
利用Python多线程爬取王者荣耀高清壁纸
01
需求分析
url = "https://pvp.qq.com/web201605/wallpaper.shtml"
02
解析数据
response 复制到了json.cn网站数据是错误的 jsoncallback=Jquery的数据删掉 每一个Object就是一组图片 sProdImgNo_1 是封面小图 ()

03
编写代码
# 通过编号来获取不同规格的图片 必须把 200 --> 0
# 发现图片的url做了编码了 parse.unquote 进行了一个解码
def extract_images(data):
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0')
image_urls.append(image_url)
return image_urls
class Producer(threading.Thread):
def __init__(self,page_ueue,image_ueue,*args,**kwargs):
super(Producer,self).__init__(*args,**kwargs) # 初始化父类的init方法属性,父类也有__init__方法,如果不初始化,会报错.
self.page_ueue = page_ueue
self. image_ueue = image_ueue
def run(self) -> None:
while not self.page_ueue.empty():
page_url = self.page_ueue.get()
res = requests.get(page_url, headers=headers)
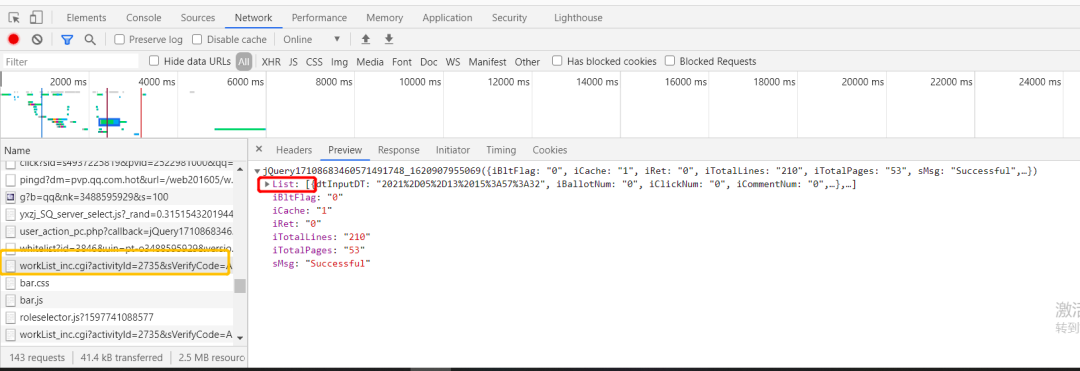
result = res.json() # response.json() 是requests第三方库提供的 是将json类型的数据转换成python字典的
方法
datas = result['List']
for data in datas:
# extract_images()定义的全局函数函数将图片url的200改成0,并且解码图片url(因为8张图片大小不一样,就是由这个字符串控制,因为看到图片url中有特殊字符%13%aab...)
image_urls = extract_images(data)
name = parse.unquote(data['sProdName'])
dirpath = os.path.join('image', name) # 动态的取添加路径 os.path.join()
if not os.path.exists(dirpath):
os.mkdir(dirpath)
# 把图片的url放到队列当中
for index,image_url in enumerate(image_urls): # 为图片命名 enumerate()来解决图片名字的问题 1.jpg 2.jpg 3.jpg
self.image_ueue.put({'image_url':image_url,'image_path':os.path.join(dirpath,'%d.jpg'%(index+1))})
class Comsumer(threading.Thread):
def __init__(self, image_ueue,*args,**kwargs):
super(Comsumer,self).__init__(*args,**kwargs)
self.image_ueue = image_ueue
def run(self) -> None:
while True:
try:
image_obj = self.image_ueue.get(timeout=10)
image_url = image_obj.get('image_url')
image_path = image_obj.get('image_path')
try:
request.urlretrieve(image_url,image_path)
print("%s下载成功!"%image_path)
except:
print('下载失败')
except:
break
# 创建了3个生产者线程 5个消费者线程 (因为消费者做的事情比较多 发起请求 保存图片)
def main():
# 创建页面url队列一
page_ueue = Queue(10)
# 创建图片url队列
image_ueue = Queue(3000)
for i in range(10): # 咱们就爬取10页
img_url = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&171003449092155893818_1620870158277&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1620870158575".format(i)
page_ueue.put(img_url)
# 创建3个生产者线程
for i in range(3):
pt = Producer(page_ueue,image_ueue)
pt.start()
# 创建5个消费者线程
for i in range(5):
ct = Comsumer(image_ueue)
ct.start()
04
程序运行
if __name__ == '__main__':
main()
加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
评论