
你常看到 Python 代码中的 yield 到底是什么鬼?

首先我们来看下这两个列表的区别:
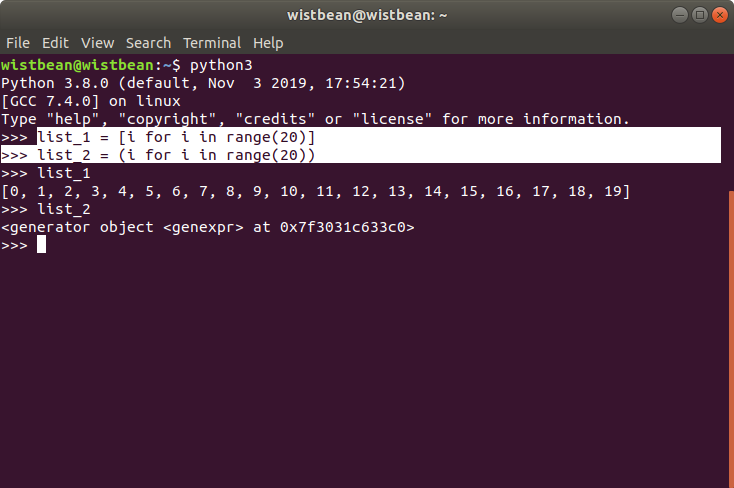
可以看到, list_1 是 [i for i in range(20)] ,而 list_2 是 (i for i in range(20)),主要区别就是一个是 [] , 一个是 (),而后者就是生成器。
可以看到,当我们去执行 list_2 的时候,输出结果是一个 generator(生成器)对象。
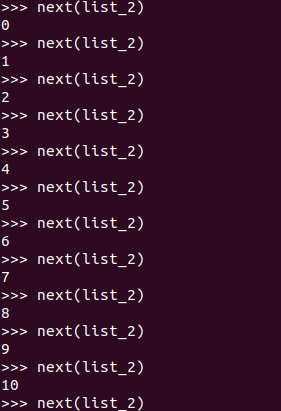
我们可以通过 next() 去调用这个生成器里面的元素:
我们这样,来计算一下以下这两个列表生成所需要的时间:
list_1 = [i for i in range(66666666)]list_2 = (i for i in range(66666666))
我们分别把它们放到方法里面执行,然后用装饰器的方式对它们各自的方法执行时间做个记录:
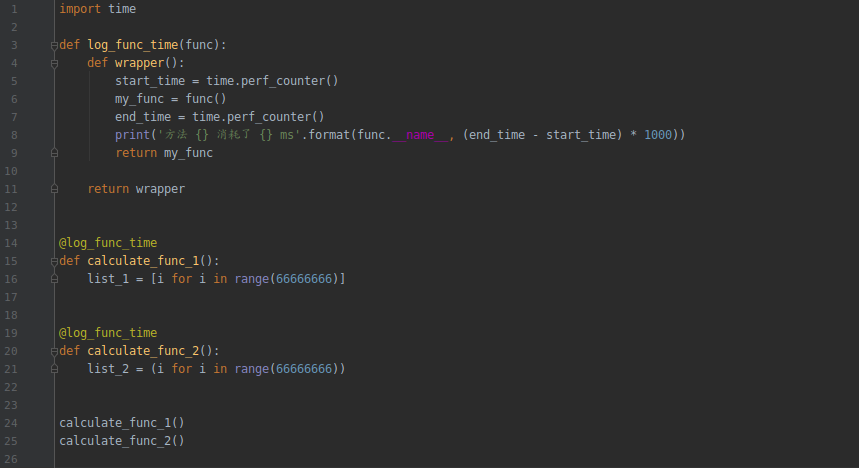
执行结果如下:

这是因为使用列表生成式生成的列表,是固定的,也就是说,当我们执行 [i for i in range(66666666)] 的时候, list_1 这个列表所封装的元素个数就是 66666666 -1 个。
而生成器生成的 list_2 就不是这样,它是记录了一定的算法规则,比如我们这里的 for i in range(66666666) 就是不断的 +=1 ,生成器只要记住这个规则就可以了,不需要将全部的数据都直接一股脑的装进 list_2 ,而是等到我们需要的时候,我们去调用的时候,它再去算一下,然后把相应的数据返回给我们。
这,就是生成器,记住一点,它是根据一定的规律算法生成的,当我们去遍历它的时候,它可以通过特定的算法不断的推算出相应的元素,边运行边推算结果,从而节省了很多空间。
体会下下面这两者的区别:
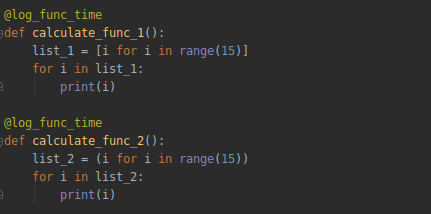
yield 和 return 有点相似,return 这个关键词你应该很熟悉吧,在函数中只要执行到这个关键词,就会返回相应的结果并且终止函数的执行:
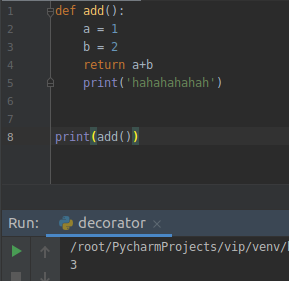
很好理解,这里返回 3 而不会继续返回 hahahahah。
那么 yield 又是怎么样的呢?咱们继续看:
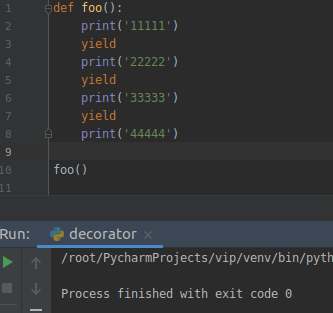
那么我们来看看调用了这个 foo 函数之后得到的是什么类型:
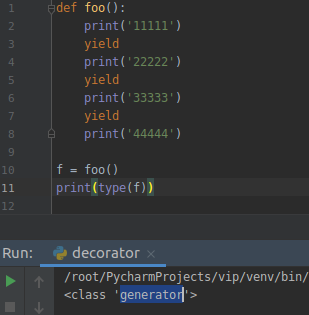
是的,一个函数里面如果被定义了 yield ,那么这个函数就是一个生成器。
我们可以通过 next 方法来使用这个生成器:
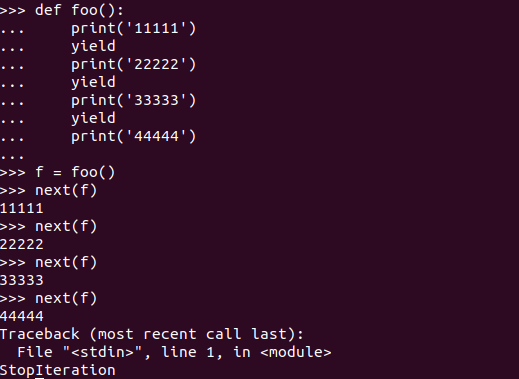
可以看到,当我们第一次调用的时候,遇到第一个 yield 的时候就跳出函数了,第二次调用的时候就是从第 1 个 yield 开始,第三个 yield 结束,以此类推。直到 next 没有数据之后报 StopIteration。
既然它是一个生成器,那么我们就可以遍历它,我们具体打印出每个具体的元素,看看是什么:
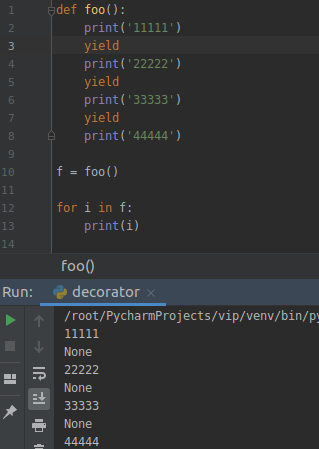
不过呢,我们一般不会这么写,我刚刚说了,生成器是根据一定的规律算法生成的列表,当我们去遍历它的时候,它可以通过特定的算法不断的推断出相应的元素,边运行边推算结果,节省空间。
所以 yield 一般会在 for 循环语句以一定的规则生成,举一个最简单的例子,生成这么些偶数:
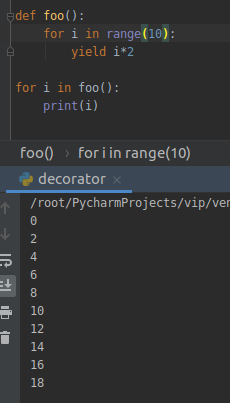
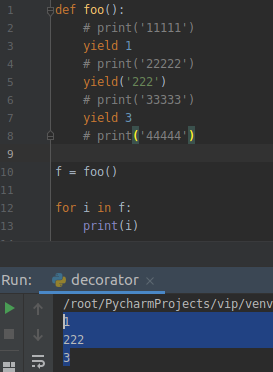
这样我们在调用 foo 的时候就会得到一个生成器,然后就可以直接遍历使用。另外,yield 后面可以跟常用的数据类型,比如 string,int,dict:

那么当你下次去调用相应的函数就会得到这样的 generator,于是就可以:OMG,根据对应的规则遍历它!

扫一扫
学习 Python 没烦恼
评论