
用Python搞定抖X无水印短视频下载

作者 | 道才
来源 | 可以叫我才哥
有时候刷抖音,遇到喜欢的视频保存在本地,然后都是带有水印的,作为有一点“洁癖”的小编,不太喜欢。索性就自己用Python制作了这个简单的小工具,用于下载抖音无水印短视频!
目录:
1. 需求分析
2. 寻金定穴
3. 下载视频
4. 制作GUI
5. 打包


1. 需求分析
这里我们是通过PC端的www.douyin.com里查看需要下载的视频,然后解析出其下载地址后进行下载。
先找到 目标视频 的详情页, 比如我们刷到下面这个视频,点击右下角的详情即可进入到目标视频的详情页。
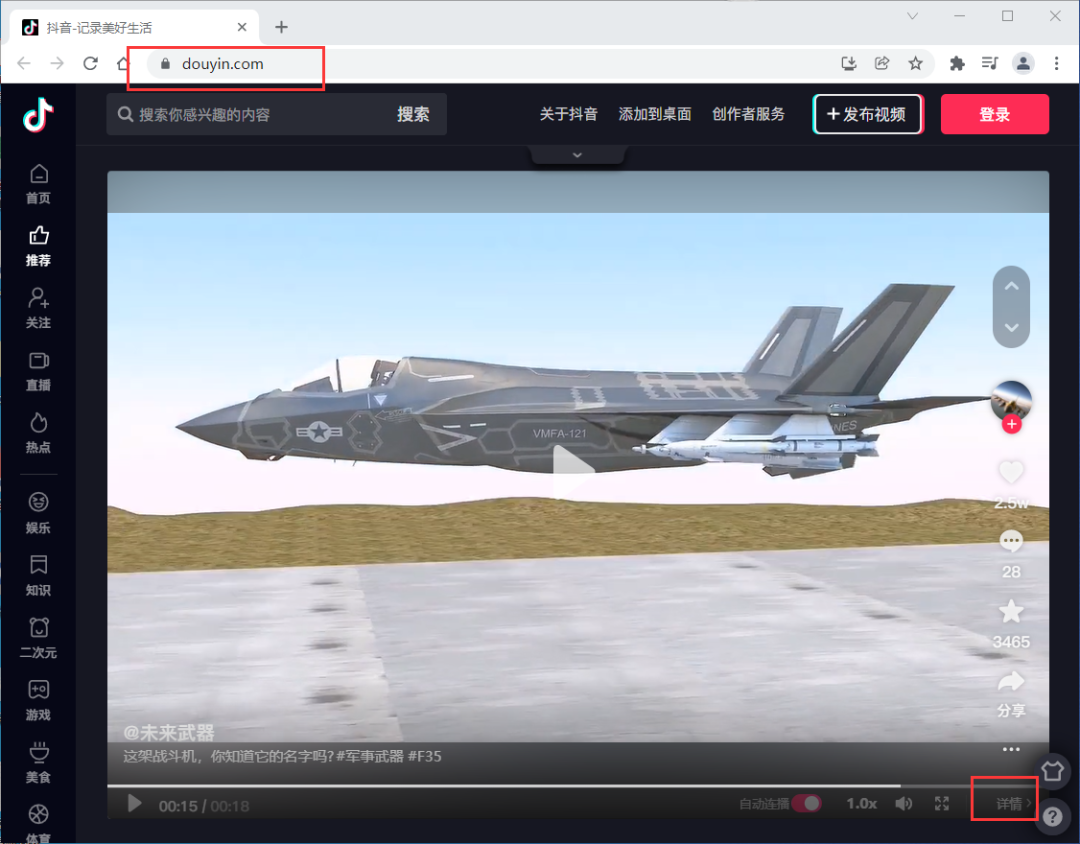
以下就是详情页,可以看到url最后一个应该是视频id
这也将是本文案例的视频详情url地址
