
做时间序列预测没必要深度学习!GBDT性能超DNN
在深度学习方法应用广泛的今天,所有领域是不是非它不可呢?其实未必,在时间序列预测任务上,简单的机器学习方法能够媲美甚至超越很多 DNN 模型。

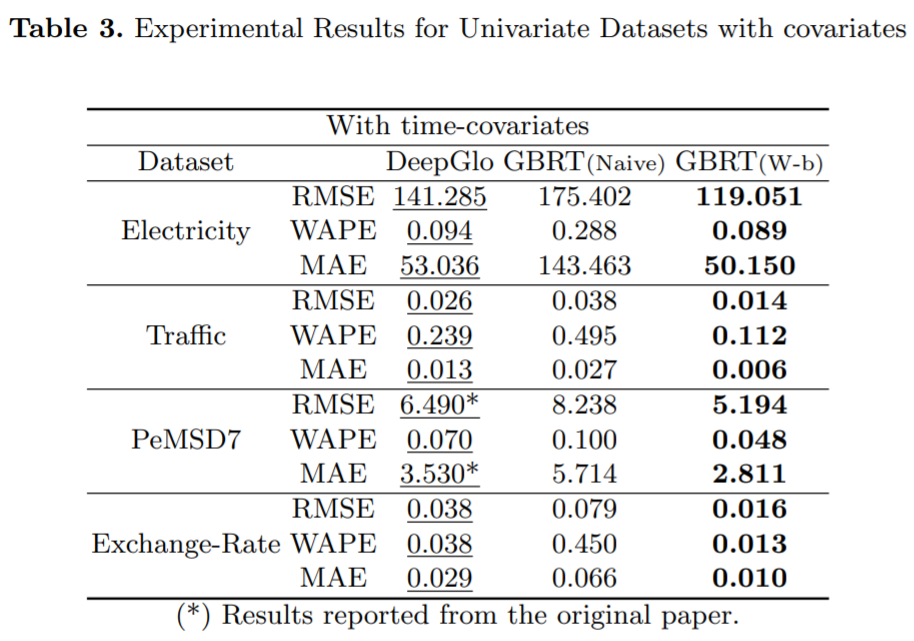
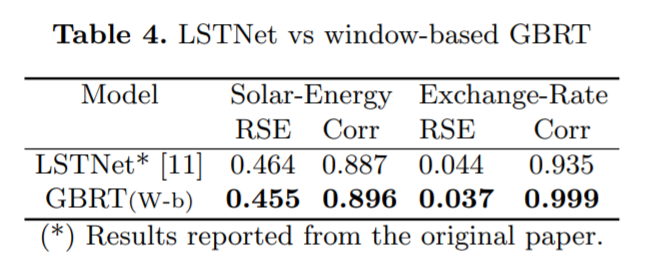
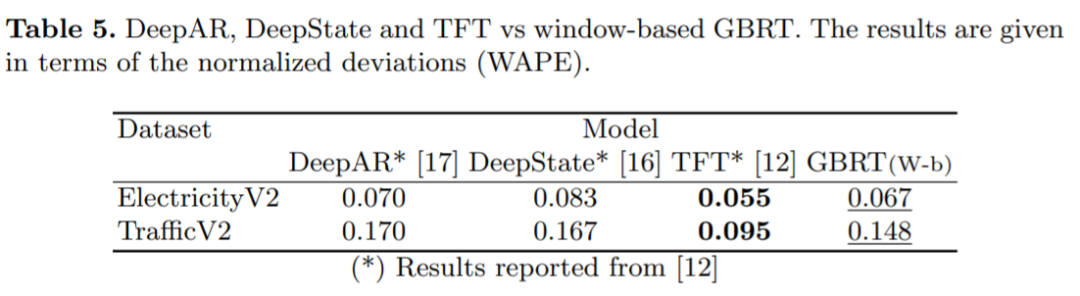
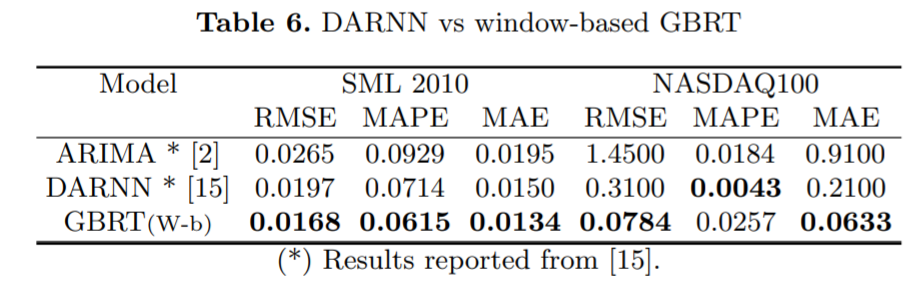
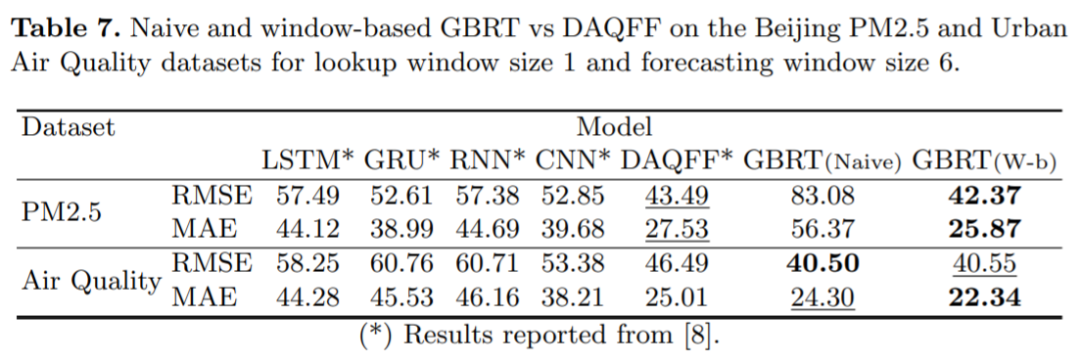
对于用于时间序列预测的基于窗口的学习框架来说,精心配置 GBRT 模型的输入和输出结构有什么效果?
一个虽简单但配置良好的 GBRT 模型与 SOTA 深度学习时间序列预测框架相比如何?
主题:只考虑时间序列预测领域的研究;
数据结构:专用数据类型,但如异步时间序列和概念化为图形的数据被排除在外;
