
2021 年 Elasticsearch 生态和技术峰会干货总结
共 5088字,需浏览 11分钟
·
2021-02-02 23:17
1、引言
2021年 Elasticsearch 生态和技术峰会已完美闭幕,本次峰会可谓大咖云集,精彩纷呈。
本文仅就下午场技术部分做一下梳理、提炼、总结,希望对没有来得及参加线上技术峰会的广大 Elastic 爱好者提供帮助。错过直播,但依然收获技术干货!
2、峰会技术关键词词云

3、技术会议主题
吴斌老师(Elastic中文社区副主席):基于流式计算平台搭建实时分析应用
李猛老师(力萌科技数据专家):Elasticsearch 基于 Pipeline 窗口函数实现实时聚合计算
白凡老师(尚德机构资深工程师):基于 Elasticsearch 的容器化编排实践
刘征老师(Elastic社区布道师):如何规划和执行威胁狩猎
魏子珺老师(阿里巴巴技术专家):Elasticsearch云原生内核建设之路
4、基于流式计算平台搭建实时分析应用(吴斌)
4.1 为什么要面向开源进行架构设计?
轻松定制化、业务专注、低学习成本。
由于代码公开,所以安全、合规、透明。
高度灵活性,无平台绑定。
4.2 流式计算平台架构剖析
如图所示,流式计算平台主要由分布式消息队列、分布式计算引擎、数据引擎三部分构成。
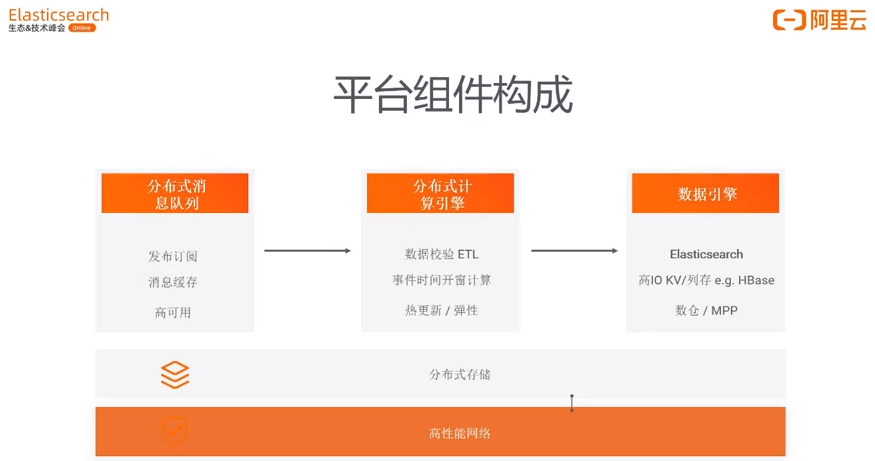
4.2.1 分布式消息队列
数据采集,支持消息分发、消息缓存
高可用,削峰填谷
4.2.2 分布式计算引擎
早期:MapReduce、Storm
当下主流:Flink、Storm2.0
支持热更新 / 弹性伸缩
计算引擎核心任务:
数据校验(数据格式、合法性、脏数据等)
数据清洗(数据 ETL 转换)
数据丰富(多维数据Join,以辅助数据分析)
4.2.3 数据引擎
热数据存储在 Elasticsearch、HBase。
