
Iceberg 实战 | Flink + Iceberg,百亿级实时数据入湖实战
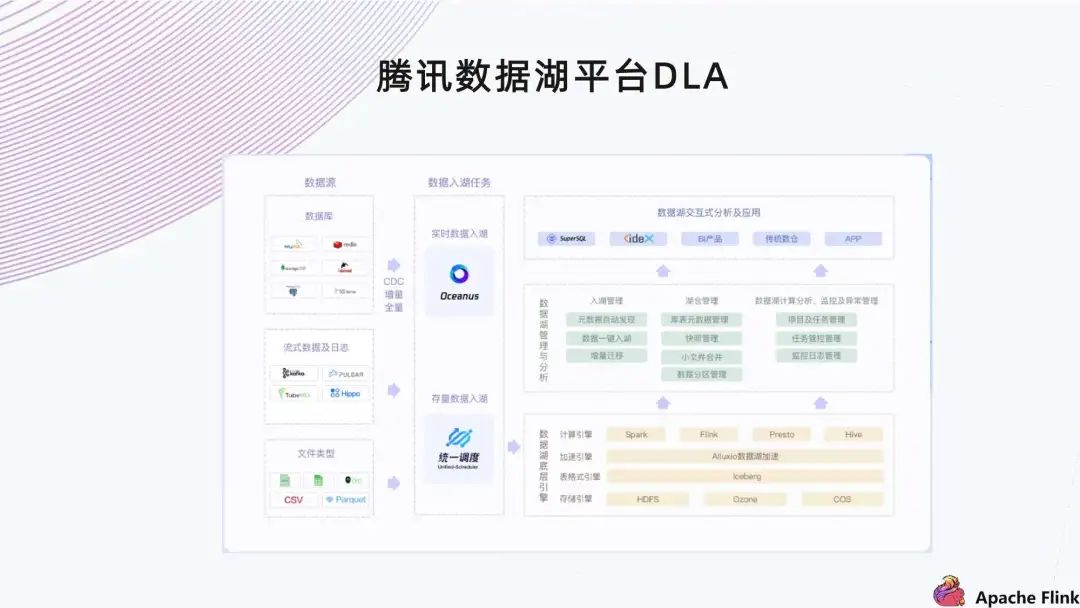
腾讯数据湖介绍
百亿级数据场景落地
未来规划
总结
 GitHub 地址
GitHub 地址 一、腾讯数据湖介绍
二、百亿级数据落地场景落地
1. 传统平台架构
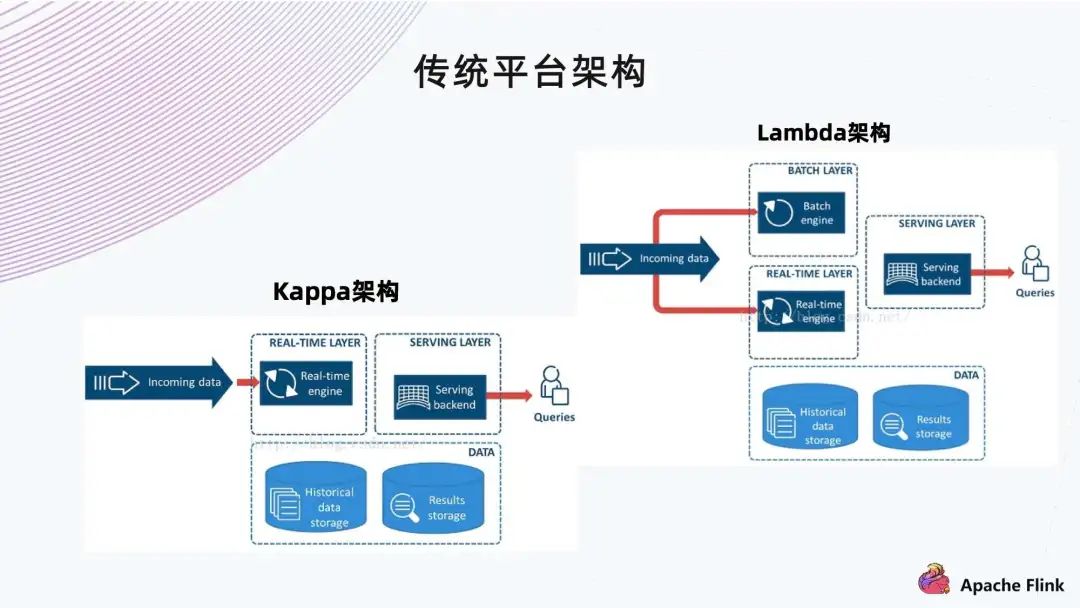
Lambda 架构中,批和流是分开的,所以运维要有两套集群,一套是 For Spark/Hive,一套是 For Flink。这存在几个问题:
第一是运维的成本比较大; 第二是开发成本。例如在业务方面,一会要写 Spark,一会要写 Flink 或者 SQL,总体来说,开发成本对数据分析人员不是特别友好。 第二个是 Kappa 架构。其实就是消息队列,到底层的传输,再到后面去做一些分析。它的特点是比较快,基于 Kafka 有一定的实时性。
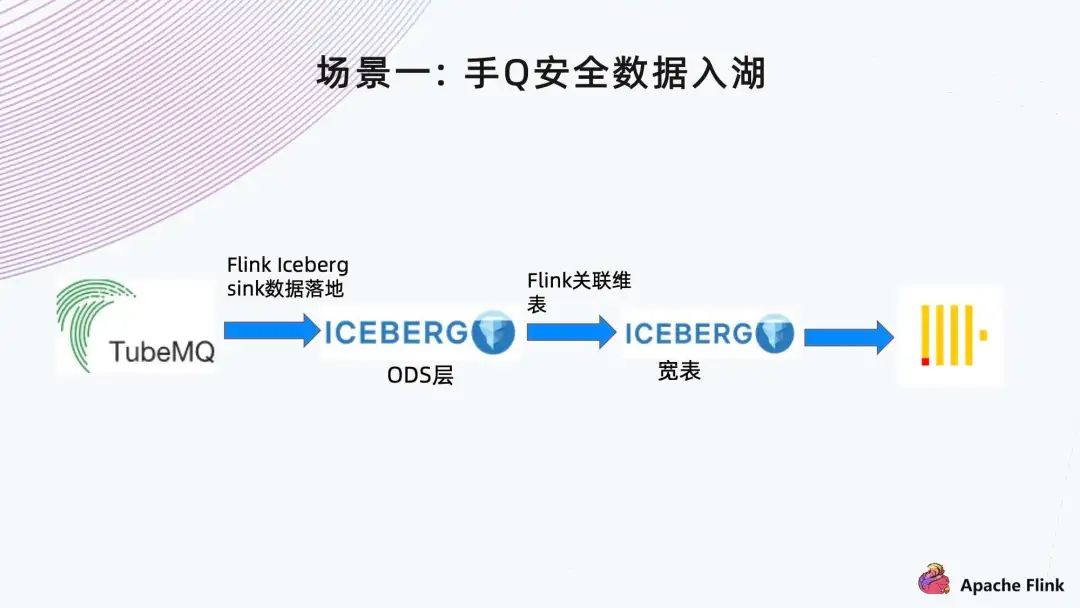
2. 场景一: 手 Q 安全数据入湖
■ 小文件挑战
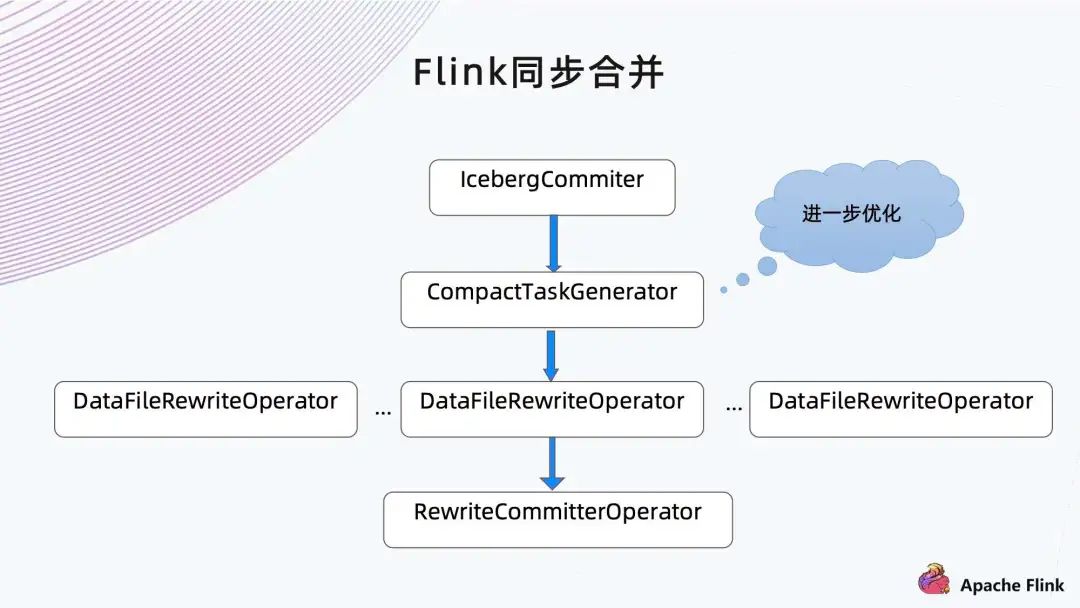
3、小文件爆炸
■ 解决方案
增加小文件合并 Operators;
增加 Snapshot 自动清理机制。
增加后台服务进行小文件合并和孤儿文件删除;
增加小文件过滤逻辑,逐步删除小文件;
增加按分区合并逻辑,避免一次生成太多删除文件导致任务 OOM。
