
实际风控工作中的五大挑战!
共 8149字,需浏览 17分钟
·
2021-03-23 22:41
知乎 | https://zhuanlan.zhihu.com/p/158588024
前言
在上一篇文章中,我们用kaggle的数据集来做了一篇评分卡教程。
当然,实际风控中如果有这么简单,那我就得失业了。这一篇来讲讲实际风控产品化的路上,我们还会遇到哪些挑战,作为数据科学家(也有的公司叫算法工程师),我们是如何解决这些问题的。
虽然本文篇幅6000多字,依然未能详尽的讲述在实际风控产品中的挑战。那本文就当抛砖引玉吧。本文仅讲到“数据科学”部分的挑战,至于”数据工程“方面的挑战,例如建数据仓库,ETL,上云等等的这些,本文就先展示不讲了。也欢迎各位搞风控的大大在评论区讲讲你们在风控过程中遇到的挑战。文章有点长,如果在手机看到,可以先点赞收藏标记着,回头再读。
0.挑战在于算法之外
每次别人问我算法工程师的工作内容是什么,是不是天天写模型,调参数,我都喜欢发这个图过去。图来自论文Hidden Technical Debt in Machine Learning Systems
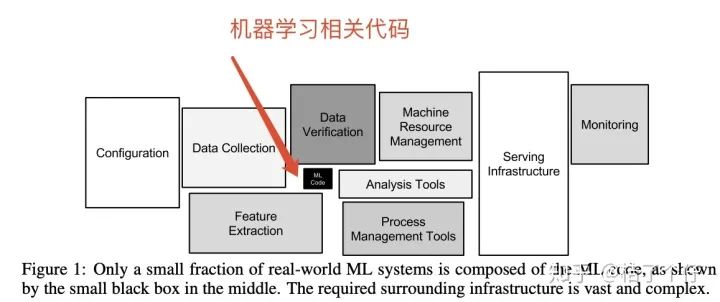
当然,这里面有一部分并不需要我来做,例如Serving Infrastruture,运维会帮我弄好。作为一个风控领域的数据科学家,说实话,写机器学习代码的时间占用我日常工作时间不到十分之一吧。我的工作需要面对算法之外的挑战。如果你是风控领域有一段时间工作经验的人,你一定会觉得我下面要说的内容已经熟悉了。如果你是小白,想面试风控算法岗位,那如果你能参透本文,理解这些挑战,并且讲给面试官听,他一定会对你刮目相看的。
1.定义目标变量(good/bad)
如果你不熟悉风控,你也许不会想到,虽然目标变量只有good和bad两种,但定义目标变量的过程竟然如此复杂,以至于这个问题我需要花一两千字来讲解。
在上一篇文章里用到的数据里,两年内逾期超过90天定义为bad,否则都为good。但你有没想过,这个目标是如何定出来的呢?虽然Kaggle的数据集和实际生产环境的不一样,但也不是随便给的。如果你认真观察,这个label的定义是由两个因素决定的:
逾期天数(超过90天) 观察期(两年内)
你也许会想,那么这两个数字是如何决定的呢?为啥还要这么麻烦,直接逾期第一天就去催收不行吗?在实际业务中,既要保证坏账最小化,也要保证催收的体验,你总不能人家到期第一天忘了还10块钱的账单就派人上门催收吧?客户都给你赶跑了。

1.1 逾期天数-迁徙率(Flow Rate)分析
在Reference[1]有个博主写的不错,但他的做法是先设置观察期,再看表现。而我的做法不一样,我的做法是只看每个月的的账户在下个月的表现。
我们这里先定义两个概念:
时间窗口。每个时间窗口由一个月和下一个月的数据构成。例如我拿一年的数据,例如2019年,就有11个观察窗口(1-2月,2-3月....11-12月)。
逾期期数。每个期数由30天组成(有的银行或者金融机构由自然月组成,会更加方便计算)。较多的金融机构会用Mn来形容逾期情况,例如
M0:当前未逾期 M1:逾期1-30日 M2:逾期31-60日 M3:逾期61-90日 M4:逾期91-120日 以此类推......
