
端到端LSTR:Transformer让车道线检测速度快(420 fps)到飞起!

极市导读
西安交通大学等发布最新论文End-to-end Lane Shape Prediction with Transformers。使用Transformer捕获道路中细长车道线特征和全局特征,性能优于PolyLaneNet等网络,速度可高达420 FPS!>>加入极市CV技术交流群,走在计算机视觉的最前沿
1 摘要

论文地址:
https://arxiv.org/pdf/2011.04233.pdf
代码地址(即将开源):
https://github.com/liuruijin17/LSTR
2 本文思路
3 具体实现
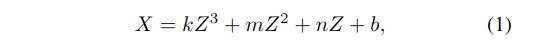
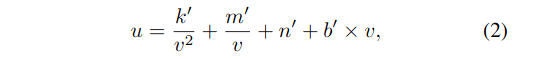
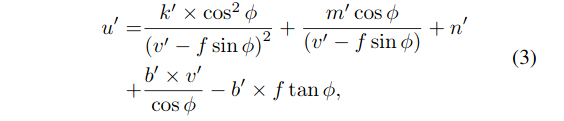
Curve re-parameterization
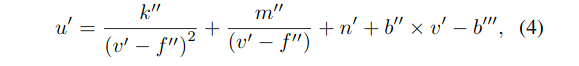
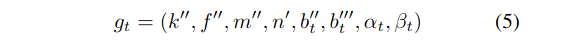
Bipartite matching
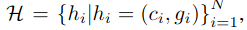 (0: non-lane, 1: lane)。
(0: non-lane, 1: lane)。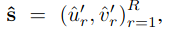
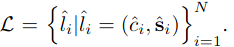
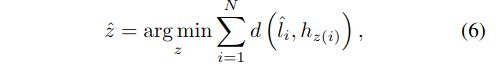
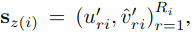
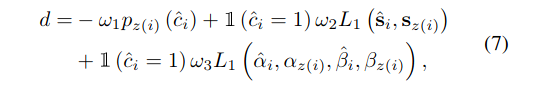
Regression loss
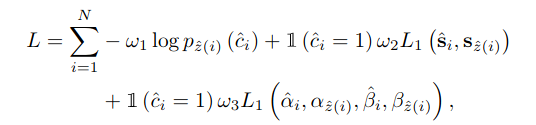
给定输入图像I,主干提取低分辨率特征,然后通过压缩空间维度将其压缩成一个序列S。S和位置嵌入Ep馈入transformer Encoder以输出表示序列Se。 然后,Decoder首先处理一个初始查询序列Sq和一个隐式学习位置差异的学习位置嵌入ELL生成输出序列Sd,计算与Se和Ep的交互以处理相关特征。 最后,有几种FFNs直接对所提出的输出参数进行预测。
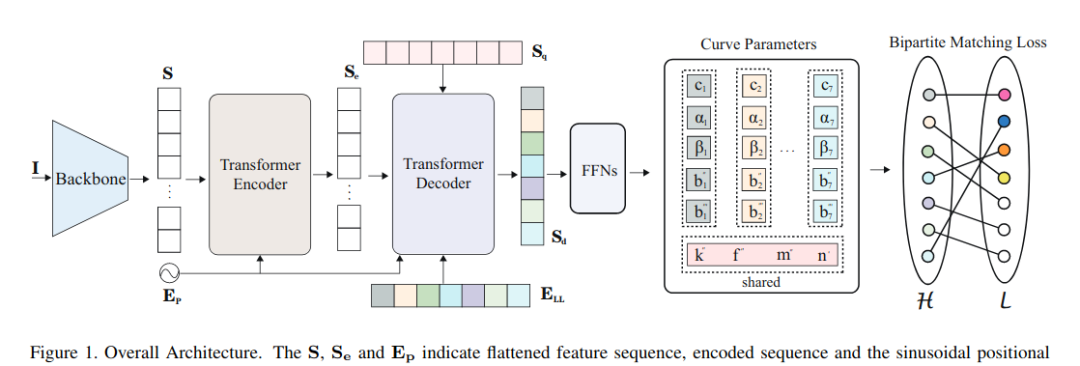
Backbone
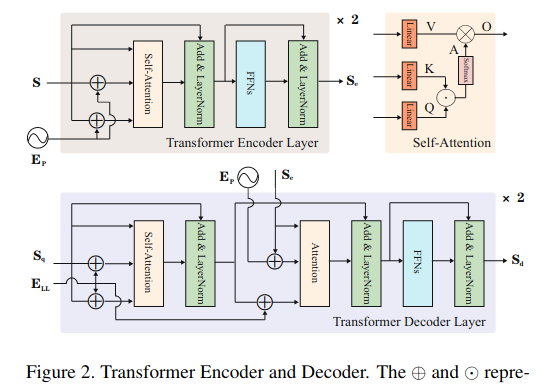
Encoder
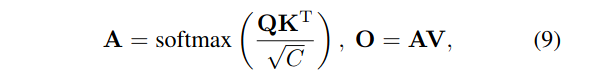
Decoder
FFNs用于预测曲线参数
4 实验结果
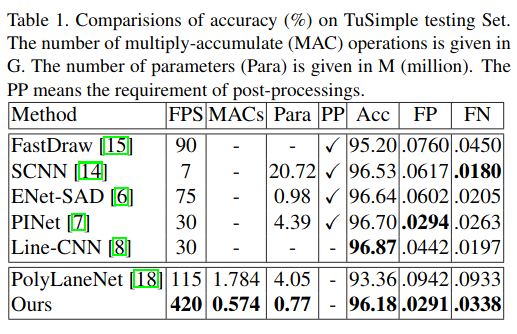