其中 HBase 存储热数据非完全必要,除非高 IO 存储需要引入。
一般情况下,数据的分析:Elasticsearch 就能搞定。
温数据(超过 7天的数据)存储选型:
1)MPP
2)Hive,GreenPlum
4.2.4 分布式存储
云端的对象存储
文件输出、明细错误数据落地
快照 snapshot 等
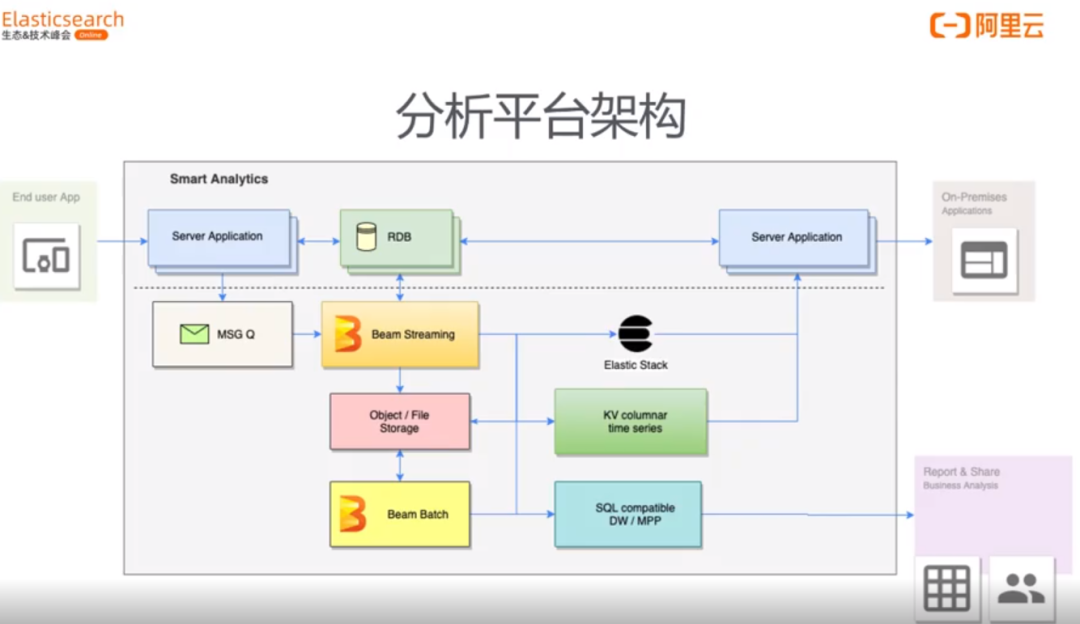
1)数据来源(server Application):服务器日志、监控、业务数据采集(如用户行为、购买记录、社交记录)。
2)数据发送到消息队列 (MSG G)。
3)消息队列数据写入 Beam Streaming 开源驱动引擎框架。
批流一体引擎。
Beam 能驱动:Flink、Spark Stream、 Strom 去做流式数据、batch 数据处理。
4)拉取RDB业务维表与实时数据Join。
5)对有问题数据输出到 Object 对象 / File 文件系统备份。
6)实时数据注入 Elasticsearch。
7)高 IO 数据写入 HBase(KV引擎)。
8)Beam Batch 批量处理。
核心Tips:
HBase + Elasticsearch 组合使用,以打车场景为例:
当打车订单未完成时候,明细数据(实时高 IO)录入HBase:
Session (订单)结束后,一个打车订单归拢为一条数据,放到 Elasticsearch,在 ES 中做实时订单分析、轨迹查询、客服查询等处理。
4.3 Elasticsearch 在流式平台中的角色功能

(1)文本检索
日志
场景:运维、开发、测试、客服。
(2)已知数据计算
已知数据定义:Mapping是我们自定义的。
实时指标计算。
场景:固定报表、大屏展示。
(3)未知线索探索
指标计算
复杂过滤条件
adhoc 查询
关联性、归因等
4.4 云原生与k8s集群管理经验分享(核心)

