
网易云音乐基于 Flink + Kafka 的实时数仓建设实践
背景
Flink + Kafka 平台化设计
Kafka 在实时数仓中的应用
问题 & 改进
一、背景介绍
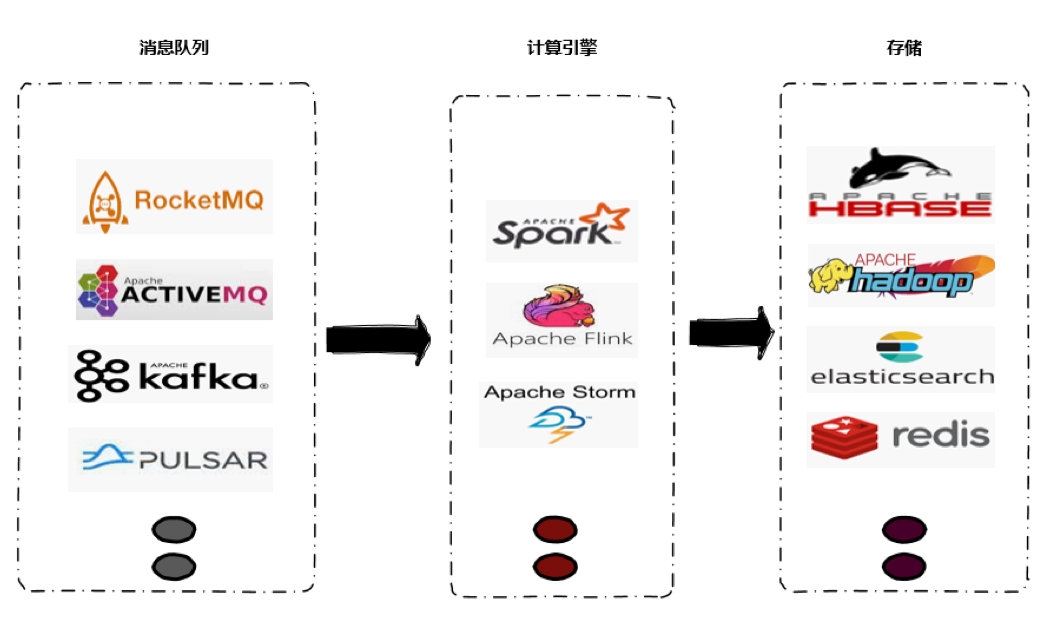
高吞吐,低延迟:每秒几十万 QPS 且毫秒级延迟;
高并发:支持数千客户端同时读写;
容错性,可高性:支持数据备份,允许节点丢失;
可扩展性:支持热扩展,不会影响当前线上业务。
高吞吐,低延迟,高性能;
高度灵活的流式窗口;
状态计算的 Exactly-once 语义;
轻量级的容错机制;
支持 EventTime 及乱序事件;
流批统一引擎。
二、Flink+Kafka 平台化设计
集群 catalog 化;
Topic 流表化;
Message Schema 化。

三、Kafka 在实时数仓中的应用
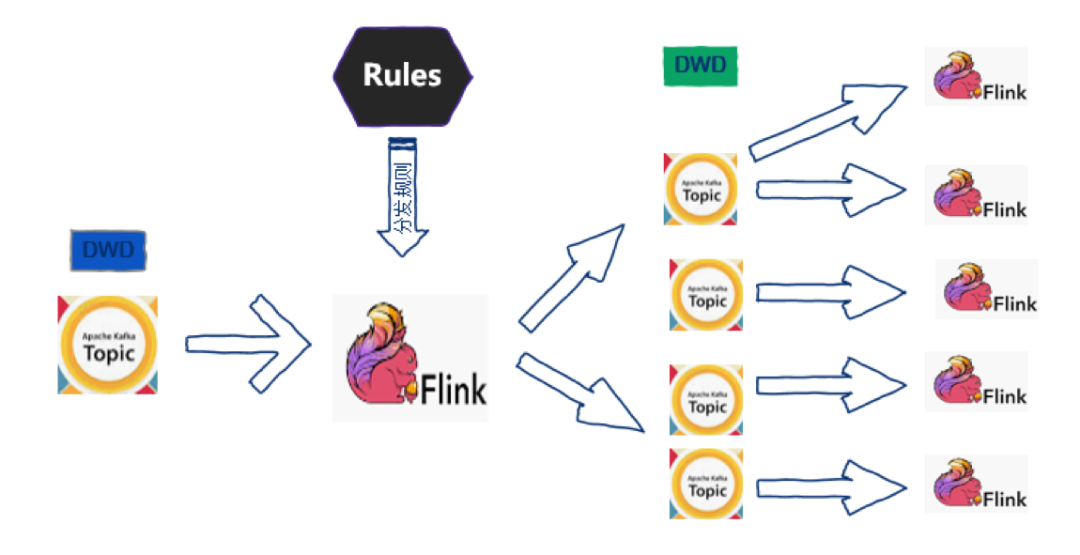