■ Fanout Writer 的坑
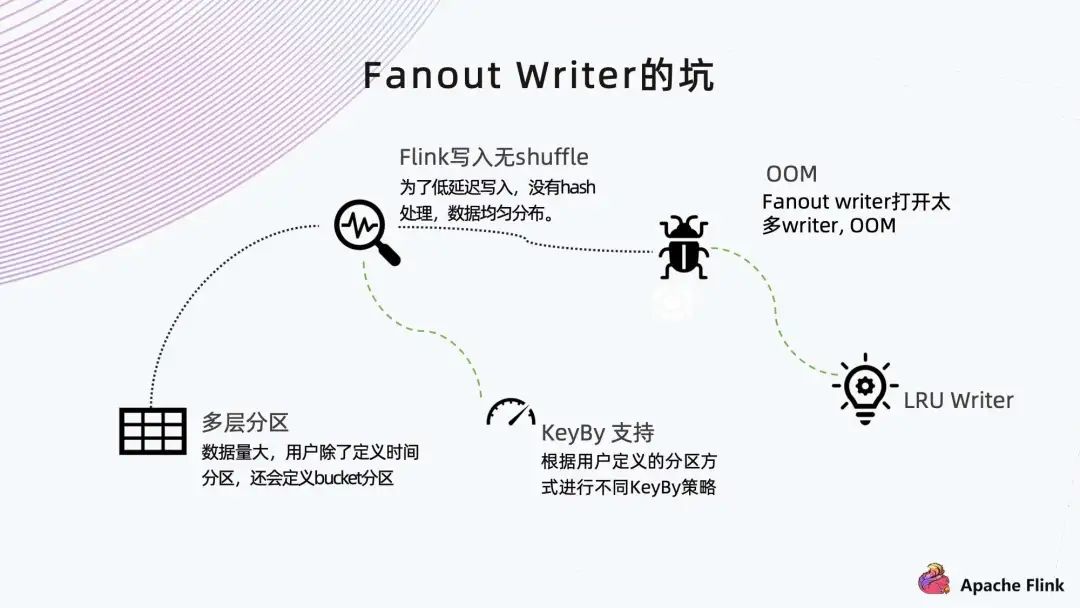
在 Fanout Writer 时,如果数据量大可能会遇到多层分区。比如手 Q 的数据分省、分市;但分完之后还是很大,于是又分 bucket。此时每个 Task Manager 里可能分到很多分区,每个分区打开一个 Writer,Writer 就会非常的多,造成内存不足。
这里我们做了两件事情:
第一是 KeyBy 支持。根据用户设置的分区做 KeyBy 的动作,然后把相同分区的聚集在一个 Task Manager 中,这样它就不会打开那么多分区的 Writer。当然,这样的做法会带来一些性能上的损失。
第二是做 LRU Writer,在内存里面维持一个 Map。
3. 场景二:新闻平台索引分析
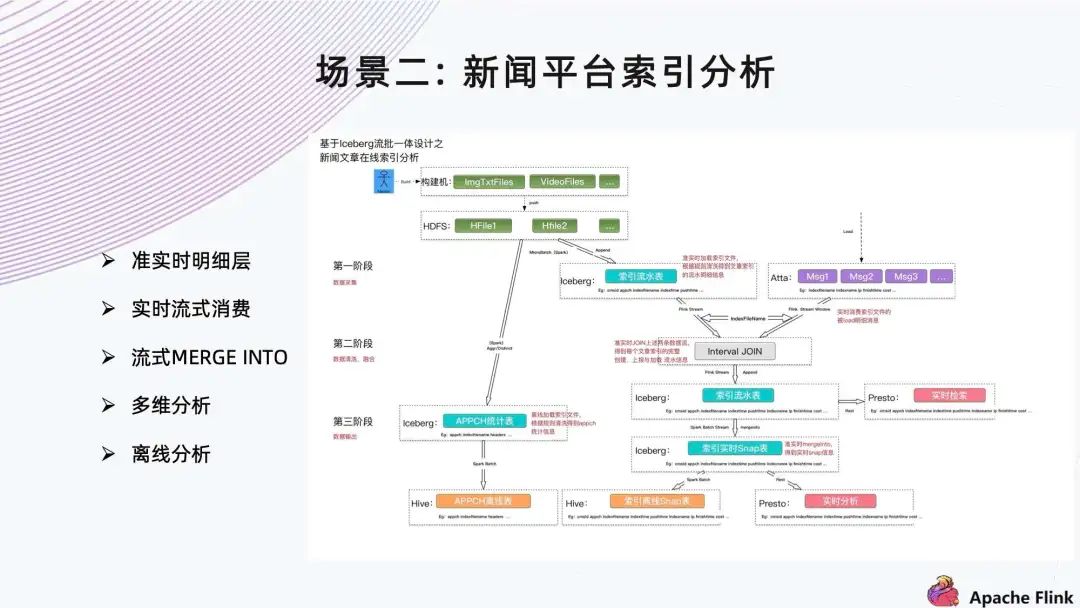
上方是基于 Iceberg 流批一体的新闻文章在线索引架构。左边是 Spark 采集 HDFS 上面的维表,右边是接入系统,采集以后会用 Flink 和维表做一个基于 Window 的 Join,然后写到索引流水表中。
■ 功能
准实时明细层;
实时流式消费;
流式 MERGE INTO;
多维分析;
离线分析。
■ 场景特点
上述场景有以下几个特点:
数量级:索引单表超千亿,单 batch 2000 万,日均千亿;
时延需求:端到端数据可见性分钟级;
数据源:全量、准实时增量、消息流;
消费方式:流式消费、批加载、点查、行更新、多维分析。