lass / On-prem:自己部署(实体机、虚拟机)大集群:维护升级麻烦,出错恢复周期非常长。
Sass:运维简单,具备弹性;缺点:细节不透明,网络拓扑受限,入口/网关性能、灵活性差,升级麻烦。
Pass (平台服务) / K8s
(1)优点:运维简单、yaml文件决定部署、弹性好、独享资源、官方operator。
(2)缺点:受限于K8s、开源版本,官方未来会推出商业版本。推荐:基于云托管K8s搭建ES集群。
为 Elasticsearch 量身定制的网关产品——极限网关
极限网关特性:
转发性能好。
支持多集群之间数据分流、同步。
支持网关级限流。

4.5 相关资源
Elasticsearch on K8s(Elastic 中文社区维护)
https://github.com/elasticsearch-cn/elastic-on-gke/
流式分析平台框架(Beam)
https://github.com/cloudymoma/raycom
极限网关(持续完善中)
http://gateway.infini.sh/
https://github.com/medcl/infini-gateway
5、Elasticsearch 基于 Pipeline 窗口函数实现实时聚合计算(李猛)
5.1 Pipeline 实时计算模型
pipeline 管道——输入、处理、输出。
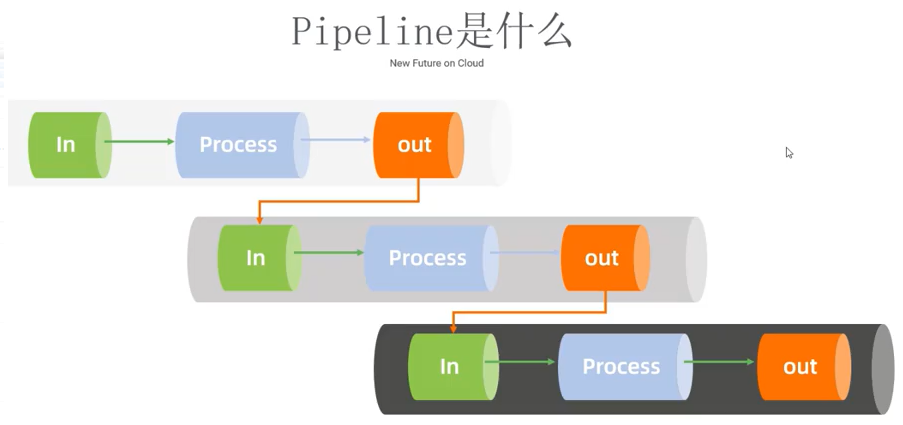
类似:logstash 中的三个核心:input、filter、output。
现有流计算的问题:
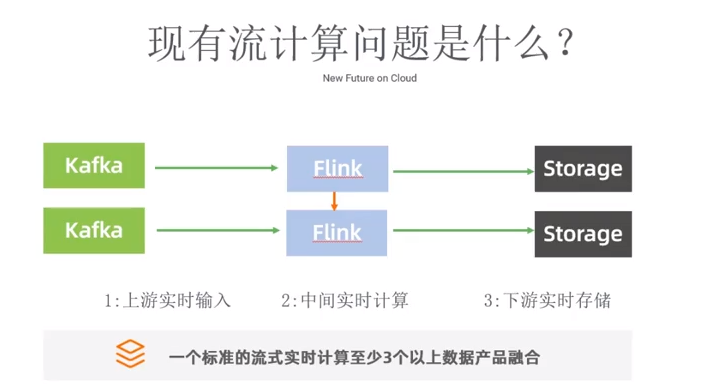
Kafka:上游。
Flink:中间实时计算。
Storage:下游实时存储。
现有流计算架构问题总结如下:
每增加一个环节(一个新架构选型),系统复杂性增加数倍。
架构可靠性降低。
会增加学习、运维成本高。
现有产品架构体系不够简化,能不能不是三件套,而是单件套?