https://www.douyin.com/video/7049314157723766024
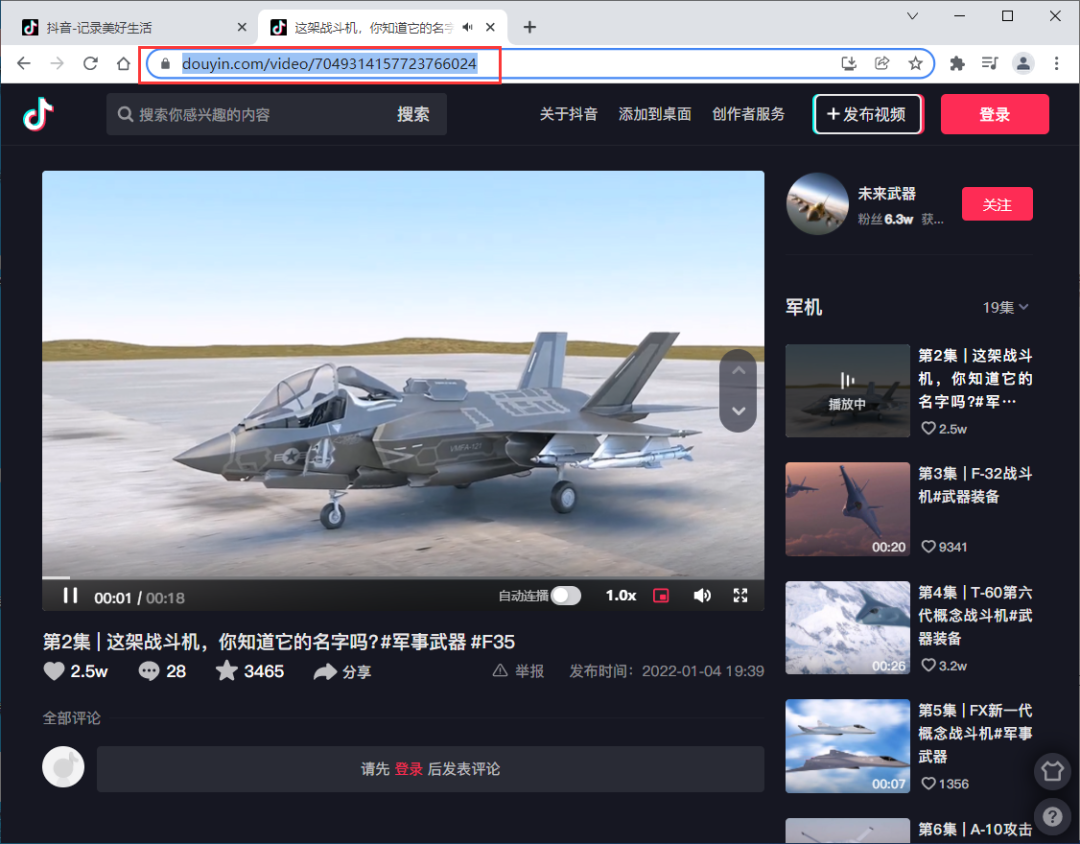
再确定了目标视频详情页之后,我们就要找到视频真身所在,确定真身后就可以直接下载了。
最终我们小工具的形态就是只需要填写视频详情url地址即可一键下载~
需要引入的第三方库
import requests
import time
import re
import json
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from urllib.parse import unquote
import PySimpleGUI as sg
没有安装这些库的话,直接pip install 搞起!
2. 寻金定穴
老规矩,F12找起来!