虽然进行了集群的扩展,但是任务量也在增加,Kafka 集群压力仍然不断上升;
集群压力上升有时候出现 I/O 相关问题,消费任务之间容易相互影响;
用户消费不同的 Topic 过程没有中间数据的落地,容易造成重复消费;
任务迁移 Kafka 困难。
如何感知 Kafka 集群状态?
如何快速分析 Job 消费异常?
集群概况的监控:可以看到不同集群对应的 Topic 数量以及运行任务数量,以及每个 Topic 消费任务数据量、数据流入量、流入总量和平均每条数据大小;
指标监控:可以看到 Flink 任务以及对应的 Topic、GroupID、所属集群、启动时间、输入带宽、InTPS、OutTPS、消费延迟以及 Lag 情况。
四、问题&改进
多 Sink 下 Kafka Source 重复消费问题;
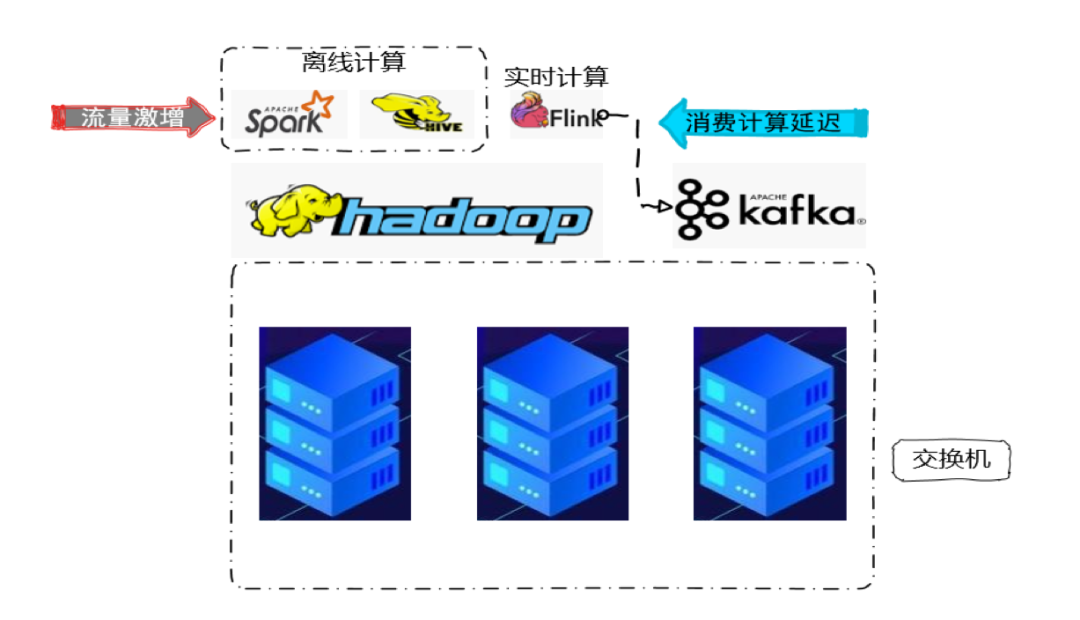
同交换机流量激增消费计算延迟问题。
五、Q & A
评论