在下面的表里,纵坐标是前月的逾期期数情况(时间窗口左边界),横坐标是次月的逾期期数情况(时间窗口右边界)。里面的数字是怎么计算的呢?例如我们只有两个时间窗口。在时间窗口【1月-2月】里有50个客户保持未逾期,【2月-3月】有100个客户保持未逾期,那么坐标[1,1]的总数会是150。
假设经过分析2019年11个时间窗口后,我们得到以下一个统计表:
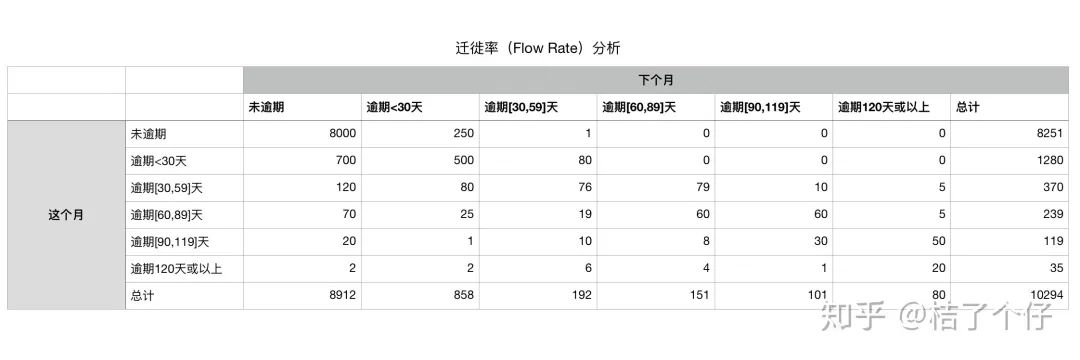
转换成百分比,并根据值的大小,用颜色标出来。
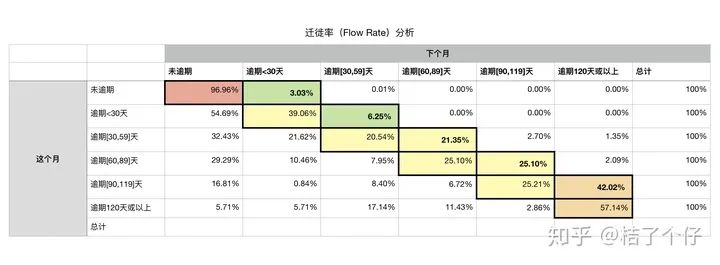
其中我们只关注黑色框框的部分,也就是彩色的部分。为什么呢?很简单,那些已经好转了的账户我们不管了,因为不是我们的催收对象,我们需要看的是逾期情况没有好转甚至恶化的客户。一个时间窗口内你的逾期情况最多往前一格(遇到天数为31天的有可能小概率逾期两格,但较少发生,统计时可忽略)。用直白的语言说,就是你现在逾期10天,给你一个月,你怎么也不可能逾期超过60天吧?
好,回到正题,迁徙情况百分比能说明什么呢?说明了某个逾期期数的风险情况。我们这里用“从良”这个不太恰当但好理解的词来形容账户逾期期数变少。例如在上表里,当逾期<30天时,54.69%的客户都会在下个月还上款(因为大概率是忘了还款日而不是没钱还);而这个月逾期在[90-119]天的有42.02%的客户的逾期期数会继续增加(确实手头缺钱还不上),25.21%的客户逾期期数会保持不变(手头紧,仅还得上一期的欠款以确保账户不会被清算)。也就说是,当逾期天数超过90天,客户“从良”的概率只有(100-25.21-42.02)% = 32.77%。也就说,很大概率这个客户的情况会一直恶化下去,所以我们需要在他恶化前,就挑出来催收,以减少损失。
至于“从良”的百分比低于多少就不能接受,则需要和商业部门沟通。但从良的少于1/3确实挺少了。
不过这里需要澄清下,这里并不是指逾期真的超过90天才催收,而是说,我预测这个人将来会逾期超过90天,所以我在他达到那个逾期时间前就去催收,避免严重逾期的发生。
1.2 观察期分析 ——elbow method(手肘法则)
刚才我们通过分析,确定了目标里的逾期天数是90天以上。那么目标里的观察期是如何做的呢?
