
CPU处理器主要技术指标


CPU 作为计算机的核心,负责整个计算机系统的协调、控制以及程序运行。伴随着大规模集成电路的技术革命以及微电子技术的发展,CPU 发展日新月异、种类繁多,其中集成的电子元件也越来越多,速度越来越快,功能越来越强。
本文来自“精华:CPU中央处理器技术”,更多CPU知识请参考“2023年CPU&GPU天梯图(最新版)”“服务器基础知识全解(终极版)”。
1.主频
主频,即 CPU 内核工作的时钟频率(CPU Clock Speed),单位是 MHz 或 GHz。通常所说的某某 CPU 是多少兆赫指的就是 CPU 的主频。
注意:很多人认为 CPU 的主频就是其运行速度,其实不然。
CPU 的主频表示在 CPU 内数字脉冲信号震荡的速度,主频和实际的运算速度存在一定的关系,但目前还没有一个确定的公式能够定量两者的数值关系,因为 CPU 的运算速度还与 CPU 的流水线数目、缓存大小、指令集、CPU 的位数等指标有关。
2.外频
外频是 CPU 的基准频率,单位是 MHz,是 CPU 与主板之间同步运行的工作频率(系统时钟频率)。绝大部分计算机系统外频也是内存与主板之间同步运行的频率。
3.前端总线
前端总线(Front Side Bus,FSB)是 AMD 公司推出 K7 CPU 时提出的概念,是将 CPU连接到北桥芯片的总线,决定 CPU 与内存数据交换的速度。
数据传输最大带宽取决于所有同时传输数据的宽度和传输频率,即数据带宽=(FSB×数据位宽)/8。例如 64 位的 CPU,前端总线是 800MHz,则它的数据传输最大带宽是6.4GB/s。常见的前端总线频率有 266MHz、333MHz、400MHz、533MHz、800MHz、1066MHz、1333MHz 等,前端总线频率越大,表示 CPU 与内存之间的数据传输速率越高,更能充分发挥出 CPU 的性能。足够大的前端总线可以保障有足够的数据供给 CPU。较低的前端总线无法供给足够的数据给 CPU,限制了 CPU 性能的发挥,成为系统瓶颈。
外频与前端总线的区别:前端总线的速度是 CPU 与内存之间数据传输的速度,外频是CPU 与主板之间同步运行的频率。也就是说,100MHz 外频特指数字脉冲信号在每秒钟震荡一千万次;而 64 位处理器 100MHz 前端总线指的是每秒钟 CPU 可接受的数据传输量是100MHz×64b/8 = 800MB/s。
4.倍频
倍频,全称是倍频系数,是 CPU 主频与外频的比值。原先并没有倍频概念,CPU 主频和系统总线的速度是一样的,但 CPU 的速度越来越快,倍频技术也就应运而生。
CPU 主频的计算方式为:主频 = 外频 × 倍频。显然,当外频不变时,提高倍频,CPU 主频也就提高了。每一款 CPU 默认的倍频只有一个,主板必须能支持这个倍频。因此在选购主板和 CPU 时必须注意这点,如果两者不匹配,系统就无法工作。俗称的超频就是通过设置倍频系数,CPU 工作频率超过 CPU 主频。
5.CPU 的位和字长
在数字电路和计算机技术中采用二进制,只有 0 和 1,无论是 0 还是 1 在 CPU 中都是
一“位”。
CPU 在单位时间内(同一时间)能一次处理的二进制数的位数叫字长。能处理字长为8 位数据的 CPU 通常叫 8 位 CPU。同理,32 位 CPU 就能在单位时间内处理 32 位二进制数据。
字节和字长的区别:英文字符用 8 位二进制可以表示,所以将 8b 称为一个字节。CPU字长是不固定的,8 位 CPU 一次只能处理 1B,而 32 位 CPU 一次就能处理 4B,64 位 CPU一次可以处理 8B。
6.缓存
