
机器学习的 Learning theory 学习理论综述
Learning Theory and Advanced Machine Learning
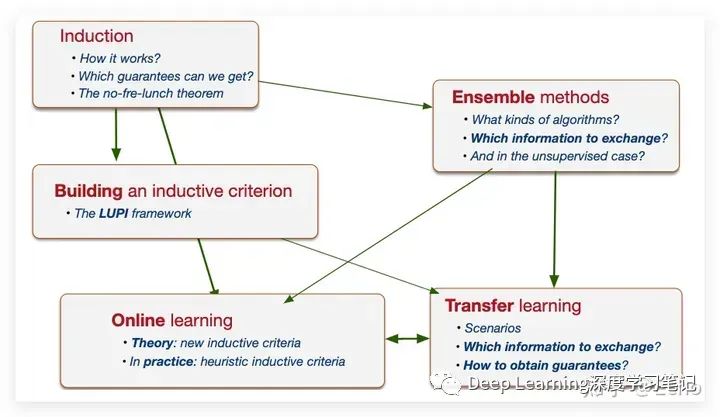
先放一张课程大纲的图,各种 learning 方法,大概纠葛缠绕成这个样子:
1.
Introduction
所谓的 learning,一句话说就是关于从有限的数据中推断预测和规律。那么,
- 我们希望得到什么样的保证?
- 我们如何获得它们?
另外,学习可能意味着多个学习 agents,如集成学习:
- 他们之间应该交流什么信息?
在 stationary 环境的情况下,有一个完善的理论称为“ learning 的统计理论”。
但 learning 也可能意味着几个连续的学习任务,如:
- domain adaptation (领域适应)
- transfer learning (迁移学习)
- online learning (在线学习)。
也叫做 Out-Of-Distribution learning。而这也就引申出了一些问题,比如:
- 当训练数据和测试数据之间的环境发生变化时,可以做什么?
- 同样,上下文之间应该传达什么?
The statistical theory of learning(学习的统计理论)
介绍一下机器学习里最基本的概念。
- 预测错误的 cost。
- 也就是 loss function(损失函数)。
- 如果我选择 h,expected cost (期望风险)是多少?
- real risk (或者叫作 true risk)
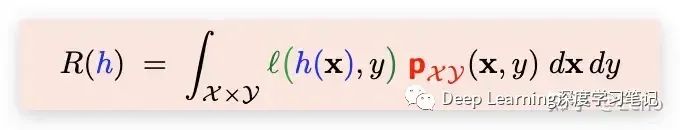
- 另外还有一个概念是:empirical risk(经验风险)
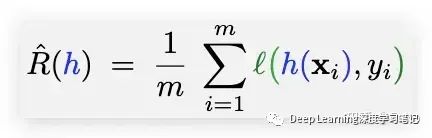
ERM (Empirical risk minimization)经验风险最小化
学习策略:
– 选择具有零经验风险的假设(无训练误差)
– 期望 h 的泛化性能如何?
– 出现错误 R(h) > ε 的风险是什么?
PAC learning(Probably Approximatively Correct)概率近似正确学习
概念
PAC 学习是机器学习的理论框架,它为学习算法的准确性和置信度提供数学保证。
它的目标是找到一个具有高概率“可能近似正确”的假设(模型或预测规则),这意味着该假设将以高置信度接近真实函数。该理论提供了一种评估学习算法的样本复杂度和计算复杂度的方法,使其成为设计和分析机器学习算法的有用工具。
Learning 最后就变成了:
- 假设空间(hypothesis space) H 的选择
– 受必要性的限制
- 归纳准则 (inductive criterion) 的选择
– 经验风险必须被 regularized
- 为了最小化正则化经验风险的 H 探索策略 (exploration strategy)
– 必须高效:
• 快速地
• 如果可能,只有一个最优解(例如凸问题)
2.
Semi-supervised learning (半监督学习)
半监督学习其实是有监督学习和无监督学习的结合。它利用一小部分标记数据和大量未标记数据训练,模型必须从这些数据中学习并对新数据进行预测。
General principle
– 决策函数不穿过 X 的高密度区域
– 例如 SVM 算法
给个图比较好理解:
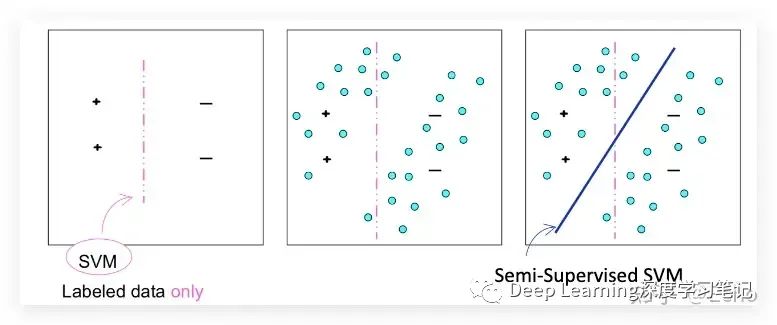
半监督学习:如何在理论上接近它?
