
Promtail Pipeline 日志处理配置
共 38490字,需浏览 77分钟
·
2021-05-07 01:57

Promtail 是 Loki 官方支持的日志采集端,在需要采集日志的节点上运行采集代理,再统一发送到 Loki 进行处理。除了使用 Promtail,社区还有很多采集日志的组件,比如 fluentd、fluent bit 等,都是比较优秀的。
但是 Promtail 是运行 Kubernetes 时的首选客户端,因为你可以将其配置为自动从 Promtail 运行的同一节点上运行的 Pod 中抓取日志。Promtail 和 Prometheus 在 Kubernetes 中一起运行,还可以实现非常强大的调试功能,如果 Prometheus 和 Promtail 使用相同的标签,用户还可以使用 Grafana 根据标签集在指标和日志之间切换。
此外如果你想从日志中提取指标,比如计算某个特定信息的出现次数,Promtail 效果也是非常友好的。
在 Promtail 中一个 pipeline 管道被用来转换一个单一的日志行、标签和它的时间戳。本文将介绍 Promtail 中的核心概念 pipeline 以及了解下如何设置 Promtail 来处理你的日志行数据,包括提取指标与标签等。
1基础
一个 pipeline 管道是由一组 stages 阶段组成的,在 Promtail 配置中一共有 4 种类型的 stages。
Parsing stages(解析阶段) 用于解析当前的日志行并从中提取数据,提取的数据可供其他阶段使用。Transform stages(转换阶段) 用于对之前阶段提取的数据进行转换。Action stages(处理阶段) 用于从以前阶段中提取数据并对其进行处理,包括:添加或修改现有日志行标签 更改日志行的时间戳 修改日志行内容 在提取的数据基础上创建一个 metrics 指标 Filtering stages(过滤阶段) 可选择应用一个阶段的子集,或根据一些条件删除日志数据。
一个典型的 pipeline 将从解析阶段开始(如 regex 或 json 阶段)从日志行中提取数据。然后有一系列的处理阶段配置,对提取的数据进行处理。最常见的处理阶段是一个 labels stage 标签阶段,将提取的数据转化为标签。
需要注意的是现在 pipeline 不能用于重复的日志,例如,Loki 将多次收到同一条日志行:
从同一文件中读取的两个抓取配置 文件中重复的日志行被发送到一个 pipeline,不会做重复数据删除
然后,Loki 会在查询时对那些具有完全相同的纳秒时间戳、标签与日志内容的日志进行一些重复数据删除。
下面的配置示例可以很好地说明我们可以通过 pipeline 来对日志行数据实现什么功能:
scrape_configs:
- job_name: kubernetes-pods-name
kubernetes_sd_configs: ....
pipeline_stages:
# 这个阶段只有在被抓取地目标有一个标签名为 name 且值为 promtail 地时候才会执行
- match:
selector: '{name="promtail"}'
stages:
# regex 阶段解析出一个 level、timestamp 与 component,在该阶段结束时,这几个值只为 pipeline 内部设置,在以后地阶段可以使用这些值并决定如何处理他们。
- regex:
expression: '.*level=(?P<level>[a-zA-Z]+).*ts=(?P<timestamp>[T\d-:.Z]*).*component=(?P<component>[a-zA-Z]+)'
# labels 阶段从前面地 regex 阶段获取 level、component 值,并将他们变成一个标签,比如 level=error 可能就是这个阶段添加地一个标签。
- labels:
level:
component:
# 最后,时间戳阶段采用从 regex 提取地 timestamp,并将其变成日志的新时间戳,并解析为 RFC3339Nano 格式。
- timestamp:
format: RFC3339Nano
source: timestamp
# 这个阶段只有在抓取的目标标签为 name,值为 nginx,并且日志行中包含 GET 字样的时候才会执行
- match:
selector: '{name="nginx"} |= "GET"'
stages:
# regex 阶段通过匹配一些值来提取一个新的 output 值。
- regex:
expression: \w{1,3}.\w{1,3}.\w{1,3}.\w{1,3}(?P<output>.*)
# output 输出阶段通过将捕获的日志行设置为来自上面 regex 阶段的输出值来更改其内容。
- output:
source: output
# 这个阶段只有在抓取到目标中有标签 name,值为 jaeger-agent 时才会执行。
- match:
selector: '{name="jaeger-agent"}'
stages:
# JSON 阶段将日志行作为 JSON 字符串读取,并从对象中提取 level 字段,以便在后续的阶段中使用。
- json:
expressions:
level: level
# 将上一个阶段中的 level 值变成一个标签。
- labels:
level:
- job_name: kubernetes-pods-app
kubernetes_sd_configs: ....