5.2 ES - Pipeline 实时计算能力
ES Ingest pipeline
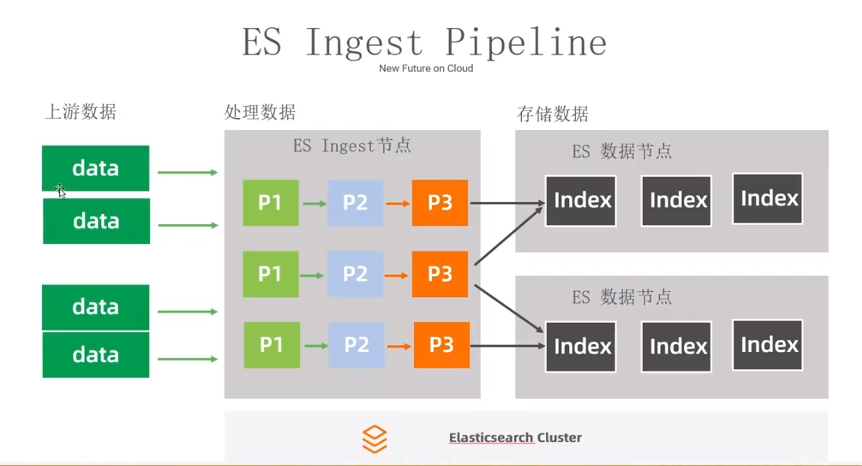
使用 Ingest pipeline 解决数据预处理问题。
前提:业务场景不复杂。
思考:Kafka、Flink 合并到用 Elasticsearch 实现。
ES Rollup pipeline
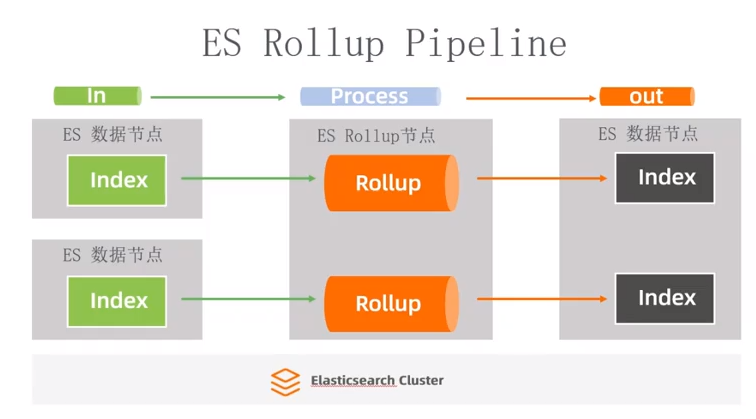
Rollup 核心:基于时间维度实现数据转换、压缩、折叠。
ES Transform pipeline
Transform:自己定义脚本或者函数实现数据转换。
ES Aggregations Pipeline
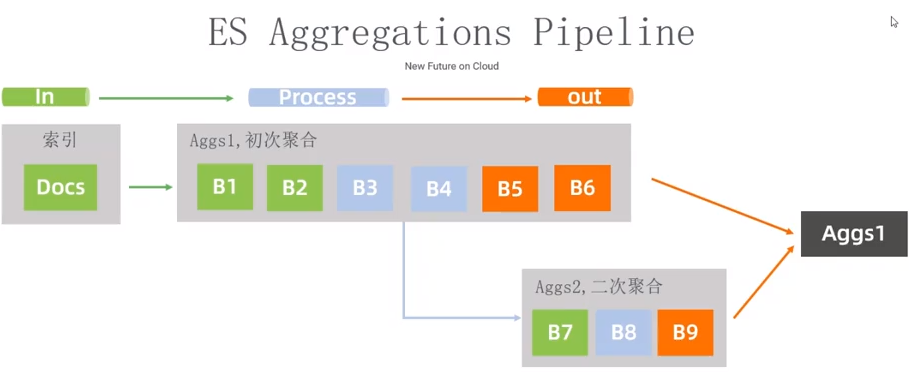
聚合 + pipeline 二次聚合,可以将结果写回到:索引。

Moving_avg: 移动平均值。
Moving_fn:自定义计算函数,自定义脚本。
Moving_percentles: 计算百分位占比。
5.3 ES + X实时计算畅想
认知前提:ES 具备一定的实时计算能力。

ALL in One(大白话意思:“Elasticsearch 一统江湖”)。
6、基于 Elasticsearch 的容器化编排实践(白凡)
6.1、为什么使用容器?