一个客户开始逾期后(超过一天),要达到90天以上的逾期少则需要3个月,多则可以无限多个月。如果观察期短了,我们会漏抓了很多客户,如果观察期太长,例如无限长,你确实能抓住100%的逾期在90天以上客户,但观察期太长了,逾期的客户一直没人理就会一直恶化。所以一个合理的观察期很重要。
为了找到一个合理的观察期,我们需要分析逾期月数与逾期客户总数的情况,例如再某个银行,通过分析,我得到一个逾期月数与逾期客户数的情况表:

可以看到,逾期90天以上的客户,95%的都发生在6个月内。但你也许会说,9个月能检测到97%,不是更好吗?但记得经济学里的“边际效用”这个词吗?意思是再增加投入,新增的产出会变少。用一个知乎上热门的词语来形容,就是“内卷”。我们分析时也是。再追加一个月观察期,对效用的提升不明显,反而引入更多风险。当“内卷”发生时,就不再增加观察期了。
所以我的经验是用elbow method,也就是寻找曲线的“转折点”,就像手肘一样。(如果你熟悉k-means,那么你可能记得,在k-means里,我们决定怎么选择k值的一个算法是elbow method。这里就不展开讲k-means了,如果真的不熟悉,也不影响本文阅读)
把上表plot出来,得到下面一个图,其中转折点(或者说‘手肘)用红圈划出来了:
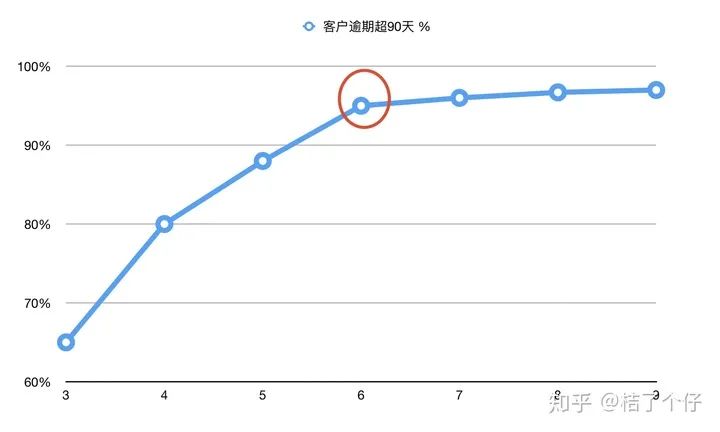
可以看到,但观察期为6个月时,我们能抓到的逾期客户已经很多了。再加一个月,能抓到的增量也很少了,边际效用明显降低了很多。所以我们就可以把观察期设置为6个月。
对于普通的信贷产品,一般情况下这个转折点还是很好观察到的。但看到这里你也许想问,如果没有明显的转折点(elbow),该怎么抉择呢?这就复杂了。但如果你的信贷产品真的找不到一个明显的elbow point,你画出来的曲线比上面的曲线平滑得多,怎么办呢?
这确实是一个难题,且没有一个标准的答案。但你可以和商业部分探讨下面几个问题:
当逾期超过90天的客户比例是多少时,我们的资产会出现亏损?然后你可以以这个比例作为嘈参照,选择响应的观察期。 逾期90天是不是一个好的选择?能不收紧标准,把逾期天数检测缩短到60天,这样做对客户体验造成什么影响?