pipeline_stages:
# 这个阶段只有在被抓取的目标的标签为 "app",名称为grafana 或 prometheus 时才会执行。
- match:
selector: '{app=~"grafana|prometheus"}'
stages:
# regex 阶段将提取一个 level 合 componet 值,供后面的阶段使用,允许 level 被定义为 lvl=<level> 或 level=<level>,组件被定义为 logger=<component> 或 component=<component>
- regex:
expression: ".*(lvl|level)=(?P<level>[a-zA-Z]+).*(logger|component)=(?P<component>[a-zA-Z]+)"
# 然后标签阶段将从上面 regex 阶段提取的 level 和 component 变为标签。
- labels:
level:
component:
# 只有当被抓取的目标有一个标签 "app",其值为 "some-app",并且日志行不包含 "info" 一词时,这个阶段才会执行。
- match:
selector: '{app="some-app"} != "info"'
stages:
# regex 阶段尝试通过查找日志中的 panic 来提取 panic 信息
- regex:
expression: ".*(?P<panic>panic: .*)"
# metrics 阶段将增加一个 Promtail 暴露的 panic_total 指标,只有当从上面的 regex 阶段获取到 panic 值的时候,该 Counter 才会增加。
- metrics:
panic_total:
type: Counter
description: "total count of panic"
source: panic
config:
action: inc
下面我们先简单描述下每个阶段可以使用的数据有哪些。
标签集:当前日志行的标签集合,初始化是与日志一起被抓取的标签集,标签集只由处理阶段进行修改,但过滤阶段会从中读取,最终的标签集将由 Loki 建立索引,并可用于查询。提取的键值对:在解析阶段提取的键值对集合,后续的阶段对提取的 Map 进行操作,或者对它们进行转换,或者对它们进行处理。在一个 pipeline 的末端,提取的 Map 会被丢弃掉,为了使一个解析阶段有用,它必须总要与至少一个处理阶段配对。提取的 Map 被初始化,其初始化标签是与日志行一起抓取的,这个初始数据允许在只操作提取的 Map 的 pipeline 阶段内对标签的值进行处理。例如,从文件中提取的日志条目有一个标签 filename,其值是被提取的文件路径,当一个 pipeline 执行该日志时,最初提取的 Map 将包含使用与标签相同值的文件名。日志时间戳:日志行的当前时间戳,处理阶段可以修改这个值。如果不设置,则默认为日志被抓取的时间。时间戳的最终值会发送给 Loki。日志行:当前的日志行,以文本形式表示,初始化为 Promtail 抓取的文本。处理阶段可以修改这个值。日志行的最终值将作为日志的文本内容发送给 Loki。
2阶段
上面我们结束了 Promtail 的一个 pipeline 中有 4 中类型的阶段,下面我们再分别对这 4 中类型阶段进行简单说明。
解析阶段
解析阶段包括:docker、cri、regex、json 这几个 stage。
docker
docker 阶段通过使用标签的 Docker 日志格式来解析日志数据进行数据提取。直接使用 docker: {} 即表示是一个 docker 阶段。
与大多数阶段不同,docker 阶段不提供配置选项,只支持特定的 Docker 日志格式,来自 Docker 的每一行日志都被写成 JSON 格式,其键值如下。
log:日志行的内容stream:stdout或者stderrtime:日志行的时间戳字符串
例如配置下面的 pipeline:
- docker: {}
将会解析 Docker 日志成如下所示格式:
{
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
在提取的数据集中,将创建以下键值对:
output:log message\nstream:stderrtimestamp:2019-04-30T02:12:41.8443515
cri
通过使用标准 CRI 格式解析日志行来提取数据。使用语法一样是直接使用 cri: {} 即可,与大多数阶段不同,cri 阶段不提供配置选项,只支持特定的 CRI 日志格式。CRI 指定的日志行是以空格分隔的值,有以下组成部分:
log:整个日志行的内容stream:stdout或者stderrtime:日志行的时间戳字符串
组件之间不允许有空白,在下面的例子中,只有第一行日志可以使用 cri 阶段进行正确格式化。
"2019-01-01T01:00:00.000000001Z stderr P test\ngood"
"2019-01-01 T01:00:00.000000001Z stderr testgood"
"2019-01-01T01:00:00.000000001Z testgood"
例如配置下面的 pipeline:
- cri: {}
当我们有如下所示的日志行数据:
"2019-04-30T02:12:41.8443515Z stdout xx message"
在提取的数据集中,将创建以下键值对:
output:messagestream:stdouttimestamp:2019-04-30T02:12:41.8443515
regex
使用正则表达式提取数据,在 regex 中命名的捕获组支持将数据添加到提取的 Map 映射中。配置格式如下所示:
regex:
# RE2 正则表达式,每个捕获组必须被命名。
expression: <string>
# 从指定名称中提取数据,如果为空,则使用 log 信息。
[source: <string>]
其中的 expression 是一个 Google RE2 正则表达式字符串,每个捕获组将被设置为到提取的 Map 中去,每个捕获组也必须命名:(?P<name>re),捕获组的名称将被用作提取的 Map 中的键。
另外需要注意,在使用双引号时,必须转义正则表达式中的所有反斜杠。例如下面的几个表达式都是有效的:
expression: \w*expression: '\w*'expression: "\\w*"
但是下面的这几个是无效的表达式:
expression: \\w*- 在使用双引号时才转义反斜线expression: '\\w*'- 在使用双引号时才转义反斜线expression: "\w*"- 在使用双引号的时候,反斜杠必须被转义
例如我们使用下的不带 source 的 pipeline 配置:
- regex:
expression: "^(?s)(?P<time>\\S+?) (?P<stream>stdout|stderr) (?P<flags>\\S+?) (?P<content>.*)$"
当我们要抓取的日志数据为:
2019-01-01T01:00:00.000000001Z stderr P i'm a log message!
