
新一代推理部署工具FastDeploy与十大硬件公司联合打造:产业级AI模型部署实战课
人工智能产业应用发展的越来越快,开发者需要面对的适配部署工作也越来越复杂。层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求、不同操作系统和开发语言,为AI开发者项目落地带来极大的挑战。

12月12日-12月30日,《产业级AI模型部署全攻略》系列直播课程,FastDeploy联合10家硬件公司与大家直播见面。欢迎大家扫码报名获取直播链接,加入交流群与行业精英共同探讨AI部署话题。
FastDeploy开源项目地址
简单易用
多语言统一部署API,3行代码搞定模型部署
一键体验预置150+热门模型,覆盖20多主流产业应用场景

10多个端到端的部署工程Demo,助力快速集成

全场景
统一多端部署API,一行代码,灵活切换多推理引擎后端

FastDeploy切换推理引擎后端
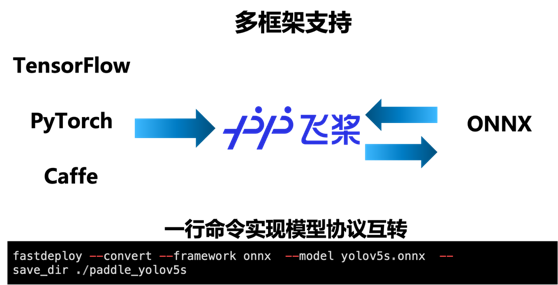
多框架支持,一行命令实现模型协议互转
FastDeploy一行代码切换多端部署
多硬件适配,快速实现多硬件跨平台部署
极致高效
软硬联合自动压缩优化,减少部署资源消耗

FastDeploy一键自动压缩,减少硬件资源消耗
端到端前后预处理优化,减少部署资源消耗

FastDeploy前后预处理优化,减少硬件资源消耗
目前FastDeploy已经支持包括X86 CPU、NVIDIA GPU、Jetson、飞腾 CPU、昆仑 XPU、Graphcore IPU、华为昇腾 NPU、ARM CPU(联发科、瑞芯微、树莓派、高通、麒麟等ARM CPU硬件)、瑞芯微 NPU、晶晨 NPU、恩智浦 NPU等十多类AI硬件。开发者可以通过FastDeploy这款产品,满足全场景的高性能部署需求,大幅提升AI产业部署的开发效率。
直播预告

评论