2.特征构建方式
不像kaggle比赛里那么简单,在实际业务中,很多时候特征是需要自己构建和挖掘的。构建特征的思想有几点:
RFM-V框架
哈哈哈,别去google这个词,这是我编的名词,纯粹是为了让大家方便记忆哈哈哈,是我从RFM模型上得到的启发。RFM模型在的客户关系管理(CRM)的分析中常常用到。RFM其实不是一个模型,只是常用的构建特征思想。
RFM分别代表:
最近情况 (Recency):近期的情况对风险影响大于远期的。 频率 (Frequency):使用频率,联系频率。 金额 (Monetary):刷卡金额,贷款金额。
不难理解上面三种情况都和客户风险有直接关系吧?而V代表Velocity,既速度。例如我过去1个月刷卡次数为10次,而过去六个月平均每个月刷卡次数5次,那么这个Velocity = 10/5=2。当速度大于1时,表示某个特征的值在加速增加,小于1时,表示速度在减少。
V和R类似,但又不同,V是近期情况和远期情况的比较,R仅为近期情况。
V还可以跟F,M自由组合。例如V和F的组合可以得到例如“最近刷卡频率增加,风险有可能上升”的信息,V月M的组合可以得到例如“最近消费激增,可能风险上升”的信息。
WOE变换
这个技巧在上一篇里面也用过了。本质就是把非线性的特征转换成线性的特征, 这对于逻辑回归等泛线性模型是非常必要的。
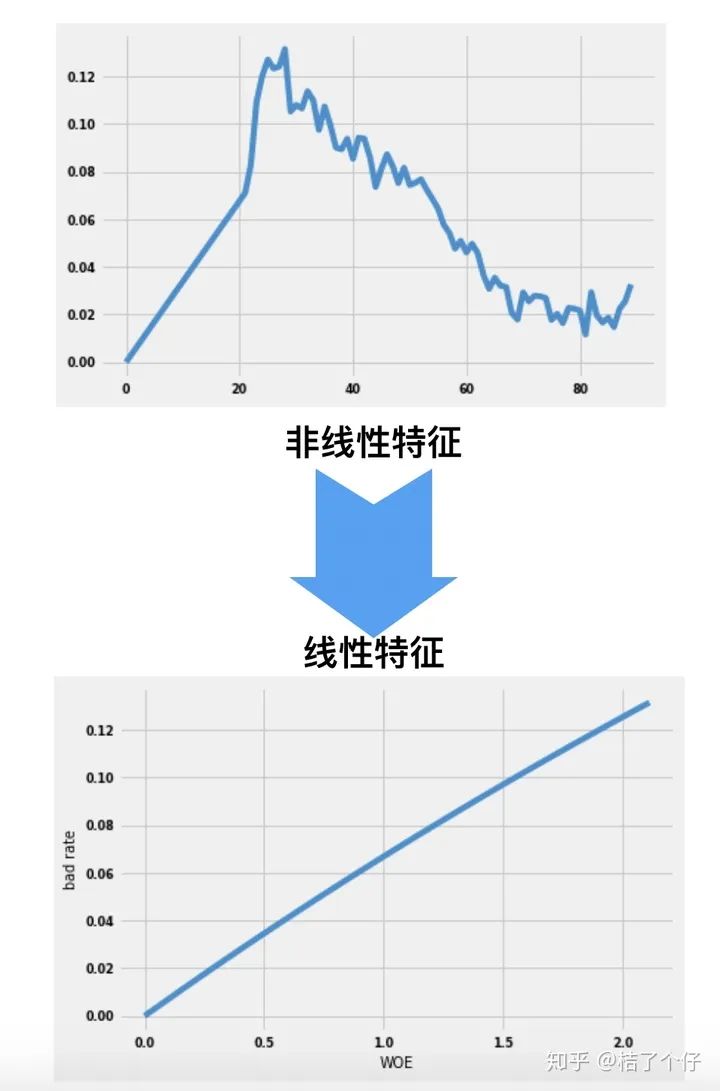
具体变换过程这里就不再赘述了。如果对WOE不熟悉的朋友可以看看我之前的文章。上面那张图就是我那篇文章的里的。文章链接[桔了个仔:WOE编码为啥有效(https://zhuanlan.zhihu.com/p/146476834)
Vintage分析
除此之外,Vintage分析也是帮助构建特征的方法。本来想自己写一篇的,但Reference[1]里的兄弟写得太好了,我就不再写多一遍了,可以点开看他文章的part2.
