
无需人力标注!悉尼大学华人团队提出「GPT自监督标注」范式,完美解决标注成本、偏见、评估问题
新智元
共 2594字,需浏览 6分钟
·
2023-06-19 18:32

新智元报道
新智元报道
【新智元导读】最近,来自悉尼大学的研究人员提出了一种GPT自监督注释方法,能够将数据注释为简洁摘要,并在各种注释任务中展现出卓越的性能。

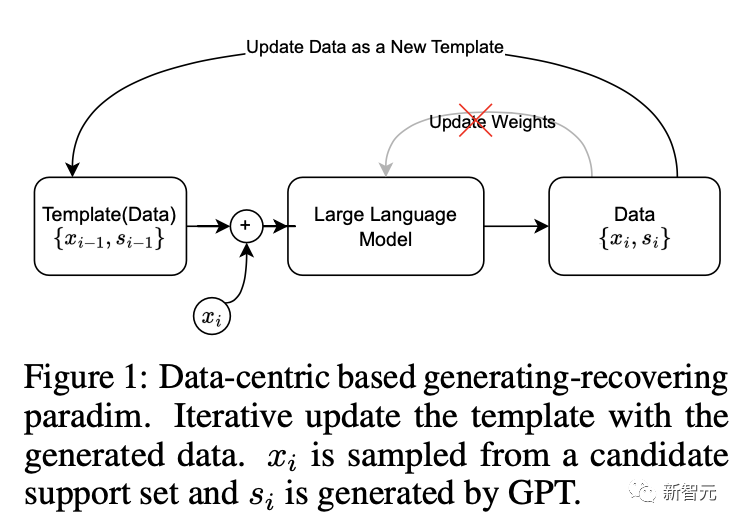
数据标注困难重重
在美国,数据标注员的平均年薪约为39,000美元,最高可达49,803美元[2]。即使在印度,数据标注员的平均年薪约为2.0 Lakhs卢比,约合2,670美元[3]。
全新标注方法
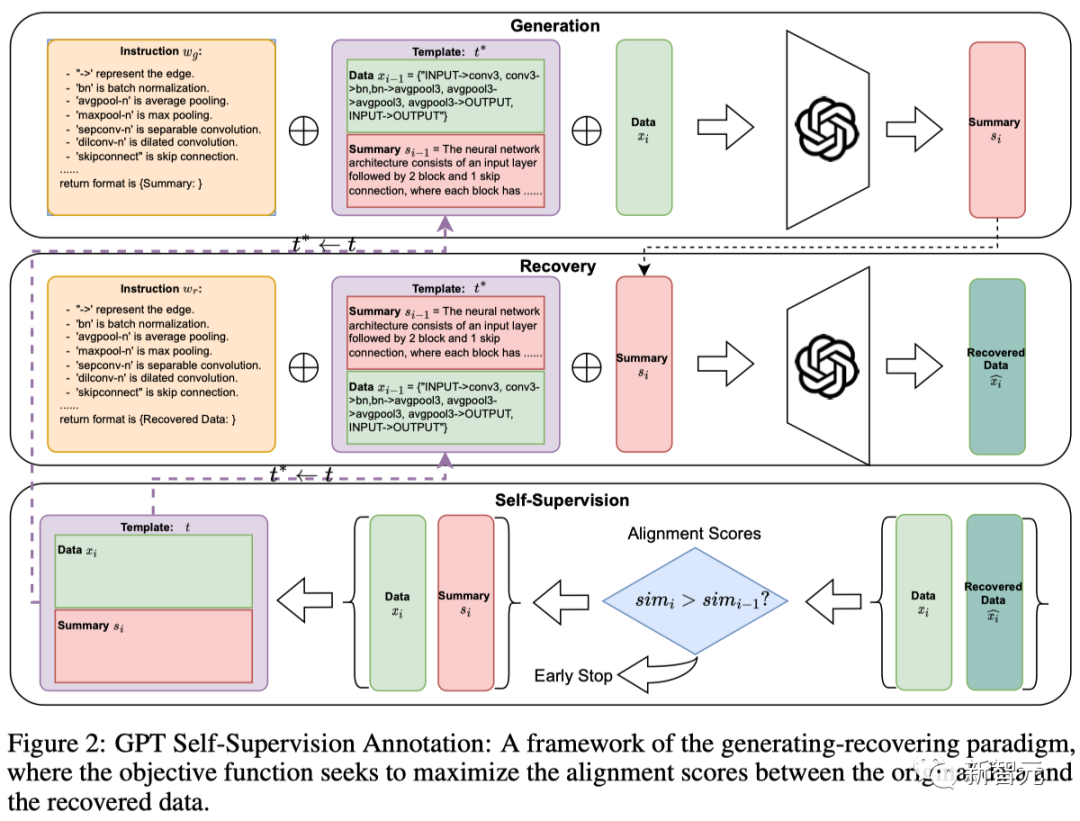
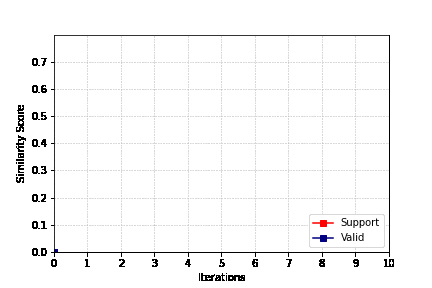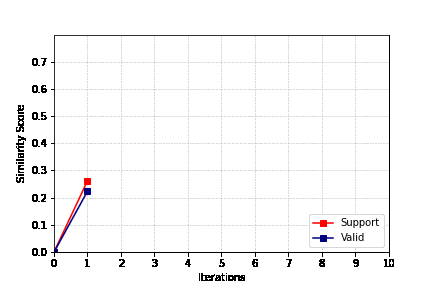