机器学习中的参数与非参数方法数据派THU关注共 1394字,需浏览 3分钟 ·2021-11-24 03:46 来源:DeepHub IMBA作者:Giorgos Myrianthous本文约1000字,建议阅读6分钟 我们将讨论机器学习背景下的参数和非参数方法。介绍在我们的以前文章中介绍过统计学习中预测和推理之间的区别。尽管这两种方法的主要区别在于最终目标,但我们都需要估计一个未知函数f。换句话说,我们需要学习一个将输入(即自变量X的集合)映射到输出(即目标变量Y)的函数,如下图所示。Y = f(X) + ε为了估计未知函数,我们需要在数据上拟合一个模型。我们试图估计的函数的形式通常是未知的,因此我们可能不得不应用不同的模型来得到它,或者对函数f的形式做出一些假设。一般来说,这个过程可以是参数化的,也可以是非参数化的。在今天的文章中,我们将讨论机器学习背景下的参数和非参数方法。此外,我们将探讨它们的主要差异以及它们的主要优点和缺点。参数化方法在参数化方法中,我们通常对函数f的形式做一个假设。例如,你可以假设未知函数f是线性的。换句话说,我们假设函数是这样的。其中f(X)为待估计的未知函数,β为待学习的系数,p为自变量个数,X为相应的输入。既然我们已经对要估计的函数的形式做出了假设,并选择了符合这个假设的模型,那么我们需要一个学习过程,这个学习过程最终将帮助我们训练模型并估计系数。机器学习中的参数化方法通常采用基于模型的方法,我们对要估计的函数的形式做出假设,然后根据这个假设选择合适的模型来估计参数集。参数化方法最大的缺点是,我们所做的假设可能并不总是正确的。例如,你可以假设函数的形式是线性的,但实际上它并不是。因此这些方法涉及较不灵活的算法,通常用于解决一些不复杂的问题。参数化方法速度非常快,而且它们需要的数据也少得多(更多相关内容将在下一节中介绍)。此外,由于参数化方法虽然不太灵活但是因为基于我们做出的假设,所以它们更容易解释。机器学习中的参数化方法包括线性判别分析、朴素贝叶斯和感知器。非参数方法一般来说非参数方法指的是对于要估计的函数的形式不做任何潜在的假设的一组算法。由于没有做任何假设,这种方法可以估计未知函数f的任何形式。非参数方法往往更精确,因为它们寻求最佳拟合数据点。但是这是以需要进行大量的观测为代价的(这些观测是精确估计未知函数f所必需的)。并且这些方法在训练模型时往往效率较低。另外的一个问题是,非参数方法有时可能会引入过拟合,因为由于这些算法更灵活,它们有时可能会以无法很好地泛化到新的、看不见的数据点的方式学习错误和噪声。非参数方法非常灵活,因为没有对底层函数做出任何假设,所以可以带来更好的模型性能。机器学习中一些非参数方法的例子包括支持向量机和kNN。总结在今天的文章中,我们讨论了机器学习背景下的参数化和非参数化方法以及它们的优点和缺点。参数方法往往不太灵活和准确,但更具可解释性,而非参数方法往往更灵活(因此适用于更复杂的问题)和准确但可解释性较差。尽管参数方法不太灵活并且有时不太准确,但它们在许多用例中仍然有用,因为在更简单的问题中使用非常灵活的非参数方法可能会导致过度拟合。编辑:文婧 浏览 51点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 【机器学习与统计学】参数与非参数方法BrainTechnology0【机器学习】四种超参数搜索方法在建模时模型的超参数对精度有一定的影响,而设置和调整超参数的取值,往往称为调参。 在实践中调参往往依赖人工来进行设置调整范围,然后使用机器在超参数范围内进行搜素。本文将演示在sklearn中支持的四种基础超参...机器学习4个常用超参数调试方法!Datawhale0机器学习 4 个超参数搜索方法、代码恋习Python0机器学习 4 个超参数搜索方法、代码数据分析14800机器学习 4 个常用超参数调试方法!数据分析14800【机器学习】算法模型自动超参数优化方法机器学习初学者0实用非参数统计非参数统计是21世纪统计理论的三大发展方向之一。标准的参数方法强烈地依赖于对数据分布的假设,而非参数实用非参数统计实用非参数统计0现代非参数统计现代非参数统计0点赞 评论 收藏 分享 手机扫一扫分享分享 举报

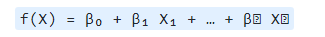
 下载APP
下载APP