3.稳健性
这里就和机器学习模型有点关系了,也就是我在文章前面说到的“用时不到10%"的部分。虽然耗时少,但对于模型的效用来说,确实至关重要。
3.0 增强稳健性的通用方法
首先讲讲通用的增强稳健性的方法。即使你是做其他领域的数据科学或者深度学习,也会有所接触。
加扰动。就像训练CNN识别图片时,我们会做”数据增强“,也就是选择、拉伸、增加白噪声等方法增加数据,在风控里,我们也可以对训练数据进行”数据增强“。但我的做法比较保守,刚好由于数据一般都是标签不平衡的(一般5%左右的bad rate),我只SMOTE方法来对bad的部分进行upsample。SMOTE方法通过对bad的部分加扰动,产生新的数据,这样就能平衡训练集中的各标签比例。 使用统计特征。举个例子,例如逾期5000块在2000年是很严重的逾期,意味着高风险,但在2020年,这是低风险的。如果只用金额,那么模型的预测会失效。我们可以用统计特征来代表实际值。例如使用Z-Score,z的绝对值值越高,代表他和其他客户的差异越大。
风控领域由于对解释性有一定要求,所以很难使用神经网络等复杂模型或者深度学习模型。一般来说,是泛线性模型(例如逻辑回归)和基于树的模型(Decision Tree, RandomForest, XGBoost)等。对这里两种模型,也有不同的增强模型稳定性的方法。
3.1 对于泛线性模型(例如逻辑回归)
对于逻辑回归模型,单个变量的变动会影响模型的输出,而且这种影响是线性的。这会造成两个因素影响稳定性:
例如我的模型其中一个特征是逾期金额,逾期十块和逾期二十块对于银行来说都是小事,但在模型的某一项里,影响是双倍的。 对outlier值处理复杂
解决方法:
为了模型的稳定性,我们可以对某些连续变量进行分箱,使其变成离散变量。这也是前面WOE的思想之一。这时候小于100块的都分到一个组,那么你欠银行一块钱和99块钱都是一样低风险。 分箱后,outlier会自动转换成变成分箱的最左或者最右的那一类。例如我们的客户里年龄最大的不到100岁,那么我们可以每十岁设置一个分箱,那么可以有[-∞,10],[11,20],....[90,+∞]等十个分箱。这时候有个客户不小心年龄20岁输成200岁,那么这么年龄也不会无法处理。
3.2 基于树的模型
由于树的split是基于阈值的,使用基于树的好处就是相当于模型给你自动分了箱。对于决策树,数据的准备往往是简单的甚至是不必要的。数的另一个好处是对波动不敏感。数据分布发生微小偏移时,仍能表现稳定。
但使用单棵决策树容易过拟合。为了防止过拟合我们一般会:
修剪枝叶。但是需要大量的分析与尝试,所以我极少使用单科决策树作为模型。我一般用下一种方法。 使用RandomForest。RandomForest是用训练数据随机的计算出许多决策树,形成了一个森林。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。随机森林在解决回归问题时,并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续的输出。但在训练数据足够大的情况下,由于