unlabeled 数据提供帮助的能力取决于两个量:
- 目标函数确实满足给定假设的程度:即决策函数不切割高密度区域。
- 该分布允许这个假设排除替代假设的程度:即无监督训练样本有助于限制可能的决策函数。
(The extent to which the distribution allows this assumption to rule out alternative hypotheses)
其它 learning scenarios
- Transductive learning (转导式学习)
- Weakly supervised learning (弱监督学习)
- The Multi-Instance problem (多实例问题)
- Analogical induction (类比归纳法)
Transductive learning (转导式学习)
它和半监督学习的区别在于:
– 半监督学习在输入空间 X 上寻求一般假设(decision rule)
– Transductive learning 试图仅对测试点(问题)进行预测。
所以,我提前知道我会在哪里被 queried:
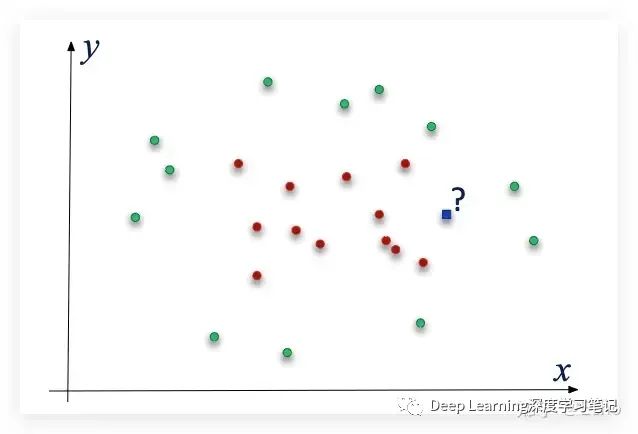
放一点人生哲学:
“在解决感兴趣的问题时,不要将解决更一般的问题作为中间步骤。
尝试获得你真正需要的答案,而不是更笼统的答案。”
——(Vapnik, 1995)
3.
LUPI Framework(Learning Using Privileged Information 基于特权信息的学习方法)
这个方法是受 learning at school 的启发
- 目标是学习一个函数
- 假设学习时比测试时有更多的可用信息
- 那么我们能否提高泛化性能
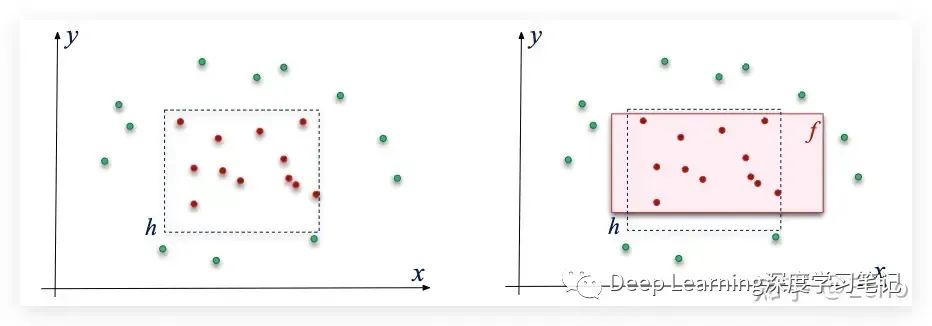
在计算机视觉中,我们用下面这个图来解释:

- 核心在于特权信息允许我们区分简单和困难的例子训练集。
- 假设相对于特权信息容易/困难的 example 对于原始数据也将是容易/困难的,我们使信息从特权信息传输到原始数据模态。
- 更具体地说,我们首先定义并确定哪些样本很容易并且对于分类任务来说很难,并结合将特权信息放入编码容易/困难的样本权重中。”(更重视简单的例子)
real risk 和 empirical risk 的界限

一个解决方法是 SVM+
经典的优化问题是这样的:
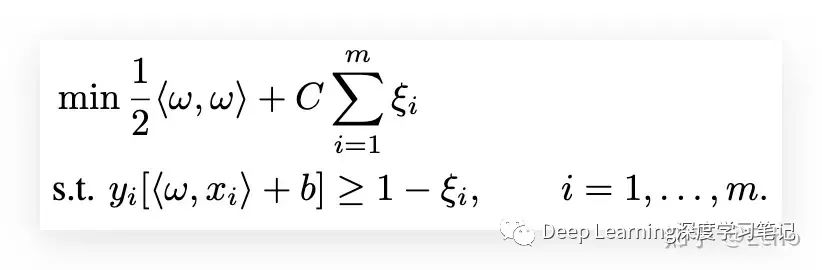
然后我们可以变成:
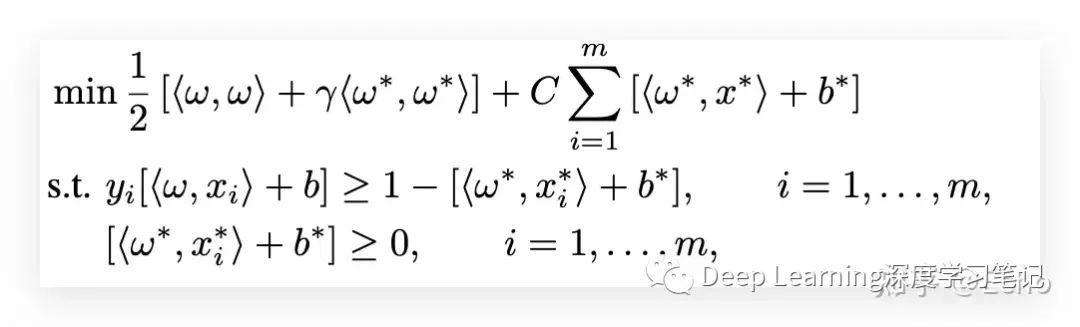
Intuition:
- 找出比较难分类的数据点(outliers)
- 因此回到 realizable case 并获得 而不是 的收敛率
Early Classification of Time Series(早期时间序列分类)
标准的时间序列分类:
下图中新时间序列 的类别是什么?