这里F12—>网络—>媒体,然后刷新页面就找到了。。。
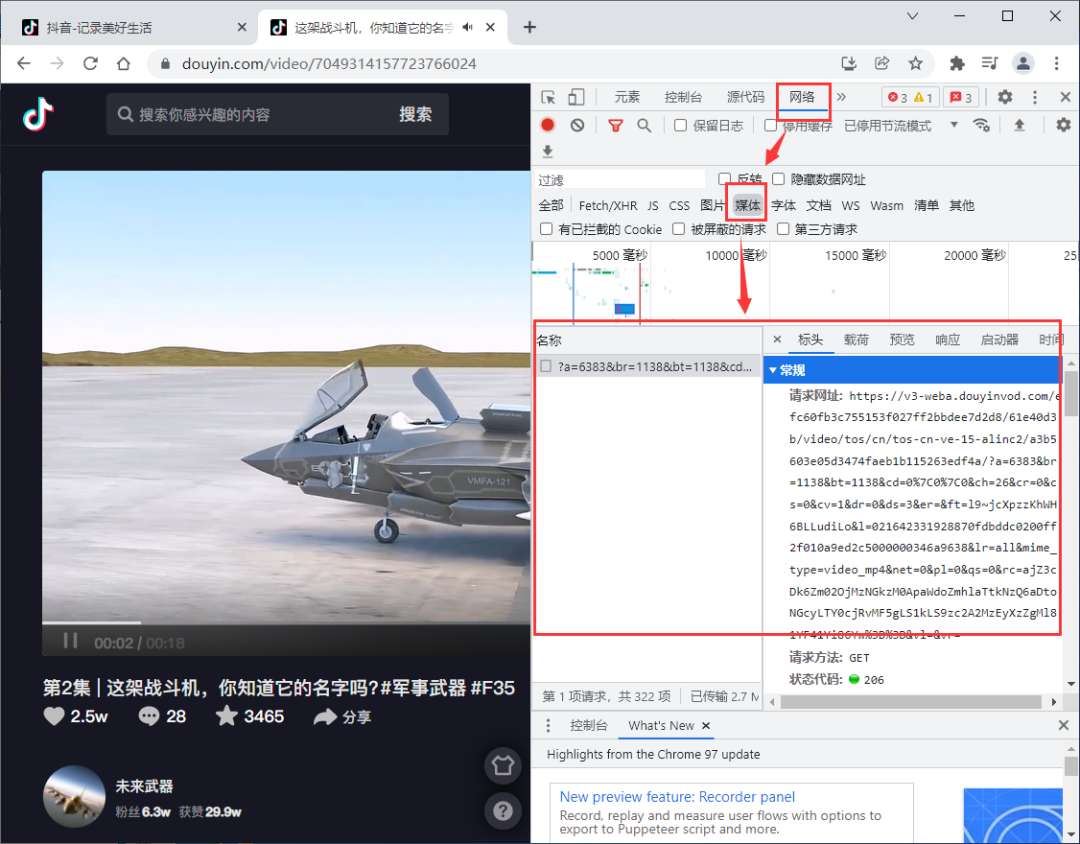
但是这玩意又臭又长,感觉完全看出不规律,咋办!
那就去网页元素里找找吧!复制请求网址中部分片段,然后去元素里ctrl+F找起来!居然真的找到了!!
file_url = 'https://v3-weba.douyinvod.com/44563c92986b4b7a953475e5fc4c00fb/61e40f39/video/tos/cn/tos-cn-ve-15-alinc2/a3b5603e05d3474faeb1b115263edf4a/?a=6383&br=1138&bt=1138&cd=0%7C0%7C0&ch=26&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=l9~jcXpzzKhWH6B1UDmiLo&l=021642332439844fdbddc0200fff0050a90bd4d0000011daf0d4b&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ajZ3cDk6Zm02OjMzNGkzM0ApaWdoZmhlaTtkNzQ6aDtoNGcyLTY0cjRvMF5gLS1kLS9zc2A2MzEyXzZgMl81YF41Yi86Yw%3D%3D&vl=&vr='
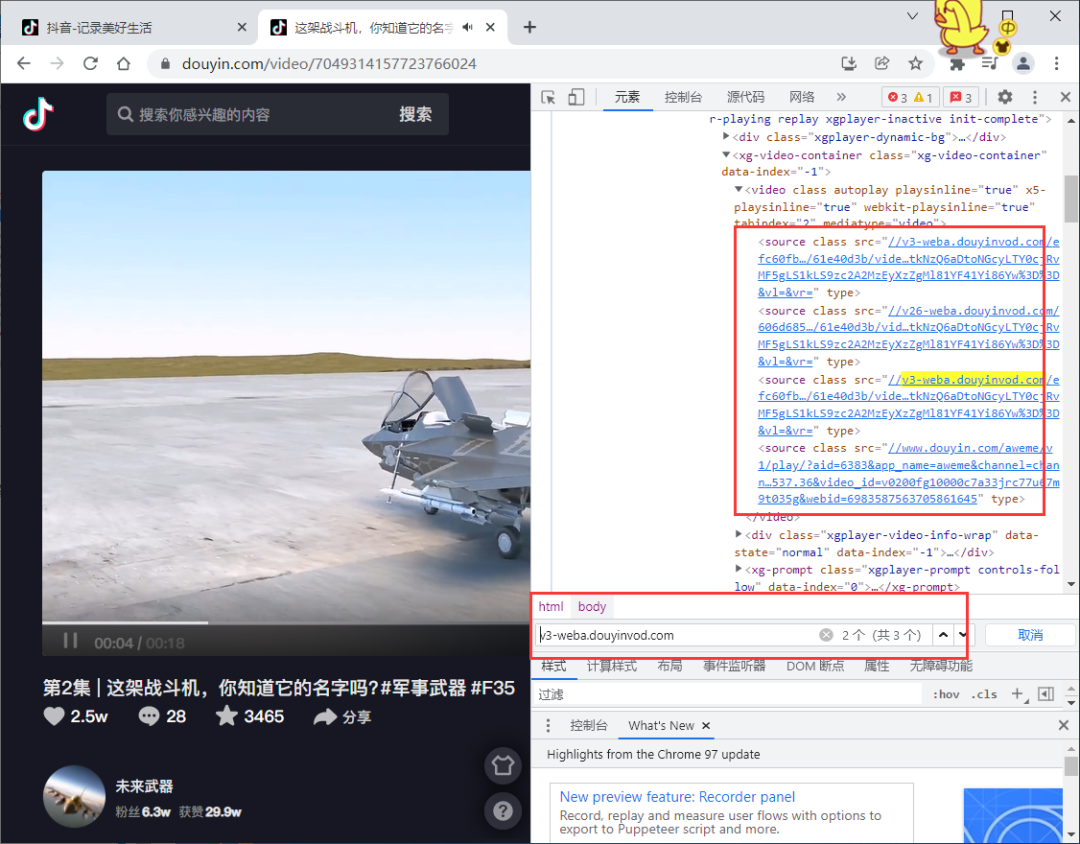
接着我们用requests请求一下视频详情页,需要注意这里需要带cookie信息,否则请求的数据有问题!
关于cookie,这里提供两种方案供选择
自己复制网页里的 cookie信息即可(最方便)通过 selenium模拟浏览douyin,然后获取cookie存本地待调用
本来想用无头浏览器形式,结果发现获取不到cookie,另外就是可能selenium打开抖音的时候需要滑块验证一下否则也获取不到cookie。
# 获取cookie
def get_cookies():
# 初始化浏览器为chrome浏览器
# 无界面的浏览器
# option = webdriver.ChromeOptions()
# option.add_argument("headless")
# browser = webdriver.Chrome(ChromeDriverManager().install(),options=option)
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.set_window_size(100,100)
browser.get(r'https://www.douyin.com')
cookie_list = browser.get_cookies()
# 关闭浏览器
browser.close()
return cookie_list
不过,在请求到的网页源代码里,我并没有找到。但是通过仔细分析、认真查找,终于发现!