业务方使用 ES 需求不一样。
资源隔离。
较虚拟机相对轻量级。
敏感业务数据:物理机集群存储。
不敏感业务数据:容器集群存储。
6.2、容器化优点
容易构建、迁移、部署。
工具链的标准化和快速部署。
开发、测试、生产 ES 版本统一化。
底层参数以及 ES配置 标准化。
轻量 + 高效。
6.3、由代码到上线的可追溯流程
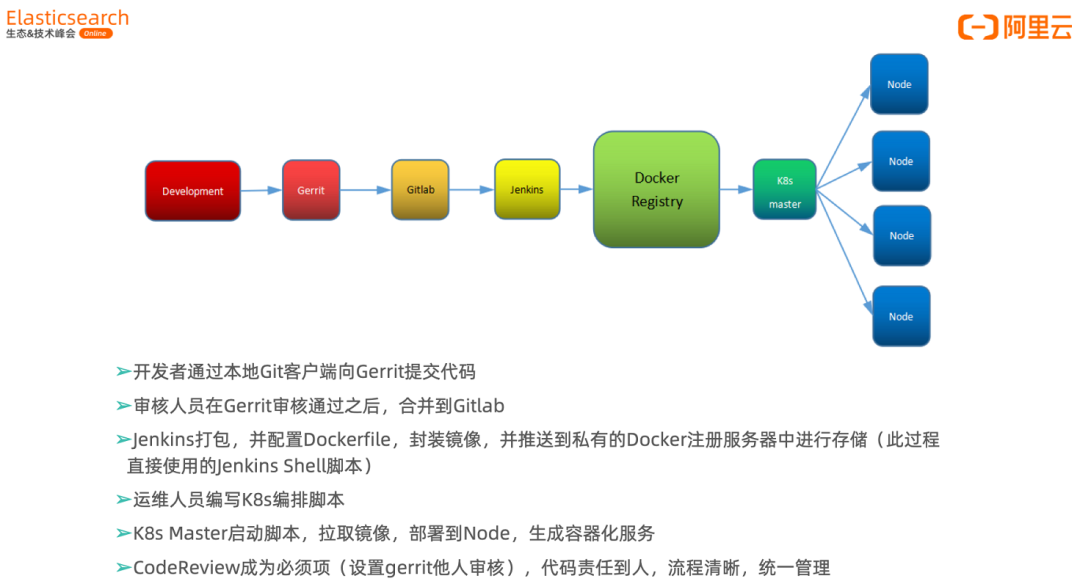
使用了:
Gerrit 代码审查工具。
Jenkins 自动化打包工具。
6.4、容器化中常见问题及解决方案

7、如何规划和执行威胁狩猎?(刘征)
威胁狩猎本质:安全分析中高阶、顶层威胁情报集成、管理工作。
7.1 安全问题无处不在
攻击充满了盲点
每个人都是目标
安全分析师不堪重负
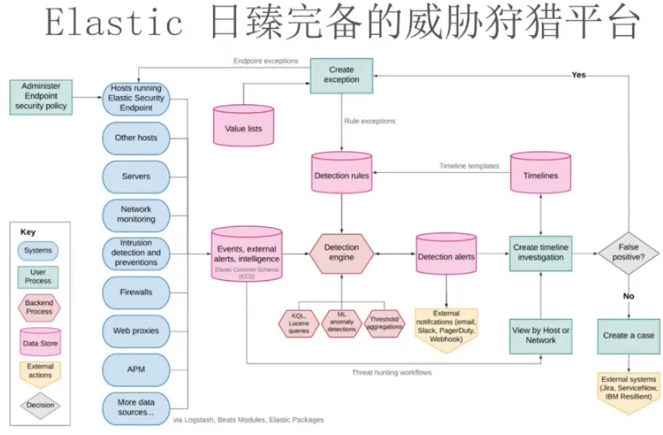
7.2 基于现有模块构建 Elastic 安全体系
Elastic 内置了监测规则、监测引擎、监测告警等。
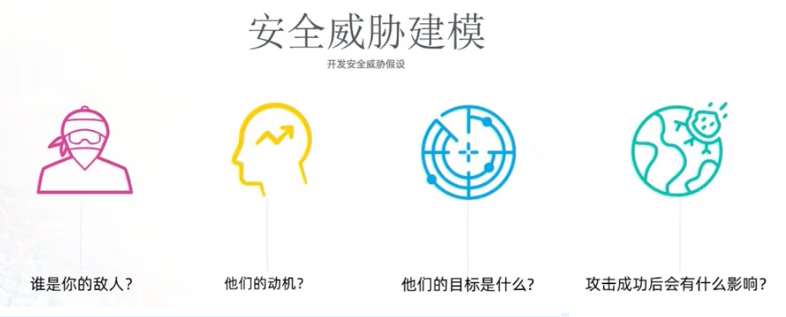
7.3 安全威胁建模四个步骤组成:
在 kibana SIEM 中创建监测规则,形成基于 KQL的威胁探测规则。
7.4 安全狩猎核心步骤
第一步:通过 beats 收集日志。
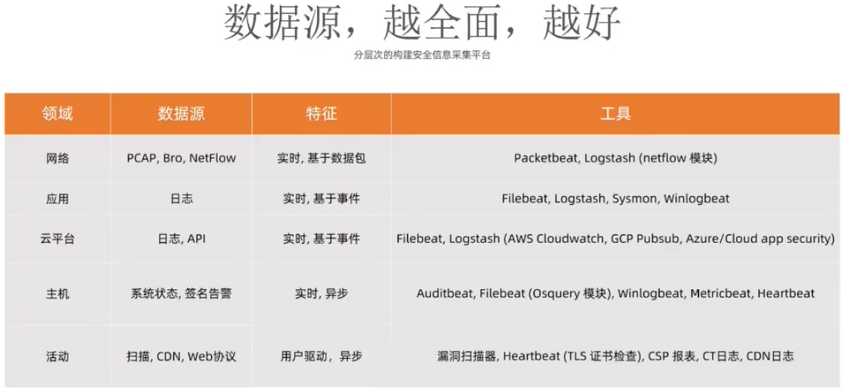
第二步:通过数据丰富提高威胁情报的质量。

第三步:通过 Elastic SIEM 工具实现安全狩猎。

以上,人为对已知攻击的分析、判断。
