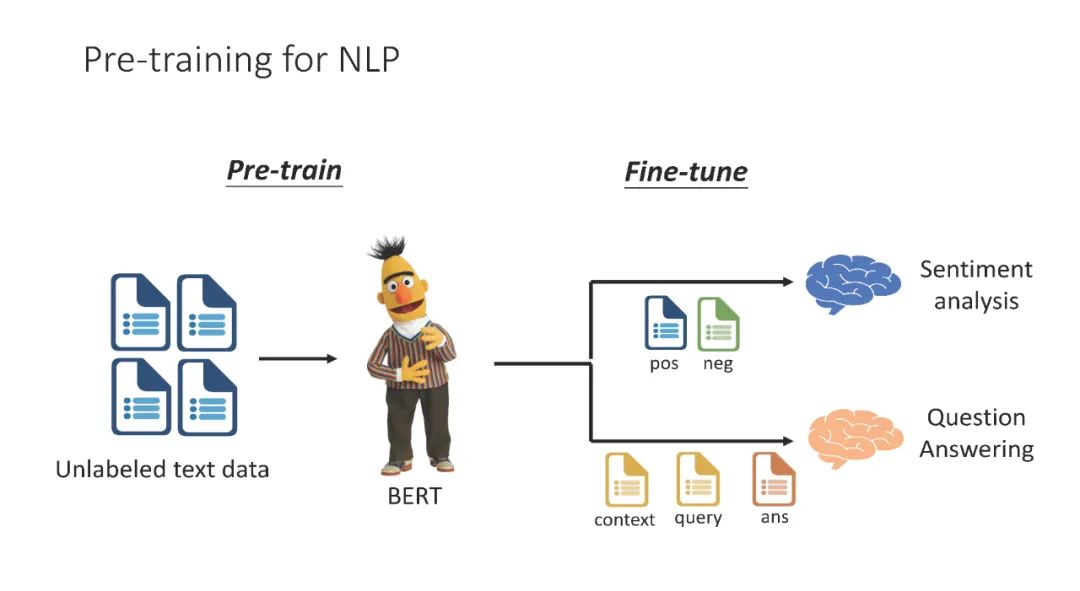
台大李宏毅老师最新AACL2022教程《预训练语言模型》教程,261页ppt机器学习算法与Python实战关注共 1535字,需浏览 4分钟 ·2022-12-22 15:25预训练语言模型(PLMs)是在大规模语料库上以自监督方式进行预训练的语言模型。在过去的几年中,这些PLM从根本上改变了自然语言处理社区。在本教程中,我们旨在从两个角度提供广泛而全面的介绍:为什么这些PLM有效,以及如何在NLP任务中使用它们。本教程的第一部分对PLM进行了一些有见地的分析,部分解释了PLM出色的下游性能。第二部分首先关注如何将对比学习应用于PLM,以改进由PLM提取的表示,然后说明如何在不同情况下将这些PLM应用于下游任务。这些情况包括在数据稀缺的情况下对PLM进行微调,以及使用具有参数效率的PLM。我们相信,不同背景的与会者会发现本教程内容丰富和有用。https://d223302.github.io/AACL2022-Pretrain-Language-Model-Tutorial/PDF和PPT下载 后台回复:李宏毅近年来,基于深度学习的自然语言处理(NLP)已经成为主流研究,比传统方法有了显著改进。在所有深度学习方法中,在感兴趣的下游任务上微调自监督预训练语言模型(PLM)已经成为NLP任务中的标准流程。自ELMo (Peters等人,2018年)和BERT (Devlin等人,2019年)于2018年提出以来,从PLM微调的模型在各种任务中占据了许多排行榜,包括问答、自然语言理解、自然语言推理、机器翻译和句子相似度。除了将PLM应用于各种下游任务之外,许多人一直在深入了解PLM的属性和特征,包括PLM表示中编码的语言知识,以及PLM在预训练期间获得的事实知识。有两个教程专注于自监督学习/ PLM:一个是NAACL 2019的教程(Ruder等人,2019),另一个是AACL 20201的教程。然而,考虑到该领域不断发展的性质,可以想象PLM的研究已经取得了重大进展。具体来说,与2019年PLM主要由科技巨头持有并用于科学研究相比,如今的PLM被具有不同硬件基础设施和数据量的用户更广泛地应用于各种现实场景中,从而提出了以前从未出现过的问题。已经取得了实质性的进展,包括对PLM的有效性和新的训练范式的可能答案,以使PLM更好地部署在更现实的环境中。因此,我们认为通过一个组织良好的教程将PLM的最新进展告知NLP社区是必要和及时的。本教程分为两个部分: 为什么PLM工作和PLM如何工作。表1总结了本教程将涉及的内容。本教程旨在促进NLP社区的研究人员对近年来PLM进展有一个更全面的看法,并将这些新出现的技术应用于他们感兴趣的领域。教程结构预训练语言模型是在大规模语料库上以自监督方式进行预训练的语言模型。传统的自监督预训练任务主要涉及恢复损坏的输入句子,或自回归语言建模。在对这些PLM进行预训练后,可以对下游任务进行微调。按照惯例,这些微调协议包括在PLM之上添加一个线性层,并在下游任务上训练整个模型,或将下游任务表述为句子补全任务,并以seq2seq的方式微调下游任务。在下游任务上对PLM进行微调通常会带来非凡的性能提升,这就是plm如此受欢迎的原因。在教程的第一部分(估计40分钟)中,我们将总结一些发现,这些发现部分解释了为什么PLM会导致出色的下游性能。其中一些结果帮助研究人员设计了更好的预训练和微调方法。在第二部分(估计2小时20分钟)中,我们将介绍如何预训练和微调PLM的最新进展;本部分中介绍的新技术已经被证明在实现卓越性能的同时,在硬件资源、训练数据和模型参数方面带来了显著的效率。推荐阅读全网最全速查表:Python 机器学习搭建完美的Python 机器学习开发环境训练集,验证集,测试集,交叉验证AI 绘画,StableDiffusion本地部署整理不易,点赞三连↓浏览 27点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 GNN教程:与众不同的预训练模型!Datawhale02021最新爬虫教程.ppt印象Python0开源下载 | 李宏毅深度学习301页PPT教程机器学习实验室0最新 Transformer 预训练模型综述!机器学习实验室0一文了解预训练语言模型!博文视点Broadview0《Datawhale李宏毅教程》成为榜一! Datawhale干货 作者:Datawhale开源团队《深度学习详解》荣登榜一!🎉仅发布三天,《深度学习详解》荣登榜一。特别感谢李宏毅教授对出版的支持,以及Datawhale 所有读者的认可。如何参与共学01 李宏毅深度学习 将放入AI夏令营《万字解读:预训练模型最新综述!Datawhale0鹏程·盘古α中文预训练语言模型鹏程·盘古α是业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古α和鹏程·盘古α增强版,并支持NPU和GPU两个版本,支持丰富的场景应用,在知识问答、知识检索、知识鹏程·盘古α中文预训练语言模型鹏程·盘古α是业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了两个版本:鹏程·盘古Chinese BERT中文预训练语言模型在自然语言处理领域中,预训练语言模型(Pre-trained Language Models)已成为点赞 评论 收藏 分享 手机扫一扫分享分享 举报