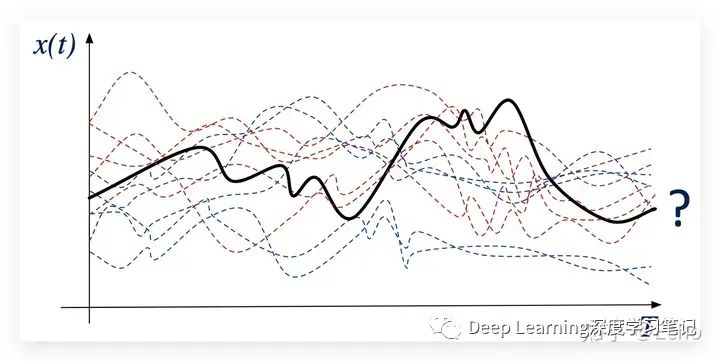
早期时间序列分类
下图中新的不完整时间序列 的类别是什么?
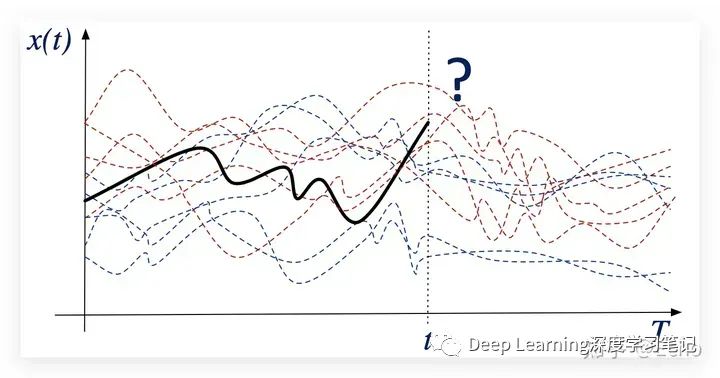
这里,我们就可以用 LUPI framework 了,但是不完全一样,因为我们不需要检查数据点是简单还是困难。
新决策问题:Early Classification
-
数据流
-
分类任务
-
越早越好
-
trade-off
-
- 分类效果
- 延迟预测的 cost
在线决策问题
• 可以选择在每个时间点推迟
– 如果预期的未来表现能够克服延迟决策的成本。
比如说,我们有一个输入序列:
然后,我们有:
-
错误分类的 cost 函数:
-
delaying decision 的 cost 函数:
那么,做出决定的最佳时间是什么呢?

Optimal time 就是:
Early classification 和 LUPI
那么要怎么 take advantage of 这两个东西呢呢?
- 未来可能序列的信息
- 学习所有时间步长的分类器的可能性
原理
-
Training:
识别训练集中有意义的时间序列子集:
对于这些子集 中的每一个,以及对于每个时间步长 ,估计混淆矩阵:
-
Testing: 对于任何新的不完整输入序列
确定最可能的子集:更接近 的形状
计算所有未来时间步的预期决策成本

Out Of Distribution (OOD) learning (分布外学习)
先说一点背景:
- 世界为大脑提供了时间结构化的输入流,这些输入流不是独立的,也不是同分布的
- 生物体面对连续的任务并且它们能够完成持续学习
- 在学习任务 A 之后学习任务 B 可能会产生积极或消极的干扰:迁移学习
OOD learning 就是使用来自源域 (source domain) 的知识改进目标域 (target domain) 中的目标预测函数。
解释一些概念:
-
源域和目标域可以相同,但具有不同的概率分布:“Domain Adaptation”
Covariate shift:表示的就是同样的决策函数 , 但是不同的分布 .