■ 挑战:MERGE INTO
有用户提出了 Merge Into 的需求,因此我们从三个方面进行了思考:
功能:将每个 batch join 后的流水表 Merge into 到实时索引表,供下游使用;
性能:下游对索引时效性要求高,需要考虑 merge into 能追上上游的 batch 消费窗口;
易用性:Table API?还是 Action API?又或是 SQL API?
■ 解决方案
第一步
参考 Delta Lake 设计 JoinRowProcessor;
利用 Iceberg 的 WAP 机制写临时快照。
第二步
可选择跳过 Cardinality-check;
写入时可以选择只 hash,不排序。
第三步
支持 DataframeAPI;
Spark 2.4 支持 SQL;
Spark 3.0 使用社区版本。
4. 场景三:广告数据分析
■ 广告数据主要有以下几个特点:
数量级:日均千亿 PB 数据,单条 2K;
数据源:SparkStreaming 增量入湖;
数据特点:标签不停增加,schema 不停变换;
使用方式:交互式查询分析。
■ 遇到的挑战与对应的解决方案:
挑战一:Schema 嵌套复杂,平铺后近万列,一写就 OOM。
解决方案:默认每个 Parquet Page Size 设置为 1M,需要根据 Executor 内存进行 Page Size 设置。
挑战二:30 天数据基本集群撑爆。
解决方案:提供 Action 进行生命周期管理,文档区分生命周期和数据生命周期。