缓存(Cache)是位于 CPU 与内存之间的临时存储器,容量比内存小,存取速度比内存快。Cache 中的数据实际上是内存中的一小部分,计算机工作时,CPU 需要重复读取同样的数据块,如果每次都从内存中读取,由于 CPU 速度远高于内存速度,则内存成为计算机工作的瓶颈,Cache 正是在这种情况下出现的。
Cache 工作原理:当 CPU 要读取一个数据时,首先从 Cache 中查找,如果找到,就立即读取并送给 CPU 处理;如果没有找到,就从速度相对慢的内存中读取,同时把这个数据所在的数据块调入 Cache 中,以便以后能够快速地从 Cache 中读取该数据,而不必再去读内存。
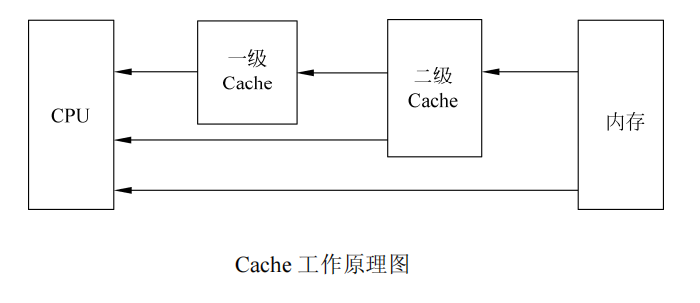
这样的读取机制使 CPU 读取 Cache 的命中率非常高(多数 CPU 可达 90%左右),也就是说 CPU 下一次要读取的数据 90%都在 Cache 中,只有大约 10%需要从内存读取,这样可以大大节省 CPU 读取数据的时间。
CPU 内核集成的缓存称为一级缓存(L1 Cache),主板上集成的缓存称为二级缓存(L2 Cache)。一级缓存可以进一步分为数据缓存(D-Cache)和指令缓存(I-Cache),分别用来存放数据和执行这些数据的指令,可以同时被 CPU 访问,能够减少争用 Cache 造成的冲突,提高处理器效能。
7.指令集
CPU 依靠指令完成计算和控制各部件的工作,每款 CPU 在设计时就规定了一系列与其硬件电路相配合的指令系统。指令集的强弱也是 CPU 的重要指标,指令集是提高 CPU效率的有效工具之一。
从计算机体系结构讲,指令集可分为复杂指令集和精简指令集两部分。目前常见的Intel CPU 以及 AMD CPU 均为采用 X86 架构的复杂指令集。
而从具体运用看,Intel 公司的 MMX(Multi Media Extended)、SSE、SSE2(Streaming-Single instruction multiple data-Extensions 2)和 AMD 公司的 3DNow!等都是 x86 架构 CPU的扩展指令集,分别增强了 CPU 的多媒体、图形、图像和 Internet 等的处理能力。
8.CPU 内核和 I/O 工作电压
从 Pentium 开始,CPU 的工作电压分为核心电压和 I/O 电压两种,核心电压即驱动CPU 核心芯片的电压,I/O 电压指驱动 I/O 电路的电压。CPU 的核心电压小于等于 I/O 电压。核心电压根据 CPU 的生产工艺而定,一般制作工艺越先进,电压越低;I/O 电压一般在 1.6~5V 之间。CPU 的工作电压有明显的下降趋势,低工作电压有三个优点:
(1)使 CPU 的总功耗降低,系统的运行成本相应降低,电池可以工作更长时间,对于便携式和移动系统来说非常重要。
(2)功耗降低,发热量减少,运行温度不高的 CPU 可以与系统更好的配合。
(3)是提高 CPU 主频的重要因素之一。
9.制造工艺
制造工艺是指集成电路内电路与电路之间的距离。1995 年以后,芯片制造工艺从 0.5μm、0.35 μm、0.25μm、0.18μm、0.15μm、0.13μm、90nm、65nm、45nm,发展到目前的28nm、15nm、7nm、5nm。
先进的制造工艺可以在同样的面积上集成更多的晶体管,并降低功耗,从而减少发热量,使 CPU 实现更多的功能和更高的性能;使 CPU 核心面积不断减小,在相同面积的晶圆上可以制造出更多的 CPU 产品,从而降低 CPU 的售价。
10.超流水线与超标量
在解释超流水线与超标量前,先了解流水线(Pipeline)。
