
风格化神经网络画家!不同风格的绘画它都可以搞定!
共 2290字,需浏览 5分钟
·
2020-11-30 13:39
创作艺术绘画是人类和其他智慧物种的决定性特征之一。近年来,我们可以看到了图像翻译或风格转换的生成模型取得了巨大进步,使用的方法主要利用神经网络作为生成工具,将平移公式化为像素映射或像素空间中的连续优化过程。
然而,作为一个艺术创作过程,绘画通常是一个连续的实例化过程,使用画笔进行创作,从抽象到具体,从宏观到细节。这个过程从根本上不同于神经网络的创建过程。
要完全掌握专业的绘画技巧,人们通常需要大量的练习和学习领域专业知识。即使对于一个有多年实践经验的熟练画家来说,创作一幅写实的绘画作品仍然需要几个小时或几天的时间。

最近密歇根大学和网易伏羲人工智能实验室提出了一种自动的图像到绘画的翻译方法,以生成风格可控的生动逼真的绘画。该方法称为"风格化神经画家"。「详细论文和项目视频见文末」 该方法不是控制输出图像中的每个像素,而是模拟人类绘画行为,并顺序生成具有明确物理意义的矢量化笔画。这些生成的笔画向量可以进一步用于以任意输出分辨率进行渲染。
该方法不是控制输出图像中的每个像素,而是模拟人类绘画行为,并顺序生成具有明确物理意义的矢量化笔画。这些生成的笔画向量可以进一步用于以任意输出分辨率进行渲染。
利用该方法可以绘制不同的风格,例如:油画画笔、水彩墨水、记号笔和胶带艺术。此外还可以自然地嵌入到神经风格转移框架中,并可以基于不同的风格参考图像来联合优化以转移其视觉风格。
方法
该方法由三个技术模块组成:
一个神经渲染器,它被训练为在给定一组矢量化笔画参数的情况下生成笔画; 以可区分的方式组合多个渲染笔画的笔画混合器; 相似性测量模块,将输入图像的重建。
接下来,我们将介绍每个模块如何相应地工作。
神经渲染器
要构建一个神经渲染器,一般的做法是构建一个深度卷积网络,并训练它模仿图形引擎的行为。先前的研究建议使用堆叠转置卷积或位置编码器+解码器架构。这些方法可以在简单的笔画渲染场景中很好地工作。然而,我们发现这些渲染器在使用更复杂的渲染设置(如颜色过渡和笔画纹理)进行测试时,可能会受到形状和颜色表示的耦合影响。该方法通过设计一个双通道神经渲染器来解决这个问题,该渲染器通过渲染管道来解开颜色和形状/纹理。
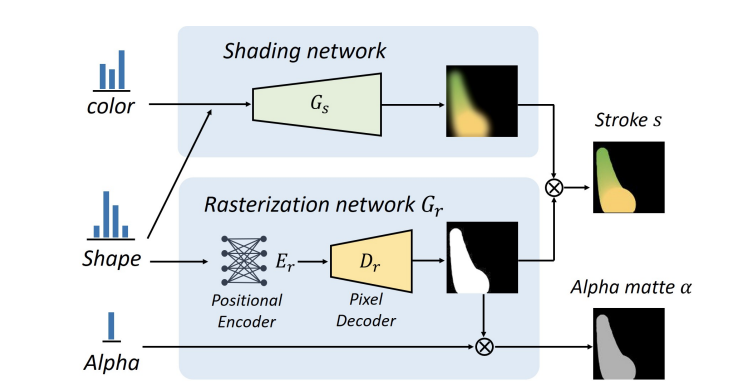
它由一个着色网络Gs和一个光栅化网络Gr组成。该渲染器接受一组笔画参数(颜色、形状和透明度),并生成光栅化的前景贴图和阿尔法遮罩。
训练神经渲染器,在渲染的笔画前景和阿尔法遮罩上都有标准的2像素回归损失。在培训过程中,我们将以下目标函数最小化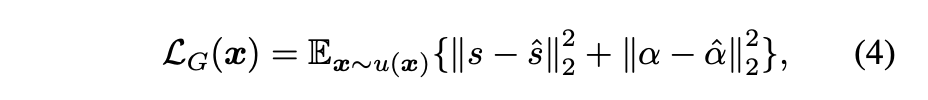
像素相似性和零梯度问题
有许多方法可以定义渲染输出hT和参考ht之间的相似性,也许最直接的方法是定义像素级损失,例如1或2损失。当通过直接从像素空间优化来处理图像时,使用逐像素损失可以很好地工作。
然而,当涉及到优化笔画参数时,像素损失并不总是保证有效的梯度下降。特别地,当渲染的笔画和它的背景不共享重叠区域时,将会有一个0。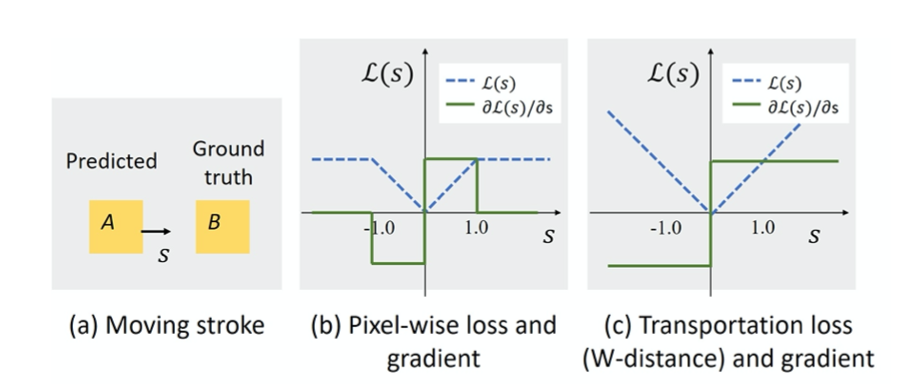
下图给出一个例子展示了当优化像素损失和传输损失。由于像素"1"丢失,笔画无法沿着正确的方向移动,因为在其参数化位置上没有梯度,而使用传输丢失使笔画很好地收敛到目标。
笔画搜索的最佳传输
在这篇文章中,使用了经典的最优运输距离的平滑版本和熵正则项,这产生了著名的天坑距离。天坑距离是可微的,并且具有良好的数学性质,这可以导致比原始距离低得多的计算成本。
主要思想是考虑除u之外的联合概率矩阵P上的额外熵约束。进一步使用拉格朗日乘数,可以将问题转化为正则形式(5)。我们假设标段为最佳运输损失,即从一个位置到另一个位置的最小运输努力,然后用下面的方法将其定义为天坑距离。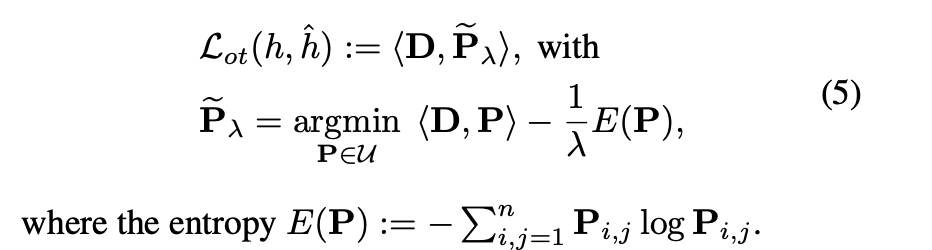
神经模式转换的联合优化
由于在参数搜索范式下构建我们的预测,我们的方法自然适合神经类型转移框架。神经风格转移模型通常被设计为更新图像像素,以最小化内容损失和风格损失的组合。
为了编辑渲染输出的全局视觉样式,定义如下相似性损失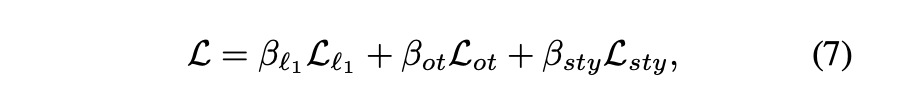
实施细节
构建了类似于DCGAN的生成器的着色网络,它由六个转置的conv层组成。我们从输出层移除Tanh激活,并观察到更好的收敛。在光栅化网络中,首先构建具有四个完全连接的层的位置编码器,然后构建具有六个conv层和三个像素混洗层的像素解码器。我们还对"UnET"的体系结构进行了实验,在这种情况下,我们将笔画参数在其空间维度上平铺为3D张量,作为网络的输入。