可复现:数据、源代码应公开。如果源代码不可用,但实验设置有清晰的文档,研究也可以从实验中复制结果;
计算的可行性:研究中得出的结果能够以易于处理的方式复现,并在合理的时间内可计算。
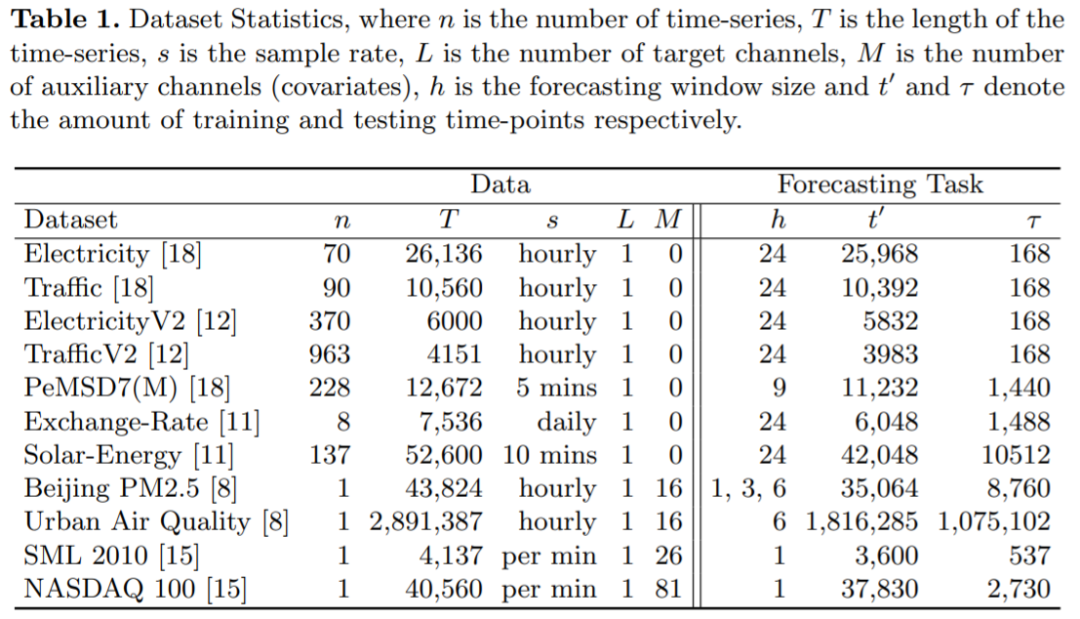
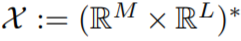 和一个集合
和一个集合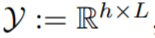 ,经过一系列假设后,得到如下期望损失最小化模型:
,经过一系列假设后,得到如下期望损失最小化模型: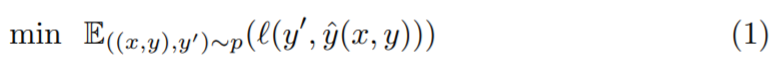
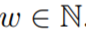 。这种基于窗口的 GBRT 模型输入设置如图 1 所示:
。这种基于窗口的 GBRT 模型输入设置如图 1 所示: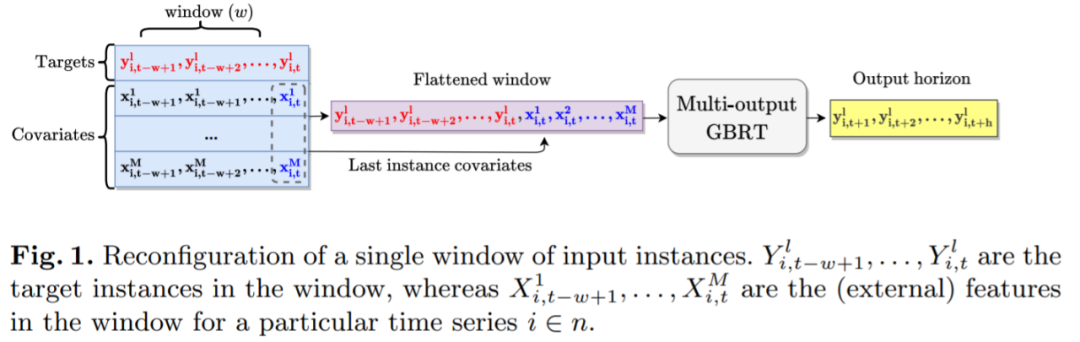