流水线是 Intel 公司在 80486 CPU 中开始使用的。流水线工作方式就像工业生产上的装配流水线,通过增加硬件实现。例如要预取指令,就增加取指令的硬件电路,在 CPU 中由 5、6 个不同功能的电路单元组成一条指令处理流水线,并将一条指令分成 5、6 步,再由这些电路单元分别执行,各步的工作在时间上重叠,从而提高 CPU 的运算速度。
超级流水线通过细化流水、提高主频,使得在一个机器周期内完成一个甚至多个操作,其实质是以时间换空间。例如 Intel Pentium 4 的流水线长 20 级。流水线的步(级)越长,完成一条指令的速度越快,能适应主频更高的 CPU。但是流水线过长也带来一定的副作用,很可能会出现主频较高的 CPU 实际运算速度较低的现象。
CPU 中内置多条流水线来同时执行多条指令,每时钟周期内可以完成一条以上的指令,这种设计叫超标量(Superscalar)技术。
11.SMP
SMP(Symmetric Multi-Processing,对称多处理结构)是指在一个计算机上汇集了一组结构相同的处理器(多 CPU),各 CPU 共享内存以及总线。在高性能主板和服务器中常见,例如运行 UNIX 操作系统的服务器可支持最多 256 个 CPU。
12.多核心
多核心是指单芯片多处理器(Chip Multiprocessors,CMP)。CMP 由美国斯坦福大学提出,其思想是将大规模并行处理器中的 SMP 集成到同一芯片内,各个处理器并行执行不同的进程。从体系结构角度看,SMP 比 CMP 对处理器资源利用率要高,在克服延迟影响方面更具优势。
而 CMP 相对 SMP 的最大优势在于其模块化设计的简洁性。复制简单、设计容易,指令调度也更加简单。同时,SMP 中多个线程对共享资源的争用也会影响其性能,而 CMP 对共享资源的争用要少得多,因此当应用的线程级并行性较高时,CMP 性能一般优于 SMP。此外,在设计上,更短的芯片连线使 CMP 比长导线集中式设计的 SMP 更容易提高芯片的运行频率,从而在一定程度上起到性能优化的效果。
13.多(超)线程技术
每个正在运行的程序都是一个进程。每个进程包含一到多个线程。线程是进程中可以独立完成一定功能的指令段。
多线程技术是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,进而提升整体性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-Level Multithreading)或同时多线程(Simultaneous Multithreading,SMT)处理器。
超线程(Hyper-Threading,HT)技术是 Intel P4 CPU 开始出现的一种技术,利用特殊的硬件指令把两个逻辑内核模拟成两个物理芯片,让单个处理器能进行线程级并行计算,进而兼容多线程操作系统和软件,减少 CPU 的闲置时间,提高 CPU 的运行效率。虽然采用超线程技术能同时执行两个线程,但它并不像两个真正的 CPU 那样,每个 CPU 都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两个 CPU 的性能。另外,含有超线程技术的 CPU 需要芯片组、软件支持才能发挥该技术的优势。
14.NUMA 技术
NUMA 即非一致访问分布共享存储技术,是由若干通过高速专用网络连接起来的独立节点构成的系统,各个节点可以是单个的 CPU 或是 SMP 系统。在 NUMA 中,Cache 的一致性有多种解决方案,需要操作系统和特殊软件的支持。
1、ODCC-2023数据中心自适应AI节能白皮书
2、ODCC-2023数据中心高性能网络拥塞检测技术白皮书
3、ODCC-2023数据中心氢能应用白皮书
4、ODCC-2023数据中心制冷系统AI节能技术及其应用白皮书
5、ODCC-2023数据中心低压开关技术白皮书