训练细节。通过使用亚当优化器来训练我们的渲染器。将批量设置为64,学习率设置为2e-4,betas设置为(0.9,0.999)。每100个纪元把学习率降低到1/10,400个纪元后停止训练。
在每个时期,使用矢量引擎随机生成50,000x64个地面真实笔划。将渲染输出大小设置为128x128像素。为每种笔画类型分别训练渲染器。
渐进式渲染。为了渲染更多的细节,设计了一个渐进的渲染管道在规模和行动方面。我们首先从在一个128x128的画布上搜索参数开始,然后划分canvas分成m × m个块(m = 2,3,4,...)。重叠,并相应地搜索每一个。在每个块比例中,逐渐向“活动集”添加新笔画,并逐步更新笔画。在每次更新中,同时优化活动集中的所有笔画。
实验分析

上图中,该方法与最近提出的两种基于笔画的图像到绘画的翻译方法进行比较,我们可以看到,该方法在笔刷纹理上有明显的区别,从而产生更生动的结果,而其他方法往往会产生模糊的结果。

上图中,其中第二列由纽约著名艺术家亚当·李斯特创作的结果。我们可以看到手动结果和自动结果都呈现出低比特的艺术几何绘画效果。
视频链接
资料链接:
长按扫码,发消息 [画家]