该 pipeline 执行后以下键值对将被添加到提取的 Map 中去:
time:2019-01-01T01:00:00.000000001Zstream:stderrflags:Pcontent:i'm a log message
如果我们使用带上 source 的 pipeline 配置:
- json:
expressions:
time:
- regex:
expression: "^(?P<year>\\d+)"
source: "time"
如果需要抓取的日志数据为:
{ "time": "2019-01-01T01:00:00.000000001Z" }
则第一阶段将把以下键值对添加到提取的 Map 中:
time:2019-01-01T01:00:00.000000001Z
而 regex 阶段将解析提取的 Map 中的时间值,并将以下键值对追加到提取的 Map 中去:
year:2019
json
通过将日志行解析为 JSON 来提取数据,也可以接受 JMESPath 表达式来提取数据,配置格式如下所示:
json:
# JMESPath 表达式的键/值对集合,键将是提取的数据中的键,而表达式将是值,被评估为来自源数据的 JMESPath。
#
# JMESPath 表达式可以通过用双引号来包装一个键完成,然后在 YAML 中必须用单引号包装起来,这样它们就会被传递给 JMESPath 解析器进行解析。
expressions:
[ <string>: <string> ... ]
[source: <string>]
该阶段使用 Golang JSON 反序列化,提取的数据可以持有非字符串值,本阶段不做任何类型转换,在下游阶段将需要对这些值进行必要的类型转换,可以参考后面的 template 阶段了解如何进行转换。
注意:如果提取的值是一个复杂的类型,比如数组或 JSON 对象,它将被转换为 JSON 字符串,然后插入到提取的数据中去。
例如我们使用如下所示的 pipeline 配置:
- json:
expressions:
output: log
stream: stream
timestamp: time
要抓取的日志行数据为:
{
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
在提取的数据集中,将创建以下键值对:
output:log message\nstream:stderrtimestamp:2019-04-30T02:12:41.8443515
然后我们还可以用下面的 pipeline 配置来提前数据:
- json:
expressions:
output: log
stream: stream
timestamp: time
extra:
- json:
expressions:
user:
source: extra
要抓取的日志行数据为:
{
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z",
"extra": "{\"user\":\"marco\"}"
}
第一个 json 阶段执行后将在提取的数据集中创建以下键值对:
output:log message\nstream:stderrtimestamp:2019-04-30T02:12:41.8443515extra:{"user": "marco"}
然后经过第二个 json 阶段执行后将把提取数据中的 extra 值解析为 JSON,并将以下键值对添加到提取的数据集中:
user:marco
此外我们还可以使用 JMESPath 表达式来解析有特殊字符的 JSON 字段(比如 @ 或 .),比如我们现在有如下所示的 pipeline 配置:
- json:
expressions:
output: log
stream: '"grpc.stream"'
timestamp: time
需要抓取的日志数据如下所示:
{
"log": "log message\n",
"grpc.stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
在提取的数据集中,将创建以下键值对。
output:log message\nstream:stderrtimestamp:2019-04-30T02:12:41.8443515
需要注意的是在引用 grpc.stream 时,如果没有用单引号包裹的双引号,将无法正常工作。
转换阶段
转换阶段用于对之前阶段提取的数据进行转换。
multiline
多行阶段将多行日志进行合并,然后再将其传递到 pipeline 的下一个阶段。
一个新的日志块由第一行正则表达式来识别,任何与表达式不匹配的行都被认为是前一个匹配块的一部分。配置格式如下所示:
multiline:
# RE2 正则表达式,如果匹配将开始一个新的多行日志块
# 这个表达式必须被提供
firstline: <string>
# 解析的最大等待时间(Go duration): https://golang.org/pkg/time/#ParseDuration.
# 如果在这个最大的等待时间内没有新的日志,那么当前日志块将被继续发送。
# 如果被观察的应用程序因为异常而down掉了,该参数很有用,没有新的日志出现,并且异常块会在最大等待时间过后发送
# 默认为 3s
max_wait_time: <duration>
# 一个多行日志块有的最大行数,如果该块有更多的行,就会认为是新的日志行
# 默认为 128 行
max_lines: <integer>
比如现在我们有一个 flask 应用,下面的日志数据包含异常信息:
[2020-12-03 11:36:20] "GET /hello HTTP/1.1" 200 -
[2020-12-03 11:36:23] ERROR in app: Exception on /error [GET]
Traceback (most recent call last):
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/app.py", line 1952, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/app.py", line 1821, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/home/pallets/.pyenv/versions/3.8.5/lib/python3.8/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/pallets/src/deployment_tools/hello.py", line 10, in error
raise Exception("Sorry, this route always breaks")
Exception: Sorry, this route always breaks
[2020-12-03 11:36:23] "GET /error HTTP/1.1" 500 -
[2020-12-03 11:36:26] "GET /hello HTTP/1.1" 200 -
[2020-12-03 11:36:27] "GET /hello HTTP/1.1" 200 -
显然我们更希望将上面的 Exception 多行日志识别为一个日志块,在这个示例中,所有的日志块都是括号包括的时间开始的,所以我们可以用 firstline 正则表达式:^\[\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2}\] 来配置一个多行阶段,这将匹配上面我们的异常日志的开头部分,但是不会匹配后面的异常行,直到 Exception: Sorry, this route always breaks 这一行日志,这些将被识别为单个日志块,在 Loki 中也是以一个日志条目出现的。
multiline:
# 识别时间戳作为多行日志的第一行,注意这里字符串应该使用单引号。
firstline: '^\[\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2}\]'
max_wait_time: 3s
这个示例是假设我们对日志格式没有进行控制,所以我们需要一个更复杂的正则表达式来匹配第一行日志,但是如果我们能够控制被观察的日志格式,那么我们就可以简化第一行的匹配规则。
下面的是一个简单的 Akka HTTP 服务的日志:
[2021-01-07 14:17:43,494] [DEBUG] [akka.io.TcpListener] [HelloAkkaHttpServer-akka.actor.default-dispatcher-26] [akka://HelloAkkaHttpServer/system/IO-TCP/selectors/$a/0] - New connection accepted
[2021-01-07 14:17:43,499] [ERROR] [akka.actor.ActorSystemImpl] [HelloAkkaHttpServer-akka.actor.default-dispatcher-3] [akka.actor.ActorSystemImpl(HelloAkkaHttpServer)] - Error during processing of request: 'oh no! oh is unknown'. Completing with 500 Internal Server Error response. To change default exception handling behavior, provide a custom ExceptionHandler.
java.lang.Exception: oh no! oh is unknown
at com.grafana.UserRoutes.$anonfun$userRoutes$6(UserRoutes.scala:28)
at akka.http.scaladsl.server.Directive$.$anonfun$addByNameNullaryApply$2(Directive.scala:166)
at akka.http.scaladsl.server.ConjunctionMagnet$$anon$2.$anonfun$apply$3(Directive.scala:234)
at akka.http.scaladsl.server.directives.BasicDirectives.$anonfun$mapRouteResult$2(BasicDirectives.scala:68)
at akka.http.scaladsl.server.directives.BasicDirectives.$anonfun$textract$2(BasicDirectives.scala:161)
at akka.http.scaladsl.server.RouteConcatenation$RouteWithConcatenation.$anonfun$$tilde$2(RouteConcatenation.scala:47)
at akka.http.scaladsl.util.FastFuture$.strictTransform$1(FastFuture.scala:40)
...
简单一看和其他日志一样,我们来看看日志的格式:
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>crasher.log</file>
<append>true</append>
<encoder>
<pattern>​[%date{ISO8601}] [%level] [%logger] [%thread] [%X{akkaSource}] - %msg%n</pattern>
</encoder>
</appender>
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>1024</queueSize>
<neverBlock>true</neverBlock>
<appender-ref ref="STDOUT" />
</appender>
<root level="DEBUG">
<appender-ref ref="ASYNC"/>
</root>
</configuration>
对于 Logback 配置来说,没有什么特别之处,除了在每个日志行的开头有一个 ​,这是零宽度空格的 HTML 代码,它使得识别第一行变得更加简单了,这里我们使用的第一行匹配正则表达式为:\x{200B}\[,200B 是零宽度空格字符的 Unicode 编码:
multiline:
# 将零宽度的空格确定为多行块的第一行,注意该字符串应使用单引号。
firstline: '^\x{200B}\['
max_wait_time: 3s
template
template 阶段可以使用 Go 模板语法来操作提取的数据。模板阶段主要用于在将数据设置为标签之前对其他阶段的数据进行操作,例如用下划线替换空格,或者将大写的字符串转换为小写的字符串。模板也可以用来构建具有多个键的信息。模板阶段也可以在提取的数据中创建新的键。
配置格式如下所示:
template:
# 要解析的提取数据中的名称,如果提前数据中的key不存在,将为其添加一个新的值
source: <string>
# 使用的 Go 模板字符串。 除了正常的模板之外
# functions, ToLower, ToUpper, Replace, Trim, TrimLeft, TrimRight,
# TrimPrefix, TrimSuffix, and TrimSpace 都是可以使用的函数。
template: <string>s
比如下面的 pipeline 配置:
- template:
source: new_key
template: "hello world!"
