
一文读懂Spring 循环依赖,写得太好了!(建议收藏)
点击上方[全栈开发者社区]→右上角[...]→[设为星标⭐]

转自:Vt
链接:juejin.im/post/5e927e27f265da47c8012ed9
前言
正文
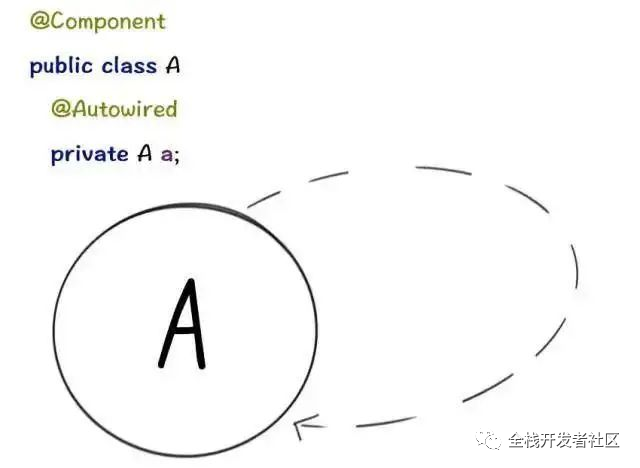
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}

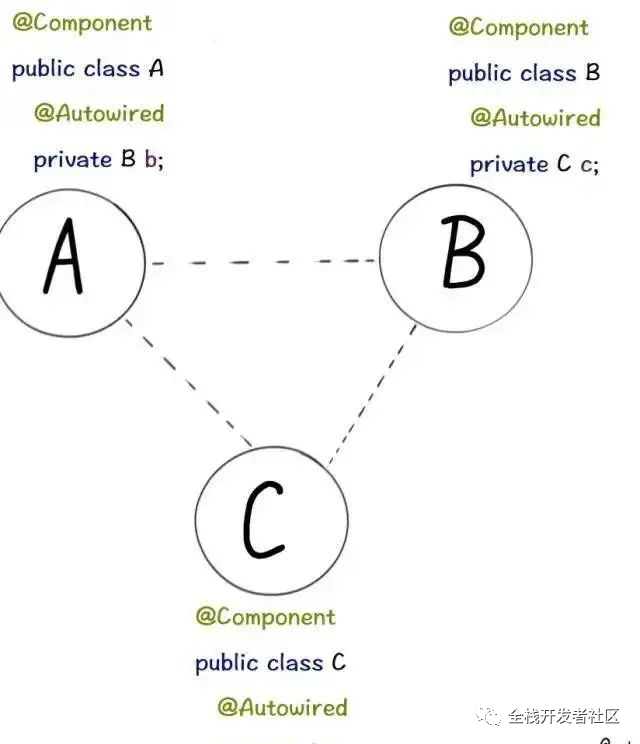
Spring解决循环依赖
singletonObjects 它是我们最熟悉的朋友,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。 singletonFactories 映射创建Bean的原始工厂 earlySingletonObjects 映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance.
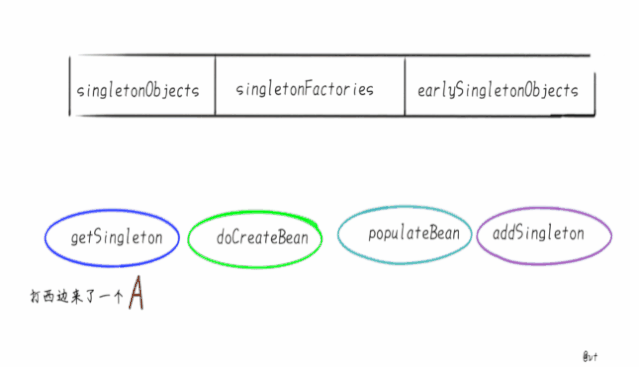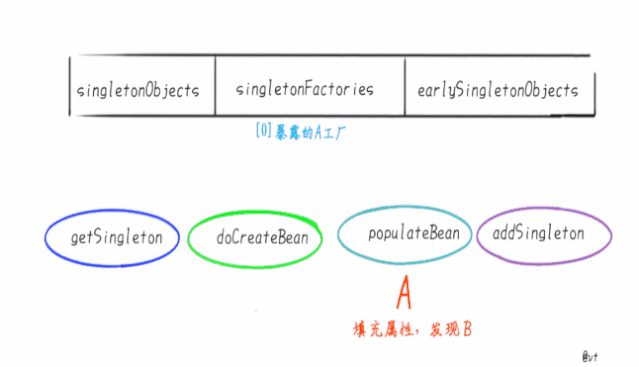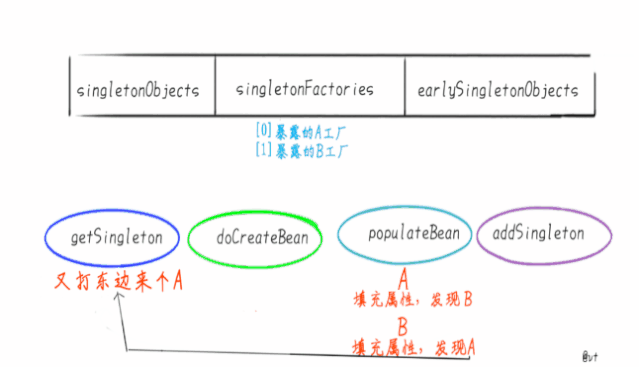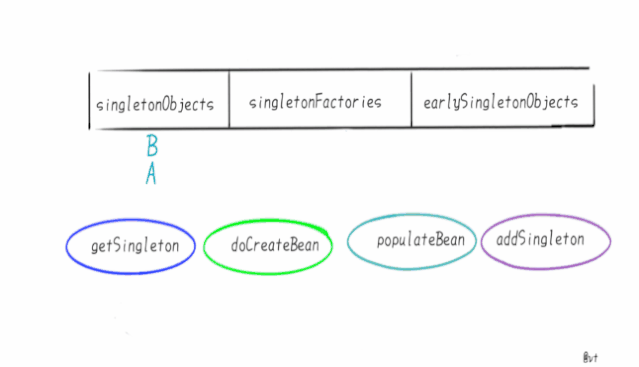
循环依赖的本质
将指定的一些类实例为单例 类中的字段也都实例为单例 支持循环依赖
public class A {
private B b;
}
// 类B:
public class B {
private A a;
}
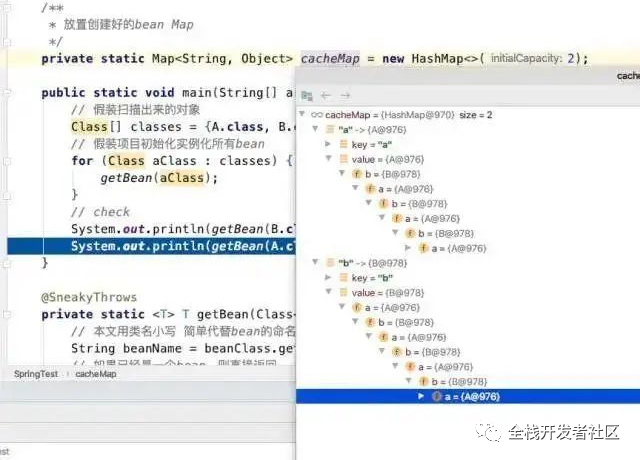
/**
* 放置创建好的bean Map
*/
private static Map cacheMap = new HashMap<>(2);
public static void main(String[] args) {
// 假装扫描出来的对象
Class[] classes = {A.class, B.class};
// 假装项目初始化实例化所有bean
for (Class aClass : classes) {
getBean(aClass);
}
// check
System.out.println(getBean(B.class).getA() == getBean(A.class));