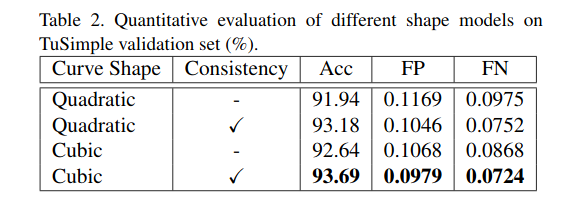
Investigation of Shape Model
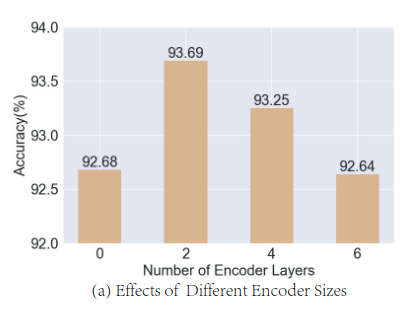
Number of encoder layers
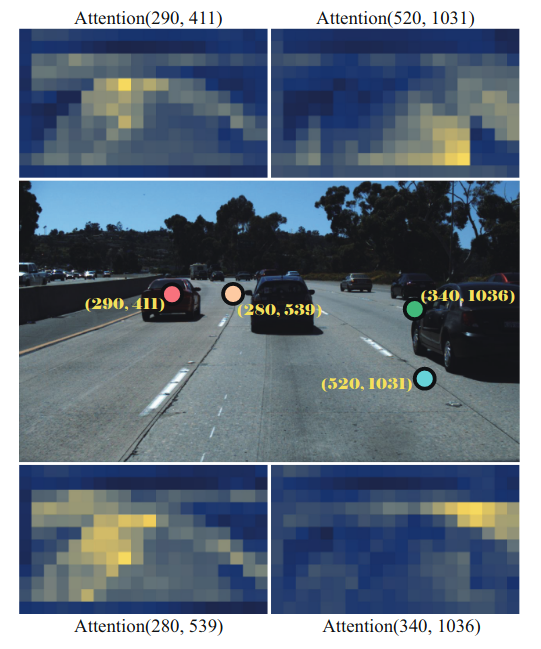
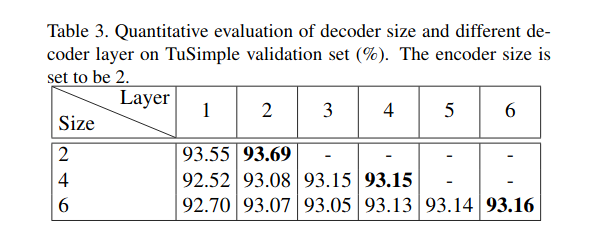
Number of decoder layers
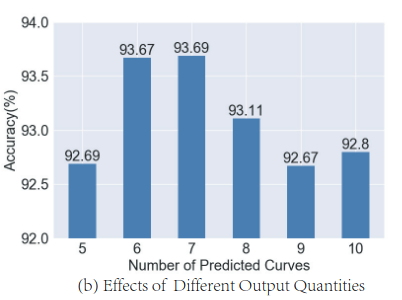
Number of predicted curves

推荐阅读

评论