
用 BOX-COX 变换进行数据正态性处理

笔者之前写了题为《用Python讲解偏度和峰度》的文章,在那篇文章里,笔者介绍了偏度、峰度以及如何基于二者进行数据正态性的判断,而今天笔者将介绍一下如何将数据进行正态性转换。
在我们进行数据分析时,遇到的数据往往不是呈正态分布的,而如果数据不是正态性的,那么在部分情况下会带来一些问题。比如某些模型的前提就是要求数据具有正态性(KNN、贝叶斯等),此外数据具有正态性可以在一定程度上提高机器学习的训练效果。
那么将非正态分布的数据转为正态分布有哪些方法呢?笔者在这里简单介绍几种常见的方法。第一种是对数据取平方根,这种方法常用于泊松分布数据,第二种是取对数,在对数正态分布数据中常用,这两种方法都要求数据非负,当然可以给这些数据都加一个常数使其为正值。还有一种方法是对数据取到数,常用于有极值的情况。但笔者今天介绍的方法和上面三种都不同,这种方法名为BOX-COX变换法。之所以介绍这种方法,是因为很多读者对这种方法不是太熟悉,想让大家更好地了解一下,同时这种方法在金融领域应用较多,笔者之前做过一些金融方面的数据分析,所以把这种方法拿出来重点介绍一下。
下面首先还是对BOX-COX变换做一个简单的介绍。
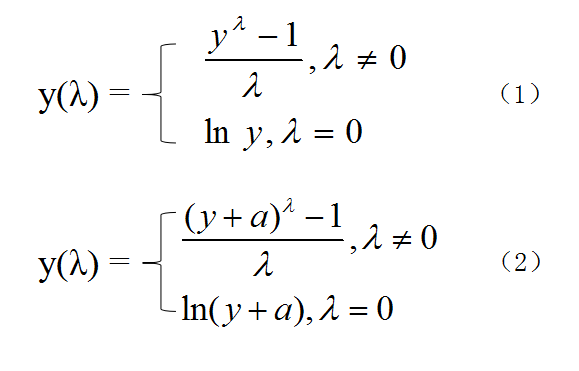
图1. BOX-COX变换的公式
BOX-COX变换是由博克斯(Box)与考克斯(Cox)在1964年提出的一种非常广泛的变换方法,它是对因变量y作如图1中式(1)的变换,式中λ是待定参数。此变换要求y的各分量都大于0,否则就要用另一种方式作BOX-COX变换,如图1中式(2)所示。这种方法先对y做平移,使y+a的各个分量都大于0,然后再做BOX-COX变换。对于不同的λ,所作的变换也不同,所以这是一个变换族,它包含一些常用操作,如对数变换(λ=0),平方根变换(λ=0.5),以及倒数变换(λ=-1)。
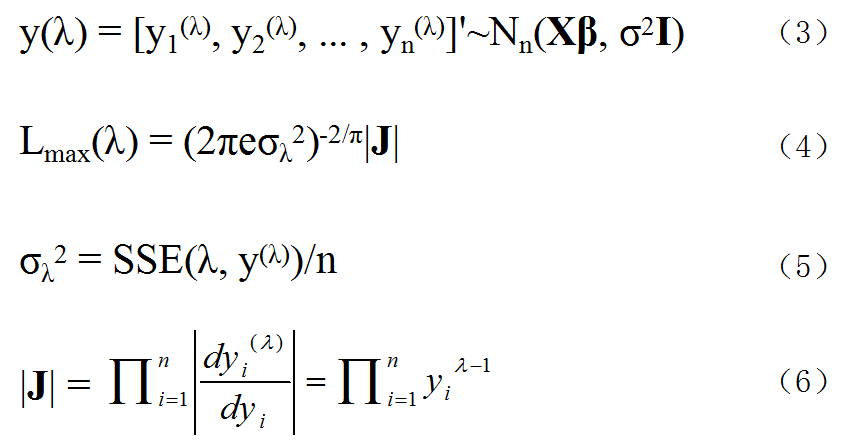
图2. BOX-COX变换的部分推导公式
通过此变换,我们寻找合适的λ,使得变换后图2中式(3)符合线性回归模型的各项假设:误差各分量等方差、不相关等。事实上,BOX-COX变换不仅可以处理异方差问题,还能处理自相关、误差非正态、回归函数非线性等情况。