System.out.println(getBean(A.class).getB() == getBean(B.class));
}
@SneakyThrows
private static T getBean(Class beanClass) {
// 本文用类名小写 简单代替bean的命名规则
String beanName = beanClass.getSimpleName().toLowerCase();
// 如果已经是一个bean,则直接返回
if (cacheMap.containsKey(beanName)) {
return (T) cacheMap.get(beanName);
}
// 将对象本身实例化
Object object = beanClass.getDeclaredConstructor().newInstance();
// 放入缓存
cacheMap.put(beanName, object);
// 把所有字段当成需要注入的bean,创建并注入到当前bean中
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
// 获取需要注入字段的class
Class fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// 如果需要注入的bean,已经在缓存Map中,那么把缓存Map中的值注入到该field即可
// 如果缓存没有 继续创建
field.set(object, cacheMap.containsKey(fieldBeanName)
? cacheMap.get(fieldBeanName) : getBean(fieldClass));
}
// 属性填充完成,返回
return (T) object;
}
what?问题的本质居然是two sum!
class Solution {
public int[] twoSum(int[] nums, int target) {
Map map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
}
结尾
觉得本文对你有帮助?请分享给更多人
关注「全栈开发者社区」加星标,提升全栈技能
本公众号会不定期给大家发福利,包括送书、学习资源等,敬请期待吧!
如果感觉推送内容不错,不妨右下角点个在看转发朋友圈或收藏,感谢支持。
好文章,留言、点赞、在看和分享一条龙吧❤️
评论