假如还没有任何数据被添加到提取的数据中,这个阶段将首先在提取的数据 Map 中添加一个空白值的 new_key,然后它的值将被设置为 hello world!。
在看下面的模板阶段配置:
- template:
source: app
template: "{{ .Value }}_some_suffix"
这个 pipeline 在现有提取的数据中获取键为 app 的值,并将 _som_suffix 附加到值后面。例如,如果提前的数据 Map 的键为 app,值为 loki,那么这个阶段将把值从 loki 修改为 loki_som_suffix。
- template:
source: app
template: "{{ ToLower .Value }}"
这个 pipeline 从提取的数据中获取键为 app 的值,并将其值转换为小写。例如,如果提取的数据键 app 的值为 LOKI,那么这个阶段将把值转换为小写的 loki。
- template:
source: output_msg
template: "{{ .level }} for app {{ ToUpper .app }}"
这个 pipeline 从提取的数据中获取 level 与 app 的值,一个新的 output_msg 将被添加到提取的数据中,值为上面模板的计算结果。
例如,如果提取的数据中包含键为 app,值为 loki 的数据,level 的值为 warn,那么经过该阶段后会添加一个新的数据,键为 output_msg,其值为 warn for app LOKI。
任何先前提取的键都可以在模板中使用,所有提取的键都可用于模板的扩展。
- template:
source: app
template: "{{ .level }} for app {{ ToUpper .Value }} in module {{.module}}"
上面的这个 pipeline 从提取的数据中获取 level、app 和 module 值。例如,如果提取的数据包含值为 loki 的 app,level 的值为 warn,moudule 的值为 test,则这个阶段会将提取数据 app 的值更改为 warn for app LOKI in module test。
任何之前获取的键都可以在模板中使用,此外,如果 source 是可用的,它可以在模板中被称为 .Value,我们这里 app 被当成了 source,所以它可以在模板中通过 .Value 使用。
- template:
source: app
template: '{{ Replace .Value "loki" "blokey" 1 }}'
这里的模板使用 Go 的 string.Replace函数,当模板执行时,从提取的 Map 数据中的键为 app 的全部内容将最多有 1 个 loki 的实例被改为 blokey。
另外有一个名为 Entry 的特殊键可以用来引用当前行,当你需要追加或预设日志行的时候,这应该会很有用。
- template:
source: message
template: "{{.app }}: {{ .Entry }}"
- output:
source: message
例如,上面的片段会在日志行前加上应用程序的名称。
在 Loki2.3 中,所有的 sprig 函数都被添加到了当前的模板阶段,包括 ToLower & ToUpper、Replace、Trim、Regex、Hash 和 Sha2Hash 函数。
处理阶段
用于从以前阶段中提取数据并对其进行处理。
timestamp
设置日志条目的时间戳值,当时间戳阶段不存在时,日志行的时间戳默认为日志条目被抓取的时间。
配置格式如下所示:
timestamp:
source: <string>
# 解析时间字符串的格式,可以只有预定义的格式有:[ANSIC UnixDate RubyDate RFC822
# RFC822Z RFC850 RFC1123 RFC1123Z RFC3339 RFC3339Nano Unix
# UnixMs UnixUs UnixNs].
format: <string>
# 如果格式无法解析,可尝试的 fallback 的格式
[fallback_formats: []<string>]
# IANA 时区数据库字符串
[location: <string>]
# 在时间戳无法提取或解析的情况下,应采取何种行动。有效值为:[skip, fudge],默认为 fudge。
[action_on_failure: <string>]
其中的 format 字段可以参考格式如下所示:
ANSIC:Mon Jan \_2 15:04:05 2006UnixDate:Mon Jan_2 15:04:05 MST 2006RubyDate:Mon Jan 02 15:04:05 -0700 2006RFC822:02 Jan 06 15:04 MSTRFC822Z:02 Jan 06 15:04 -0700RFC850:Monday, 02-Jan-06 15:04:05 MSTRFC1123:Mon, 02 Jan 2006 15:04:05 MSTRFC1123Z:Mon, 02 Jan 2006 15:04:05 -0700RFC3339:2006-01-02T15:04:05-07:00RFC3339Nano:2006-01-02T15:04:05.999999999-07:00
另外支持常见的 Unix 时间戳:
Unix: 1562708916 or with fractions 1562708916.000000123UnixMs: 1562708916414UnixUs: 1562708916414123UnixNs: 1562708916000000123
自定义格式是直接传递给 GO 的 time.Parse 函数中的 layout 参数,如果自定义格式没有指定 year,Promtail 会认为应该使用系统时钟的当前年份。
自定义格式使用的语法是使用时间戳的每个组件的特定值来定义日期和时间(例如 Mon Jan 2 15:04:05 -0700 MST 2006),下表显示了应在自定义格式中支持的参考值。
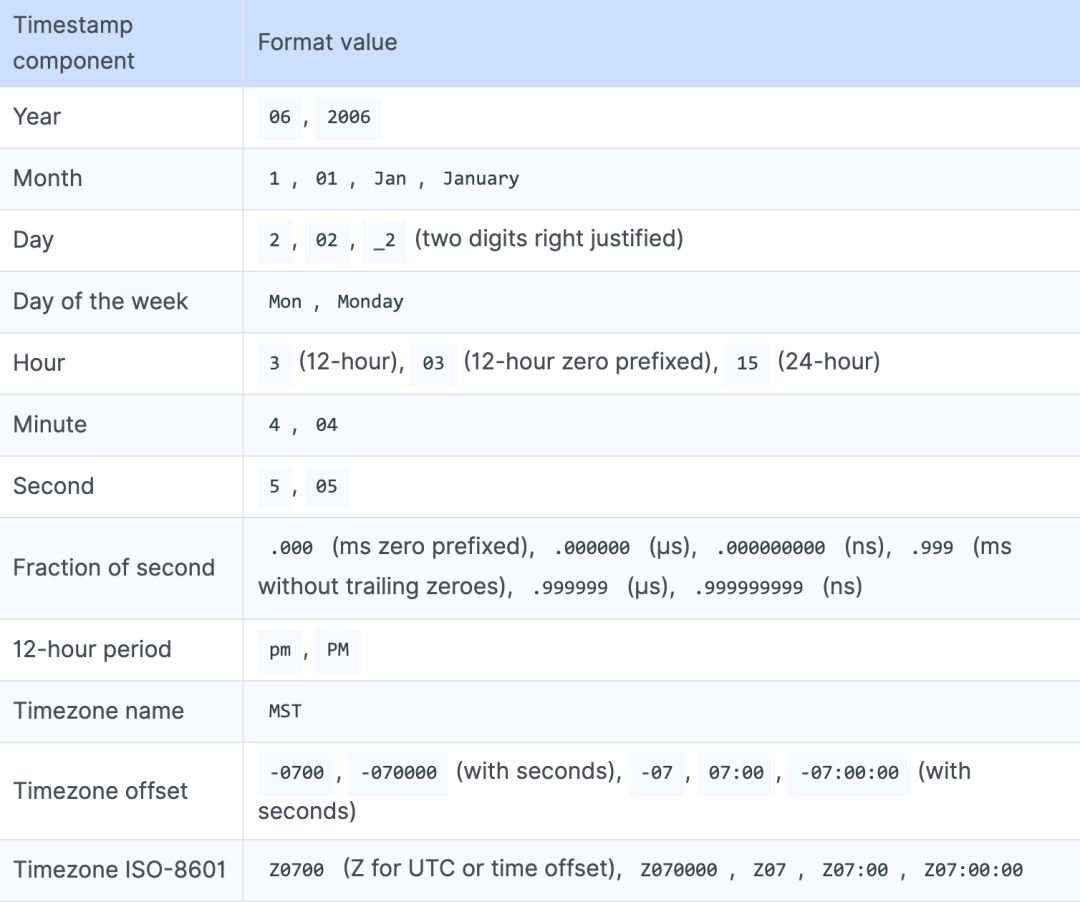
action_on_failure 设置定义了在提取的数据中不存在 source 字段或时间戳解析失败的情况下,应该如何处理,支持的动作有:
fudge(默认):将时间戳更改为最近的已知时间戳,总计 1 纳秒(以保证日志顺序)skip:不改变时间戳,保留日志被 Promtail 抓取的时间
比如使用下面的 pipeline 配置:
- timestamp:
source: time
format: RFC3339Nano
经过上面的 timestamp 阶段在提取的数据中查找一个 time 字段,并以 RFC3339Nano 格式化其值(例如,2006-01-02T15:04:05.9999999-07:00),所得的时间值将作为时间戳与日志行一起发送给 Loki。
output
设置日志行文本,配置格式如下所示:
output:
source: <string>
比如我们有一个如下配置的 pipeline:
- json:
expressions:
user: user
message: message
- labels:
user:
- output:
source: message
需要收集的日志为:
{ "user": "alexis", "message": "hello, world!" }
在经过第一个 json 阶段后将提前以下键值对到数据中:
user:alexismessage:hello, world!
然后第二个 label 阶段将把 user=alexis 添加到输出的日志标签集中,最后的 output 阶段将把日志数据从原来的 JSON 更改为 message 的值 hello, world! 输出。
labels
更新日志的标签集,并一起发送给 Loki。配置格式如下所示:
labels:
# Key 是必须的,是将被创建的标签名称。
# Values 是可选的,提取的数据中的名称,其值将被用于标签的值。
# 如果是空的,值将被推断为与键相同。
[ <string>: [<string>] ... ]
比如我们有一个如下所示的 pipeline 配置:
- json:
expressions:
stream: stream
- labels:
stream:
需要处理的日志数据为:
{
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
第一个 json 阶段将提取 stream 到 Map 数据中,其值为 stderr。然后在第二个 labels 阶段将把这个键值对变成一个标签,在发送到 Loki 的日志行中将包括标签 stream,值为 stderr。
metrics
根据提取的数据计算指标。需要注意的是,创建的 metrics 指标不会被推送到 Loki,而是通过 Promtail 的 /metrics 端点暴露出去,Prometheus 应该被配置为可以抓取 Promtail 的指标,以便能够检索这个阶段所配置的指标数据。
配置格式如下所示:
# 一个映射,key为metric的名称,value是特定的metric类型
metrics:
[<string>: [ <metric_counter> | <metric_gauge> | <metric_histogram> ] ...]