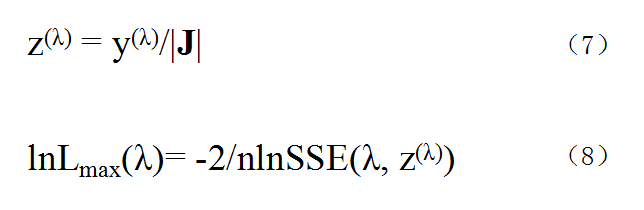
图3. BOX-COX变换的部分推导公式
经过计算可得λ的最大似然估计为图2中式(4),而式(5)和(6)也都与(4)相关联。而通过图3中式(7)的变换,我们可以得到式(8)。为找出λ,使得Lmax(λ)最大,只需使SSE最小即可,它的解析解比较难找,通常是给出一系列λ的值,计算相应的SSE,取最小SSE所对应的λ即可。
在了解了BOX-COX变换基本原理之后我们就直接用python代码来说明一下其具体应用。在scipy的stats模块当中直接集成了BOX-COX方法,所以我们就利用该方法。
首先还是导入各种库。
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
笔者在这里将用两个例子来说明BOX-COX变换的应用。首先我们来看一个比较特殊的例子。这个例子来自帕累托分布,帕累托分布原理如图4所示,其在实际生活中非常常见,比如石油的储量、社会财富的分布、人类居住区的大小等都是近似帕累托分布。我们首先生成服从帕累托分布的数据,然后再作出分布直方图。这里stats.lomax(c=14).rvs(size=500)这行代码中,lomax方法就是scipy中生成帕累托数据的方法,c=14是生成某个状态(或者说是形状)的数据,这个值可以随意设置。rvs是生成数据的方法,这里生成500个数值。
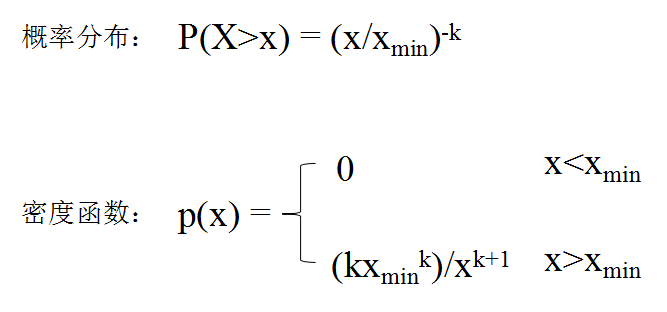
图4. 帕累托分布介绍
fig, ax = plt.subplots(figsize=[12,8])
data1 = stats.lomax(c=14).rvs(size=500) #生成帕累托分布数据,数据每次生成时可能不同
sns.distplot(data1)
plt.show()
结果如图5所示。从图中我们可以明显看出,该数据的分布不服从正态分布,而是一个右偏分布,数据比较集中于0到2之间。接下来我们对其进行BOX-COX变换,代码如下。这里stats.boxcox就是对原数据进行转换,会返回两个值,第一个值就是转换后的数据,所以我们取第一个值。