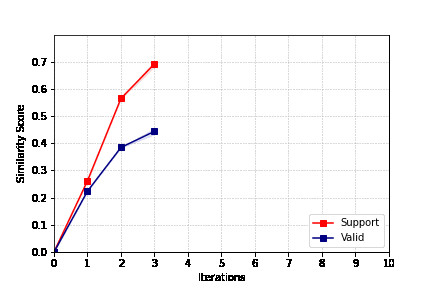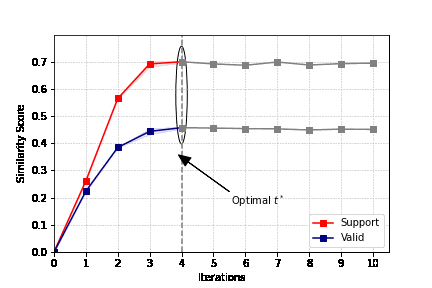
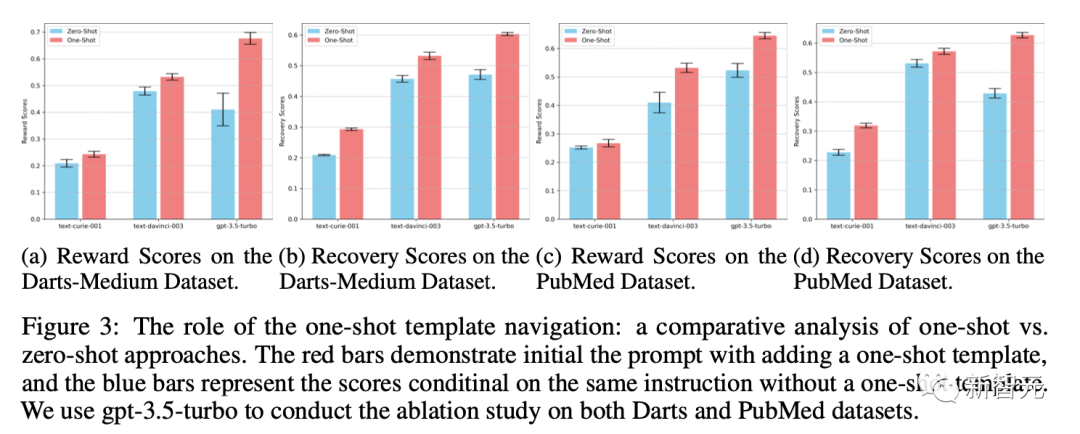
作者通过调整不同的预训练奖励模型来评估标注的质量,并引入不同的评价指标来间接评估摘要的还原能力。
作者在三个具有挑战性的数据集上进行了大量实验,并从各种角度进行了详细的消融研究。
结果表明,这种自我监督范式在奖励模型和还原数据能力的得分的评估中始终表现出很高的性能。
另外,作者应用该框架生成了两个新的数据集,对基于不同计算操作符的神经网络架构进行的描述。
作者通过调用OpenAI的API在各种类型的GPT模型上进行了基准测试。
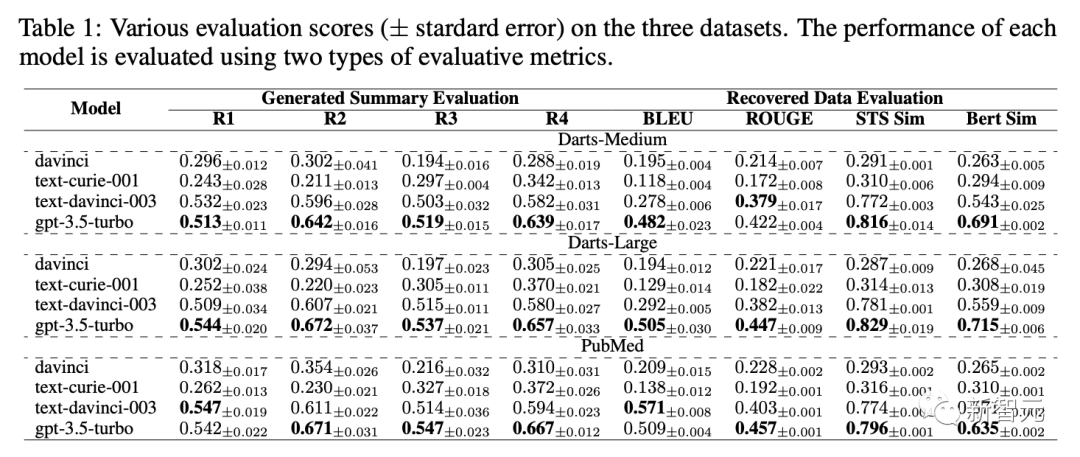
表1展示了davinci,text-curie-001,text-davinci-003,gpt-3.5-turbo在不同评估标准下标注数据质量的得分。


评论