除此之外,我还会用到XGBoost。XGBoost也是基于树的模型,所以决策树在稳健性方面的好处它也有。XGBoost具有非常好的非线性拟合能力,以及对超参数的鲁棒性,因此在Kaggle比赛中大家都在疯狂用。但依赖统计特征,特征的准备需要积累一定周期才有足够置信度,不过在信贷风控场景下,我的项目都有超过一年的数据,使用效果还是很好的。
但无论如何,稳定性无论做得多好,模型总有效用递减的时候。关于如何监控模型,第六章会讲。
4.评价指标
模型来说,大家都用AUC。对于二元分类,这个方法是很常用的。但是对于不平衡数据且bad rate会有变化的数据,AUC的效果容易失真,所以仅仅看AUC,对模型的性能理解是失真的。除了模型性能,还有其他指标也是需要参考的
KS(Kolmogorov-Smirnov)值
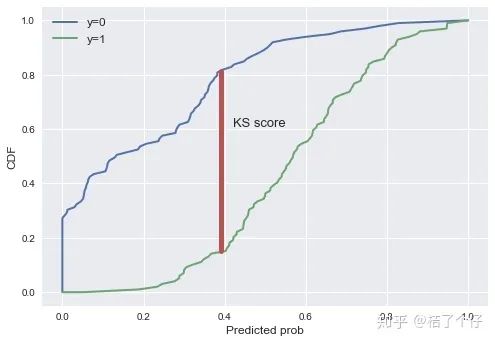
KS值评估模型的区分度(discrimination)是在模型中用于区分预测正负样本分隔程度的评价指标。KS的计算方法直观解释例如下图,绿色为预期bad rate累积函数(因为是累积的,所以最高点为1),蓝色为good rate的累积函数。他们之间最大的差值为KS值。用公式来讲,就是KS=max(TPR-FPR),也就是召回率-误诊率的最大值。
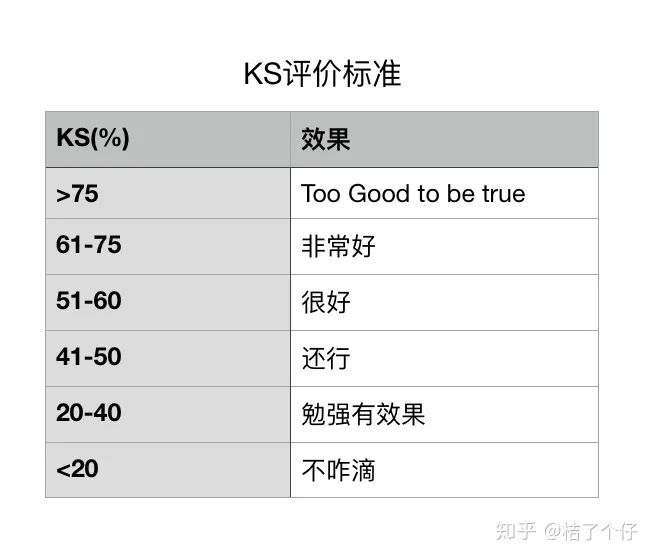
那么KS怎么看呢?怎么知道模型的区别能力好不好呢?这里有个标准,仅供参考,实际应用时可以稍微改改,但一般来说KS越大越好。
效用提升(LIFT)
效用提升的计算等于模型捕捉到的bad rate 除以随机捕捉到的bad rate。例如下表,按照预测的风险排序分成1-5箱,其中1位最高风险,5为最低风险。如果随机把客户分成5箱,那么每箱里面的bad rate应该都是5%。但是通过模型来预测,我第一箱抓到的bad客户应该是最多的。例如我看第一箱的LIFT,计算方法为模型抓到的12.5%的bad,那么效用提升就是250%。也就是说,你之前要催收125个客户才能达到的回款效果,通过我的模型,现在只需要催收50个,节省了你60%的催收成本。

你可以把第一箱定位高风险,也可以把第一二箱都看为高风险。当你通过这个新的策略,催收前两箱,也就是40%的客户时,你能抓到(25+10)=35个坏客户,也就是70%的坏客户,那么LIFT就是70/40=175%。
当LIFT=100%时,说明模型没啥用,等于瞎猜。
群体稳定性指标(Population Stability Index,PSI)
PSI是评价样本稳定性的指标,不仅可以评价样本的总体稳定性,也可以评价某个特征的稳定性。需要注意的是,PSI并不是直接评价模型性能的指标。
PSI的计算很简单,公式为:
PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )。
Reference[6]里的文章很好的解释了PSI的概念与计算,还有代码实现,我这里就不再赘述了。