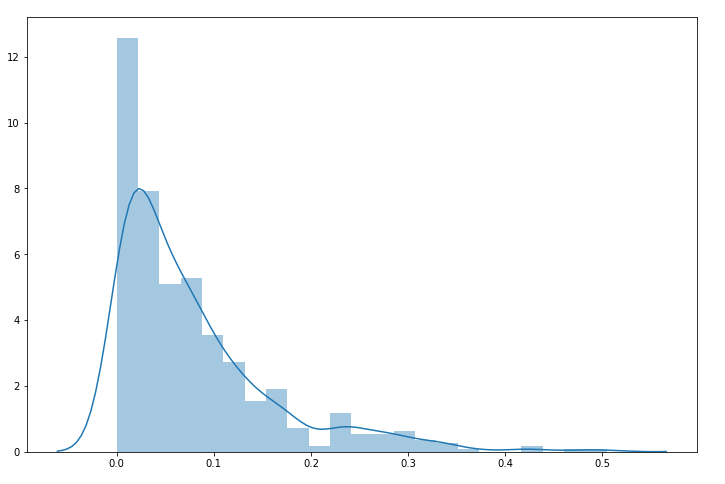
图5. 帕累托数据直方图
fig, ax = plt.subplots(figsize=[12,8])
converted_data1 = stats.boxcox(data1)[0] #对数据进行BOX-COX变换
sns.distplot(converted_data1)
plt.show()
结果如图6所示。从图中可以看出,该分布已经有了很明显的正态分布的特征,接下来我们再进一步验证一下。
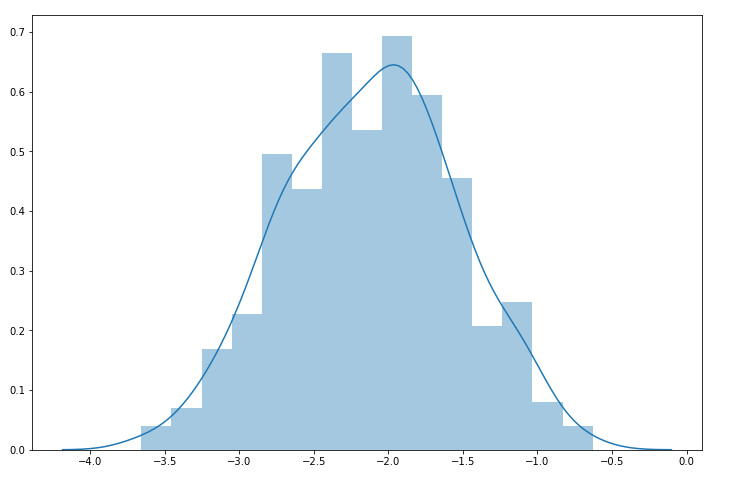
图6. 转换后的帕累托数据直方图
fig, ax = plt.subplots(figsize=[12,8])
prob = stats.probplot(converted_data1, dist=stats.norm, plot=ax) #生成Q-Q图
plt.show()
结果如图7所示。图7是一个Quantile-Quantile Plot,就是我们平常所说的Q-Q图。Q-Q图是将一组数据作为参考,另一组数据作为样本,样本数据每个值在样本数据集中的百分位数(percentile)作为其在Q-Q图上的横坐标值,而该值放到参考数据集中时的百分位数作为其在Q-Q图上的纵坐标。一般我们会在Q-Q图上做一条45度的参考线。如果两组数据来自同一分布,那么样本数据集的点应该都落在参考线附近;反之如果距离越远,这说明这两组数据很可能来自不同的分布。可以看到绝大部分数据就分布于这条红线附近,可以判断我们转换过后的数据已经是服从正态分布了。
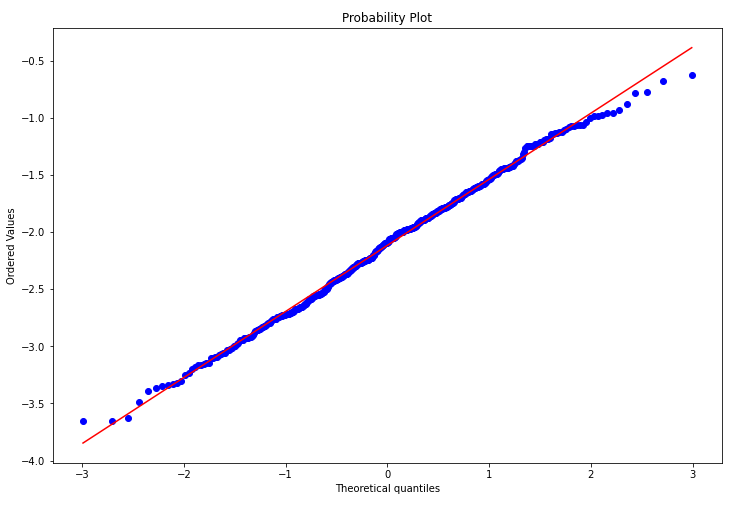
图7. 转换后的帕累托数据的Q-Q图
接下来再来看一个指数分布的例子。我们随机生成一个指数分布的数据集,再将其通过BOX-COX变换,转换成正态分布的数据,代码如下。
state = np.random.RandomState(20) #设置随机状态
data2 = state.exponential(size = 500) #生成指数分布数据集
converted_data2 = stats.boxcox(data2)[0] #将数据进行BOX-COX变换