-
Concept Drift (概念漂移):决策函数 不同
-
或者它们可以来自不同的域,也就是 Transfer Learning (迁移学习) 了。
-
Non-stationary 环境:
-
Co-variate shift(协变量偏移):
– Virtual drift (虚拟漂移)
– Non i.i.d.
比如说, moving robot
-
Change of concept(概念改变):
– Concept drift(概念漂移)
– Non i.i.d. + non stationary
比如说,消费者的 expectations,
介绍几种不同的 transfer(迁移):
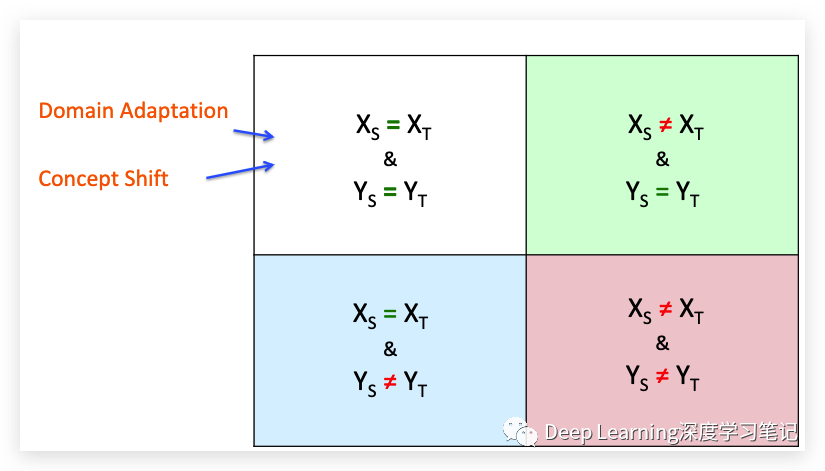
• 领域适应
和
– 但不同的分布
• 概念转变
和
– 但不同的分布
• 迁移学习
和/或
Hypothesis Transfer Learning
-
Target domain:
- 训练集:
- Distribution:
-
Source domain:
– Source hypothesis
我们想找的是:
Hypothesis Transfer Learning Algorithm:

Covariate shift
先举几个例子:
-
垃圾邮件过滤
– 不是同一个用户: 可能不同
- 例如,对我来说,conference 公告很重要,但可能会打扰到其他人。
-
消费者口味或期望的变化
-
药物的变化
– 例如 COVID 变体的严重程度不同
所以,对于 Covariate shift,不再是经验风险和实际风险之间的“直接”联系。
输入分布会发生改变:
funtional relation 不发生改变:
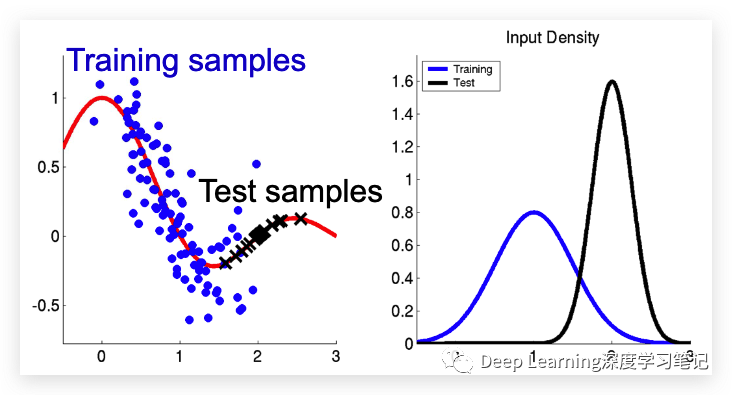
Distillation(蒸馏)
Motivation(动机):
-
我们想在计算受限的设备(例如智能手机)上部署分类器 (NN)
– 不能使用深度神经网络
-
学习任务困难,需要大数据集和复杂的学习方法(例如深度神经网络)
那么问题来了:
我们可以使用学习到的深度神经网络作为老师来帮助学生(即受限设备)学习更简单的分类器吗?
一种很复杂的 learning 技术——GoogLeNet:
Catastrophic forgetting
Pivot feature
Structural Correspondence Learning
4.
Transfer learning (迁移学习)
-
domain 变更
– 例如:在不同的环境中识别相同的对象
-
task 变更
– 例如:学会下国际象棋后又学下象棋
下面是 domain adaptation(领域适应) 的例子

其实上面说的 OOD Leaning 和 Curriculum Learning 都算是迁移学习的一种。
Reference
知乎链接: https://zhuanlan.zhihu.com/p/604599762
https://machinelearningmastery.com/what-is-semi-supervised-learning