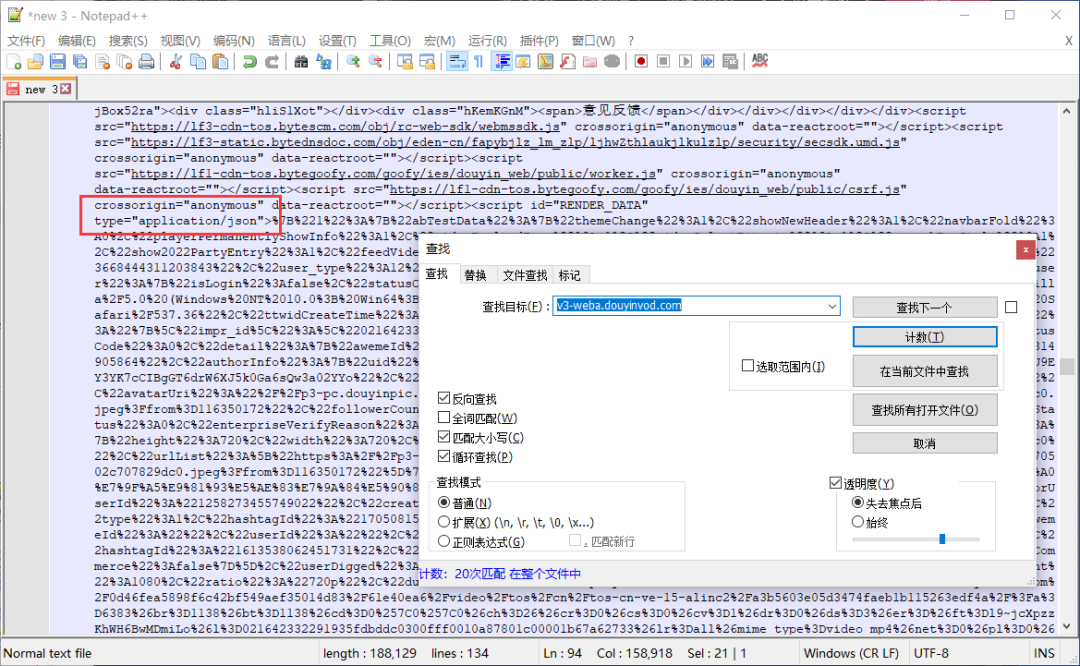
我也是查了一些资料才知道这里字符都是像URL的%打头的编码形式,所以接下来我们要做的是先解析出这部分内容,然后转码一下。
# 获取抖音短视频文件地址
def get_file_url(url, cookie_list):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
"referer": "https://www.douyin.com"
}
cookie_dict = {}
for cookie in cookie_list:
cookie_dict[cookie['name']]=cookie['value']
try:
resp = requests.get(url, headers=headers, cookies=cookie_dict)
s = re.findall(r'', resp.text)
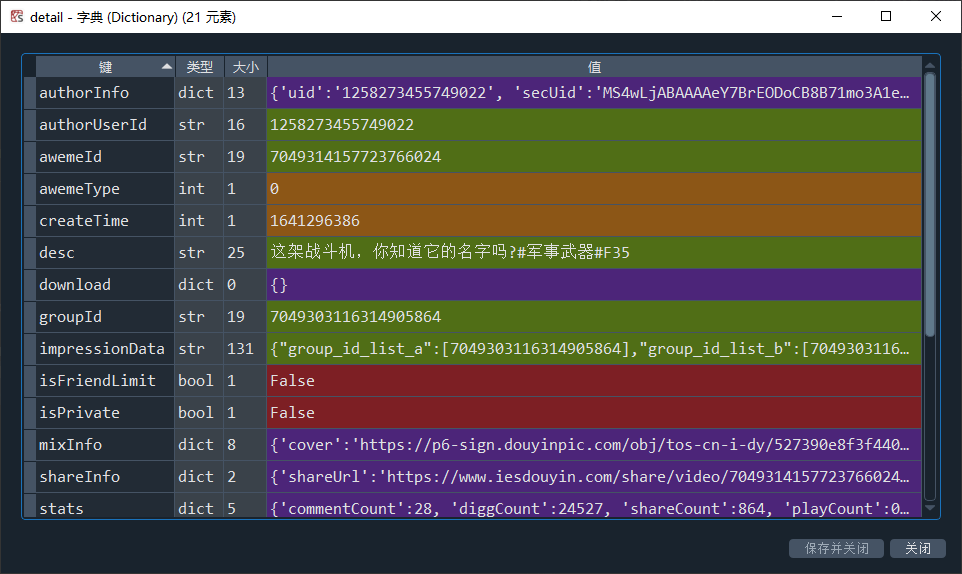
json_data = json.loads(unquote(s[0]))
title = json_data['21']['aweme']['detail']['desc']
file_url = 'https:'+json_data['21']['aweme']['detail']['video']['playApi']
return file_url, title
except:
print('\n视频链接请求失败!!')
return False
反正解析出来的结果很赞,就是能找到!