可不可以对未知隐患发现?可以的,人工 + 机器学习实现。

7.5 推荐使用:MITRE ATTCK (内置于:Elastic SIEM)的全方位防护。

上面一句话很简练,是为总结。
8、阿里云 Elasticsearch 云原生内核建设之路(魏子珺)
8.1 阿里云 Elasticsearch 内核概览
8.1.1 阿里云Elasticsearch内核优势
阿里云内核 VS 开源内核:
针对阿里云基础设施深度定制的内核,可最大发挥阿里云基础设施性能及成本优势。
做场景化优化和功能增强。
成本、性能、稳定性、功能较开源都有优势。

8.1.2 阿里云 Elasticsearch 内核需求
简单:支持动态扩容、弹性计算,用户不用担心资源问题。
好用:开箱即用,根据场景提供最优配置。
性价比:价格低、性能好、足够稳定。
8.1.3 阿里云 Elasticsearch 内核成果

成本节约:计算存储分离、冷热分离、Indexing service、索引数据压缩。
性能优化:ElasticBuild、物理复制、 bulk 聚合插件、时序查询剪枝。
稳定性提升:集群Qos限流、慢查询隔离池、协调节点流控、kmonitor全方位监控。
功能增强:向量检索插件、NLP分词插件(1GB 海量词库),OSS Snapshot 插件,场景化推荐模板。
8.2、云原生 Elasticsearch 如何定义?
Elasticsearch 云服务,开行即用,API 自动化部署和运维。
计算存储分离,弹性可伸缩。
充分利用云基础设施,网络、存储和算力。
8.3、云原生 Elasticsearch 内核如何设计?