挑战三:交互式查询。
解决方案:
三、未来规划
对于未来的规划主要分为内核侧与平台侧。
1. 内核侧
在未来,我们希望在内核侧有以下几点规划:
■ 更多的数据接入
增量入湖支持;
V2 Format 支持;
Row Identity 支持。
索引支持;
Alloxio 加速层支持;
MOR 优化。
数据治理 Action;
SQL Extension 支持;
更好的元数据管理。
2、平台侧
在平台侧我们有以下几点规划:
元数据清理服务化;
数据治理服务化。
Spark 消费 CDC 入湖;
Flink 消费 CDC 入湖。
写入数据指标;
小文件监控和告警。
四、总结
可用性:通过多个业务线的实战,确认 Iceberg 经得起日均百亿,甚至千亿的考验。
易用性:使用门槛比较高,需要做更多的工作才能让用户使用起来。
场景支持:目前支持的入湖场景 还没有 Hudi 多,增量读取这块也比较缺失,需要大家努力补齐。
另外~《Apache Flink-实时计算正当时》电子书重磅发布,本书将助您轻松 Get Apache Flink 1.13 版本最新特征,同时还包含知名厂商多场景 Flink 实战经验,学用一体,干货多多!快扫描下方二维码获取吧~
(本次为抢鲜版,正式版将于 7 月初上线)

更多 Flink 相关技术交流,可扫码加入社区钉钉大群~
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
 戳我,立即报名!
戳我,立即报名!