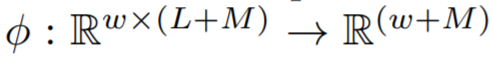 将典型的 2D 训练实例(时间序列输入窗口)变换为适合 GBRT 的 1D 形状向量(扁平窗口)。该函数将所有 w 实例的目标值 y_i 连接起来,然后将最后一个时间点实例 t 的协变量向量附加到输入窗口 w 中,表示为
将典型的 2D 训练实例(时间序列输入窗口)变换为适合 GBRT 的 1D 形状向量(扁平窗口)。该函数将所有 w 实例的目标值 y_i 连接起来,然后将最后一个时间点实例 t 的协变量向量附加到输入窗口 w 中,表示为 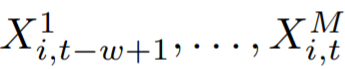 。
。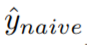 是一个简单的逐点回归模型,将时间点
是一个简单的逐点回归模型,将时间点  的协变量作为输入,预测单一目标值 Y_i、j 为同一时间点训练损失如下:
的协变量作为输入,预测单一目标值 Y_i、j 为同一时间点训练损失如下: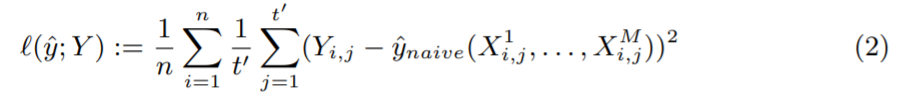
往期精彩:
评论