8.3.1 热节点计算存储分离——分布式文件系统
8.3.2 冷热分离——冷节点对象存储
挑战1:冷节点使用对象存储,只有http接口,无 POSIX 接口,需要 Lucene 底层适配。
挑战2:单次IO的延时非常高。
挑战3:无法使用操作系统 pagecache 和预读能力。
8.3.3 Serverless:让用户关心从集群下沉到索引。
挑战1:如何解决多租户共享和平衡隔离问题。
挑战2:如何实现与原生ES一致的体验。
挑战3:如何评估索引的使用资源。
8.4 、阿里云云原生 Elasticsearch 实践
8.4.1 热节点计算存储分离
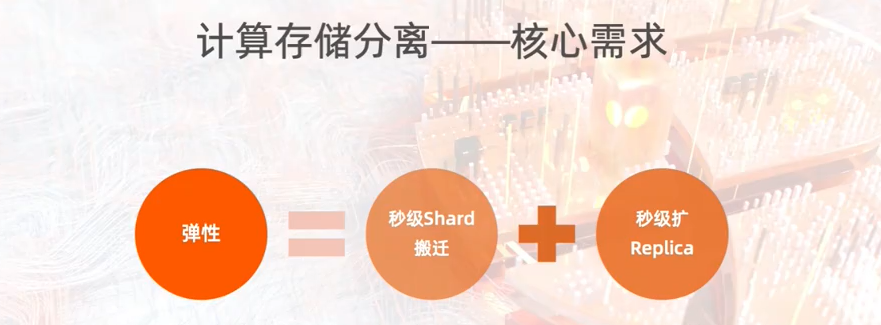
核心诉求:彻底弹性。不止是原生的动态添加节点、动态分片数据迁移。
核心需求:
分片秒级搬迁
秒级扩容副本
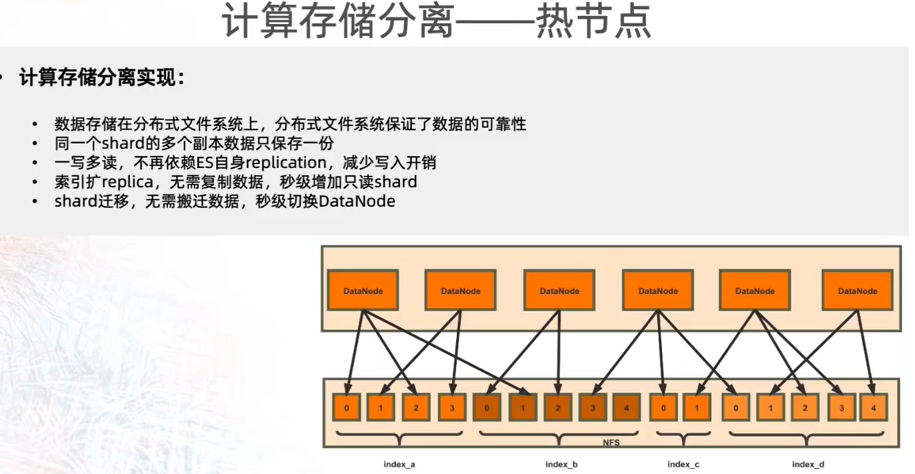
彻底弹性的本质:分片的搬迁、副本的扩充,底层数据都是不动的,只需要调整的是 DataNode 到分片的映射。
热节点计算存储分离的本质是:不再需要分片的副本保证数据的高可靠性(原生 ES 需要),而是借助:分布式文件系统保障数据的可靠性。
核心技术之一:内存物理复制,实现 replica 的近实时访问。
核心技术之二:两阶段 io fence,主备切换数据一致性保证以及防止网络异常时的数据多写。