metric_counter:定义一个 Counter 类型的指标,其值只会不断增加。 metric_gauge:定义一个 Gauge 类型的指标,其值可以增加或减少。 metric_histogram:定义一个直方图指标。
比如我们有一个如下所示的 pipeline 配置用于定义一个 Counter 指标:
- metrics:
log_lines_total:
type: Counter
description: "total number of log lines"
prefix: my_promtail_custom_
max_idle_duration: 24h
config:
match_all: true
action: inc
log_bytes_total:
type: Counter
description: "total bytes of log lines"
prefix: my_promtail_custom_
max_idle_duration: 24h
config:
match_all: true
count_entry_bytes: true
action: add
这个流水线先创建了一个 log_lines_total 的 Counter,通过使用 match_all: true 参数为每一个接收到的日志行增加。
然后还创建了一个 log_bytes_total 的 Counter 指标,通过使用 count_entry_bytes: true 参数,将收到的每个日志行的字节大小加入到指标中。
这两个指标如果没有收到新的数据,将在 24h 后小时。另外这些阶段应该放在 pipeline 的末端,在任何标签阶段之后。
- regex:
expression: "^.*(?P<order_success>order successful).*$"
- metrics:
successful_orders_total:
type: Counter
description: "log lines with the message `order successful`"
source: order_success
config:
action: inc
比如上面这个 pipeline 首先尝试在日志中找到成功的订单,将其提取为 order_success 字段,然后在 metrics 阶段创建一个名为 successful_orders_total 的 Counter 指标,其值是在只有提取的数据中有 order_success 的时候才会增加。这个 pipeline 的结果是一个指标,其值只有在 Promtail 抓取的日志中带有 order successful 文本的日志时才会增加。
- regex:
expression: "^.* order_status=(?P<order_status>.*?) .*$"
- metrics:
successful_orders_total:
type: Counter
description: "successful orders"
source: order_status
config:
value: success
action: inc
failed_orders_total:
type: Counter
description: "failed orders"
source: order_status
config:
value: fail
action: inc
上面这个 pipeline 首先会尝试在日志中找到格式为 order_status=<value> 的文本,将 <value> 提取到 order_status 中。该指标阶段创建了 successful_orders_total 和 failed_orders_total 指标,只有当提取数据中的 order_status 的值分别为 success 或 fail 时才会增加。
tenant
设置日志要使用的租户 ID 值,从提取数据中的一个字段获取,如果该字段缺失,将使用默认的 Promtail 客户端租户 ID。配置格式如下所示:
tenant:
# source 或 value 配置选项是必须的,但二者不能同时使用(它们是互斥的)
[ source: <string> ]
# 当前阶段执行时用来设置租户 ID 的值。
# 当这个阶段被包含在一个带有 "match" 的条件管道中时非常有用。
[ value: <string> ]
比如我们有如下所示的 pipeline 配置:
pipeline_stages:
- json:
expressions:
customer_id: customer_id
- tenant:
source: customer_id
需要获取的日志数据为:
{
"customer_id": "1",
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
第一个 json 阶段将提取 customer_id 的值到 Map 中,值为 1。在第二个租户阶段将把 X-Scope-OrgID 请求 Header 头(Loki 用来识别租户)设置为提取的 customer_id 的值,也就是 1.
另外一种场景是用配置的值来覆盖租户 ID,如下所示的 pipeline 配置:
pipeline_stages:
- json:
expressions:
app:
message:
- labels:
app:
- match:
selector: '{app="api"}'
stages:
- tenant:
value: "team-api"
- output:
source: message
需要收集的日志数据为:
{
"app": "api",
"log": "log message\n",
"stream": "stderr",
"time": "2019-04-30T02:12:41.8443515Z"
}
这个 pipeline 将:
Decode JSON 日志 设置标签 app="api"处理匹配阶段,检查 {app="api"}选择器是否匹配,如果匹配了则执行子阶段,也就是这里的租户阶段,覆盖值为"team-api"的租户。
此外在处理阶段还有 labeldrop 阶段,它从标签集中删除标签,这些标签与日志条目一起被发送到 Loki。还有一个 labelallow 阶段,它只允许将所提供的标签包含在与日志条目一起发送给 Loki 的标签集中。
过滤阶段
可选择应用一个阶段的子集,或根据一些条件删除日志数据。
match
当一个日志条目与可配置的 LogQL 流选择器和过滤表达式相匹配时,有条件地应用一组阶段或删除日志数据。配置语法格式如下所示:
match:
# LogQL 流选择器合过滤表达式。
selector: <string>
# pipeline 名称,当定义的时候,在 pipeline_duration_seconds 直方图中创建一个额外的标签,该值与 job_name 使用下划线连接。
[pipeline_name: <string>]
# 决定当选择器与日志行匹配时采取什么动作。
# 默认是 keep,当设置为 drop 时,日志将被删除,以后的指标将不会被记录。
[action: <string> | default = "keep"]
# 如果你指定了 `action: drop` 那么 `logentry_dropped_lines_total` 这个指标将为每一个被丢弃的行而增加
# 默认情况下,reaseon 标签是 `match_stage`,但是你可以选择指定一个自定义值用于该指标的 `reason` 标签。
[drop_counter_reason: <string> | default = "match_stage"]
# 只有当选择器与日志的标签相匹配时,才会出现嵌套的流水线阶段:
stages:
- [
<regex_stage>
<json_stage> |
<template_stage> |
<match_stage> |
<timestamp_stage> |
<output_stage> |
<labels_stage> |
<metrics_stage> |
<tenant_stage>
