhar Content Based Image Retrieval using Texture, Color and Shape for Image Analysis‘ Council for Innovative Research International Journal of Computers & Technology, vol.3, no. 1, pp.2277–3061,2012
2. Arnold W.M Smeulders, Marcel Worring and Amarnath Gupta Content based image retrieval at the end of the early years‘ IEEE Transactions on Pattern Analysis and Machine Intelligence ,vol. 22, no.12 pp. 1349–1380,2000
3. Arthi.K and Mr. J. Vijayaraghavan Content Based Image RetrievalAlgorithm Using Color Models‘, International Journal of Advanced Research in Computer and Communication Engineering,Vol. 2, Issue 3,pp.1346–1347,2013
4. Baddeti Syam and Yarravarappu Rao An effective similarity measure via genetic algorithm for content based image retrieval with extensive features‘ International Arab journal information technology vol.10 no.2 pp.143–153,2013
5. Bai Xue, Liu Wanjun Research of Image Retrieval Based on Color‘, International Forum on Computer Science-Technology and Applications, pp.283–286, 2009
6. Chin-Chen Chang and Tzu-Chuen Lu A Color-Based Image Retrieval Method Using Color Distribution and Common Bitmap‘ Springer, pp. 56–71, 2005
7. Chuen-Horng Lin, Rong-Tai Chen, Yung-Kuan Chan A smart content-based image retrieval system based on color and texture feature‘, Image and Vision Computing vol.27 pp. 658–665,2009
8. Clough, P and Sanderson, M. User experiments with the Eurovision cross-language image retrieval system‘ Journal of the American Society of Information Science and Technology, vol.57 no.5 pp.697 -708,2006
9. Deepika Nagthane Content Based Image Retrieval system Using K-Means Clustering Technique‘ International Journal of Computer Applications & Information Technology, vol. 3, no.1 pp.21–30,2013
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~