在产品运行过程中,如果看到模型的AUC下降了,但你又发现PSI上升了,说明你需要用新的数据集来训练新的模型了。
5.解释性
由于银行监管要求,风控模型需要满足解释性要求才能批准上线使用(不知道互联网金融公司有没这个要求),所以模型不是能预测就行的,我们需要对两个方面进行解释:
特征层面
做特征组合时,你需要让特征有意义。假如你通过各种组合,发明了一个特征,发现用他的月收入除以他家房子的面积数,得到的特征与风险有较强关联,那也是不可用的。月收入金额除以房子的面积数这种组合是不好理解的。但如果你真的发现这种奇怪的组合特征很有用,你需要换个思路,用有意义的特征再进行组合。例如刚才发现月收入除以他家房子的面积数这个特征很有用,那么你可以想想。他家房子的面积数和什么相关联?是不是房贷金额?那么我们可以重新组织一下,组合出一个有意义的特征:DTI(debt to income),定义是负债除以收入。事实上客户的DTI指数也是很常用的特征。
模型决策层面
如果你用逻辑回归和单棵决策树,那么模型就具有自解释性。
对于随机森林和XGBoost,解释起来稍微麻烦点。如果想强行解释随机森林,那么会有点麻烦,可能需要UI的帮助。例如你随机森林用了100课数,那么你要把这100课数的预测结果先展示一次,然后再把这些结果得到最后结果的计算过程又展示一次。比起深度模型那种黑箱子,XGBoost和RandomForest的工作原理确实能讲出来,但那复杂度别人能懂吗?
所以我们需要直观的解释,虽然理解没那么完全,但难度大大降低。一般会用两种方法:
当然解释性并不是那么简单,这是个大课题,更多相关的技巧可以参考Reference[2-5]
6.上线,监控,模型更新
这一点的经验未必和其他风控算法工程师一样。知乎上也有很大风控大牛,他们要么在互联网金融做风控,要么在支付系统做风控,而像我这种在创业公司给银行做风控的人应该不多。
上线
如果你开发的这套风控系统是第一套,那么直接上线就完事了。但在商业应用中,直接切换风控系统是高风险的事情。例如你是技术提供商,银行觉得你开发的风控系统不错,但他也不会马上用你的。一般来说,银行需要先把一部分(例如20%)的账户分到你的系统来评分,剩余80%还是用原来的系统来评分。持续在线上观察半年,确定你的系统效果要更好,才会逐渐增加更多比例让你的系统评分。
监控
模型上线后,需要持续观测第四节里提到的评价指标,包括特征稳定性,效用,模型AUC等。根据实际情况可以定义。监控周期一般是每个月一次。
模型更新
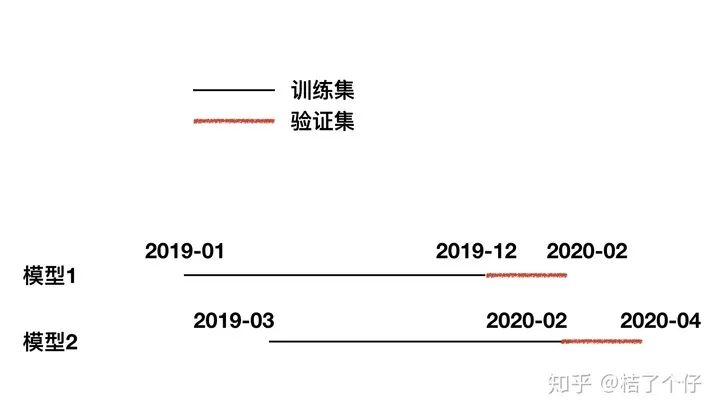
基于阈值更新。例如当AUC低于0.75,或者KS低于40时。 基于时间间隔更新。例如下图这样,每两个月刷新一次模型,假设原模型是1,新模型是2,那么选择表现较好的那个作为接下来两个月呆在线上的那个模型。
总结
可以看到,算法虽然是核心,但是仅有核心是不够的,一个完整的风控系统,即使除开软件工程部分,还是有很多的工作需要做,很多的分析需要搞。我们常说的人工智能AI,主要指机器智能,但要支持一个平稳的风控系统,需要的是真正的“人工”智能,也就是人本身的智能,机器智能在这里,也就是辅助。