]
比如我们现在有一个如下所示的 pipeline 配置:
pipeline_stages:
- json:
expressions:
app:
- labels:
app:
- match:
selector: '{app="loki"}'
stages:
- json:
expressions:
msg: message
- match:
pipeline_name: "app2"
selector: '{app="pokey"}'
action: keep
stages:
- json:
expressions:
msg: msg
- match:
selector: '{app="promtail"} |~ ".*noisy error.*"'
action: drop
drop_counter_reason: promtail_noisy_error
- output:
source: msg
要处理的日志数据为:
{ "time":"2012-11-01T22:08:41+00:00", "app":"loki", "component": ["parser","type"], "level" : "WARN", "message" : "app1 log line" }
{ "time":"2012-11-01T22:08:41+00:00", "app":"promtail", "component": ["parser","type"], "level" : "ERROR", "message" : "foo noisy error" }
第一个 json 阶段将在第一个日志行的提取 Map 数据中添加值 app=loki,然后经过第二个 labels 阶段将 app 转换成一个标签。对于第二行日志也遵循同样的流程,只是值变成了 promtail。
然后在第三个 match 阶段使用 LogQL 表达式 {app="loki"} 进行匹配,只有在标签 app=loki 的时候才会执行嵌套 json 阶段,这里合我们的第一行日志是匹配的,然后嵌套的 json 阶段将 message 数据提取到 Map 数据中,key 变成了 msg,值为 app1 log line。
接下来执行第四个 match 阶段,需要匹配 app="pokey",很显然这里我们都不匹配,所以嵌套的 json 子阶段不会被执行。
然后执行的第五个 match 阶段,将会删掉任何具有 app="promtail" 标签并包括 noisy error 文本的日志数据,并且还将增加 logentry_drop_lines_total 指标,标签为 reason="promtail_noisy_error"。
最后的 output 输出阶段将日志行的内容改为提取数据中的 msg 的值。我们这里的示例最后输出为 app1 log line。
drop
drop 阶段可以让我们根据配置来删除日志。需要注意的是,如果你提供多个选项配置,它们将被视为 AND 子句,其中每个选项必须为真才能删除日志。如果你想用一个 OR子句来删除,那么就指定多个删除阶段。配置语法格式如下所示:
drop:
[source: <string>]
# RE2 正则表达式,如果提供了 source,则会尝试匹配 source
# 如果没有提供 source,则会尝试匹配日志行数据
# 如果提供的正则匹配了日志行或者 source,则该行日志将被删除。
[expression: <string>]
# 只有在指定 source 源的情况下才能指定 value 值。
# 指定 value 与 regex 是错误的。
# 如果提供的值与`source`完全匹配,该行将被删除。
[value: <string>]
# older_than 被解析为 Go duration 格式
# 如果日志行的时间戳大于当前时间减去所提供的时间,则将被删除
[older_than: <duration>]
# longer_than 是一个以 bytes 为单位的值,任何超过这个值的日志行都将被删除。
# 可以指定为整数格式的字节数:8192,或者带后缀的 8kb
[longer_than: <string>|<int>]
# 每当一个日志行数据被删除,指标 `logentry_dropped_lines_total` 都会增加。
# 默认的 reason 标签是 `drop_stage`,然而你可以选择指定一个自定义值,用于该指标的 "reason" 标签。
[drop_counter_reason: <string> | default = "drop_stage"]
比如我们有一个如下所示的简单 drop 阶段配置:
- drop:
expression: ".*debug.*"
该阶段将删除任何带有 debug 字样的日志行。
如果是下面的配置示例:
- json:
expressions:
level:
msg:
- drop:
source: "level"
expression: "(error|ERROR)"
则下面的日志数据都将被删除:
{"time":"2019-01-01T01:00:00.000000001Z", "level": "error", "msg":"11.11.11.11 - "POST /loki/api/push/ HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"}
{"time":"2019-01-01T01:00:00.000000001Z", "level": "ERROR", "msg":"11.11.11.11 - "POST /loki/api/push/ HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"}
然后使用下面的配置来删除老的日志数据:
- json:
expressions:
time:
msg:
- timestamp:
source: time
format: RFC3339
- drop:
older_than: 24h
drop_counter_reason: "line_too_old"
需要注意的是为了让
old_than发挥作用,你必须在应用 drop 阶段之前,使用时间戳阶段来设置抓取日志行的时间戳。
比如当前的摄取时间为 2021-05-01T12:00:00Z,当从文件中读取时,会删除这个日志行:
{"time":"2021-05-01T12:00:00Z", "level": "error", "msg":"11.11.11.11 - "POST /loki/api/push/ HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"}
但是下面的日志数据不会被删除:
{"time":"2021-05-03T12:00:00Z", "level": "error", "msg":"11.11.11.11 - "POST /loki/api/push/ HTTP/1.1" 200 932 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.9.1.7) Gecko/20091221 Firefox/3.5.7 GTB6"}
在这个例子中,当前时间是 ``2021-05-03T16:00:00Z,older_than是 24h。所有时间戳超过2021-05-02T16:00:00Z` 的日志行都将被删除。
这个删除阶段删除的所有行也将增加 logentry_drop_lines_total 指标,并标明原因为 "line_too_old"。
下面是另外一个复杂点的配置:
- json:
expressions:
time:
msg:
- timestamp:
source: time
format: RFC3339
- drop:
older_than: 24h
- drop:
longer_than: 8kb
- drop:
source: msg
regex: ".*trace.*"
上面的 pipeline 执行后将删除掉所有超过 24 小时或者超过 8kb 的日志或者 json 的 msg 值中包含 trace 字样的日志。