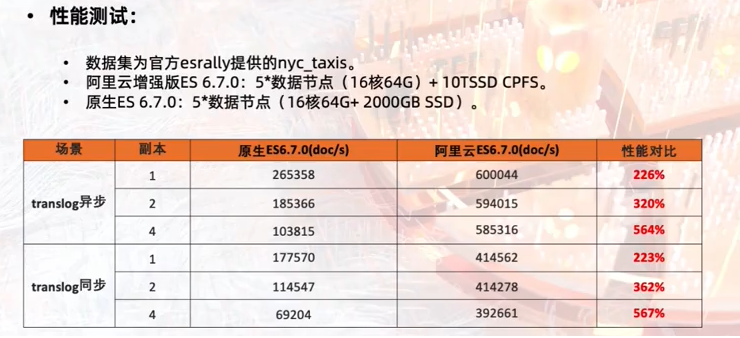
计算存储分离优势:
秒级弹性扩缩容。
写入性能提升 100%(免去了副本写入的CPU开销)。
存储成本倍数降低(数据在共享存储中存储一份,一写多读)
8.4.2 Serverless——Indexing service
2021 年 2 月上线。
功能:提供写入托管服务,满足高并发时序数据写入,降低业务集群 CPU 开销。
适用场景:日志、监控、APM 等时序场景。
解决痛点:
写多读少。
消耗大量计算资源 用于写入。
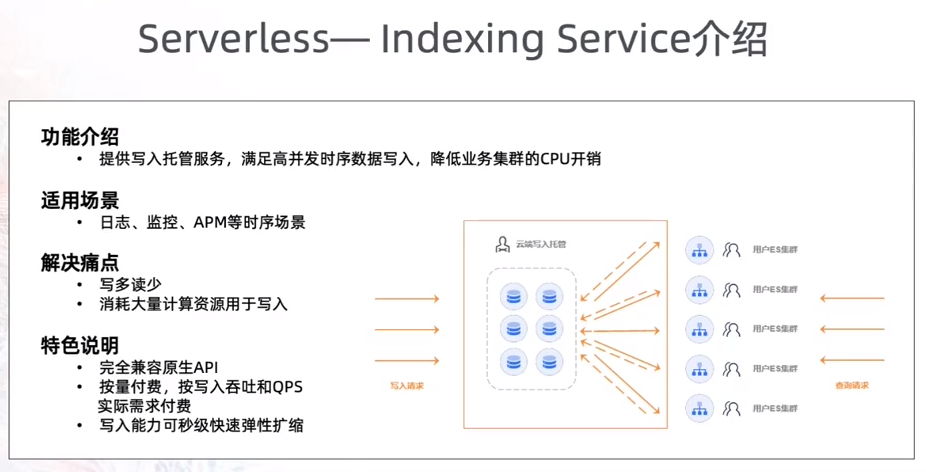
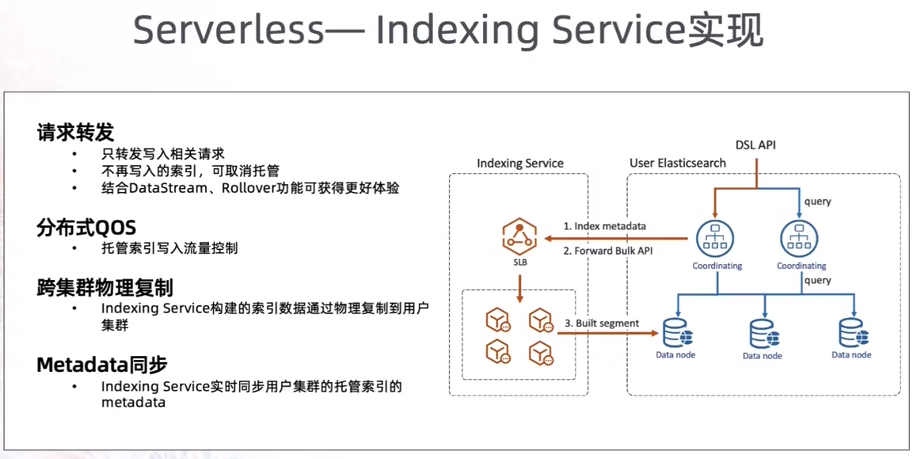

一句话概括Indexing Service 本质:写入托管服务,也就是说:针对时序、日志场景数据,用户无需再关系写入细节、写入优化、运维等操作,全权由阿里云托管搞定。
9、小结
各位分享大咖的视频都值得看,建议大家结合自己的业务场景去看。
更多细节内容,推荐大家看视频,视频地址:
https://developer.aliyun.com/topic/esanniv3rd?userCode=qzgc9fkf
推荐:
中国最大的 Elastic 非官方公众号
点击查看“阅读原文”,和全球近1000 位 Elastic 爱好者一起每日精进 ELK 技能!