3. 下载视频
既然知道了视频的下载地址和视频名称,直接下载程序搞起即可:
# 下载视频
def down_file(file_url, title):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
"referer": "https://www.douyin.com"
}
start_time = time.time()
print('------开始下载------')
resp = requests.get(url = file_url, headers=headers)
if resp.status_code==200:
# 设置单次写入数据的块大小
chunk_size = 1024*1024*10
# 获取文件大小
file_size = int(resp.headers['content-length'])
# 用于记录已经下载的文件大小
done_size = 0
# 将文件大小转化为MB
file_size_MB = file_size / 1024 / 1024
print(f'【视频大小】:{file_size_MB:0.2f} MB')
title = re.sub(r'\\|\/|\:|\*|\?|\<|\>|\|','',title)
with open(title + '.' + 'mp4', mode='wb') as f:
for chunk in resp.iter_content(chunk_size=chunk_size):
f.write(chunk)
done_size += len(chunk)
# print(f'\r下载进度:{done_size/file_size*100:0.2f}%',end='')
end_time = time.time()
print('------下载完成------')
cost_time = end_time-start_time
print(f'【累计耗时】:{cost_time:0.2f} 秒')
print(f'【下载速度】:{file_size_MB/cost_time:0.2f}M/s', end='\n')
else:
print('下载失败!!')
话不都说了,参考之前《用Python制作一个B站视频下载小工具(文末附完整代码)》。
小提示:windows系统下文件名不能含\/:*?<>|,对于解析出来的title需要特别处理下!

4. 制作GUI
这个嘛,老粉们应该也轻车熟路了,毕竟出过好多小工具制作了(文末我们带上过往小工具的案例新来的朋友可以看看)。
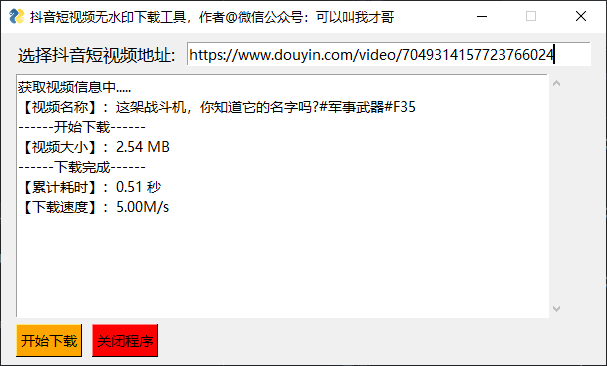
# 布局设置
layout = [[sg.Text('选择抖音短视频地址:',font=("微软雅黑", 12)),sg.InputText(key='url',size=(50,1),font=("微软雅黑", 10),enable_events=True) ],
[sg.Output(size=(66, 12),font=("微软雅黑", 10))],
[sg.Button('开始下载',font=("微软雅黑", 10),button_color ='Orange'),
sg.Button('关闭程序',font=("微软雅黑", 10),button_color ='red'),]
]
# 创建窗口
window = sg.Window('抖音短视频无水印下载工具,作者@微信公众号:可以叫我才哥', layout,font=("微软雅黑", 12),default_element_size=(50,1))
# 事件循环
while True:
event, values = window.read()
if event in (None, '关闭程序'):
break
if event == '开始下载':
Y=1
url = values['url']
print('获取视频信息中.....', end='')
cookie_list = get_cookies()
if Y == 1:
try:
file_url, title = get_file_url(url, cookie_list)
print(f'\n【视频名称】:{title}')
down_file(file_url, title)
except:
print('链接有误,请检查后输入!\n')
Y=0
window.close() 5. 打包
对打包不是很了解的可以参考《2个技巧,学会Pyinstaller打包的高级用法》,这里就简单的命令搞定:
pyinstaller -F -w 抖音短视频无水印下载工具.py
以上就是本次全部内容啦,如果你感兴趣可以点赞、在看与收藏一波~
小工具和源代码链接:https://pan.baidu.com/s/12aBwa1-C9TB7L9nd0K-P0Q提取码:1001
 觉得不错,请点个在看
觉得不错,请点个在看