然后再分别绘制原数据和经过BOX-COX变换后的数据的直方图。
fig, ax = plt.subplots(figsize=[12,8])
sns.distplot(data2) #绘制原始指数分布数据的直方图
plt.show()
fig, ax = plt.subplots(figsize=[12,8])
sns.distplot(converted_data2) #绘制转换后数据的直方图
plt.show()
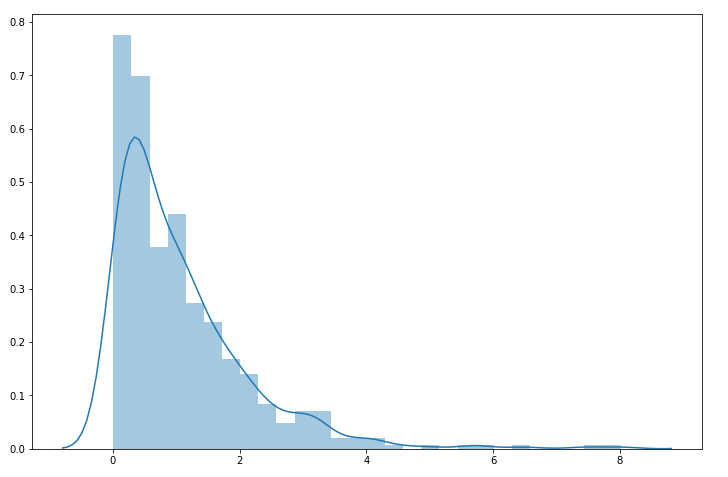
图8. 指数分布数据直方图
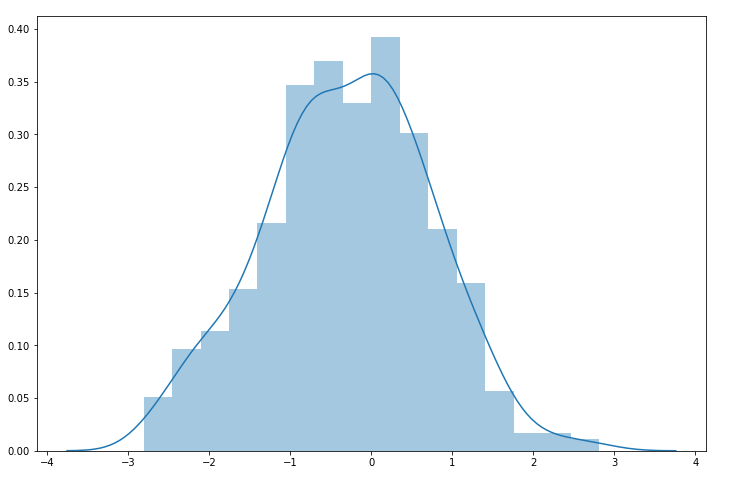
图9. 转换后的指数分布数据直方图
结果如图8和图9所示。通过对比图8和图9,我们可以看到数据经过转换之后,正态性明显有了改善,但我们还要验证一下。这里我们不再用前面例子中的验证方法,而是使用另外一种方法,代码如下。
k1, p1 = stats.normaltest(data2)
k2, p2 = stats.normaltest(converted_data2)
这里stats.normaltest就是检验数据正态性的方法,该方法也会返回两个值,其中第二个是假设检验中常用到的P值,我们用这个值来判断数据是否具有正态性。我们得到的p1值为5.580577119276143e-57,这个值几乎为0,说明该数据不服从正态分布,而p2值为0.5322400503708197,说明该数据大概率服从正态分布。这也说明BOX-COX变换对原数据的转换效果还是很好的。
本文通过两个例子来说明BOX-COX变换对非正态分布数据的转换,也介绍了一些scipy当中数据正态性验证的方法。对于BOX-COX变换更深入的使用,感兴趣的读者也可以自行查找相关资料。
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。
赞赏作者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
长按扫码添加“Python小助手”后
回复“正态”获取本文全部代码
▼点击成为社区会员 喜欢就点个在看吧