
PatchmatchNet:一种高效multi-view stereo框架 (CVPR2021 Oral)

极市导读
本文介绍了一篇被CVPR2021收录的工作,该项工作结合了传统的PatchMatch算法以及深度学习的优点,提出了PatchmatchNet。在DTU、Tanks & Temples和ETH3D Benchmark上,其表现出了十分competitive的performance。
给大家介绍一下我们之前关于multi-view stereo的工作。我们结合传统PatchMatch算法以及深度学习的优点,提出了PatchmatchNet。PatchmatchNet在DTU、Tanks & Temples和ETH3D上都取得了不错的表现,并且相比于SOTA方法大幅度地提升了效率。
代码已开源,具体链接如下:
PatchmatchNet: Learned Multi-View Patchmatch Stereo
https://arxiv.org/abs/2012.01411
FangjinhuaWang/PatchmatchNet
https://github.com/FangjinhuaWang/PatchmatchNet
1.背景
当给定一些图像以及对应的相机参数(包括内参和外参)时,multi-view stereo (MVS)主要用来把场景以点云或mesh的方式进行重建。在传统方法中,许多方法(譬如COLMAP、Gipuma、ACMM等)基于PatchMatch算法进行深度图的估计。PatchMatch算法主要包括三个步骤:
Initialization:每个像素随机初始化深度值; Propagation:把每个像素的depth hypothesis传播到周围像素; Evaluation:对每个像素,从所有的hypotheses中选取cost最小的作为估计值。
在Initialization以后,PatchMatch在Propagation和Evaluation之间循环,直至结果收敛。PatchMatch利用了深度图的空间相关性,通过随机初始化和传播过程避免了对所有可能的深度值进行验证,所以对memory要求比较低。
而目前,基于深度学习的方法在各个MVS benchmark上面有了很好的表现。MVSNet是一个十分具有代表性的方法,它在预先给定的深度范围内采样D个depth hypotheses,然后基于plane-sweeping stereo和differential warping构建cost volume,使用3D U-Net进行regularization得到probability volume,最后使用soft argmin(求期望)得到深度的估计。在后续的诸多工作中,由于3D convolution十分昂贵,一些方法(R-MVSNet、D2HC-RMVSNet等)通过使用RNN对cost volume进行sequentially regularization,对显存进行了很好的限制,但是增加了运行时间。另一些方法(CasMVSNet、UCS-Net、CVP-MVSNet等)使用cascade cost volume进行coarse-to-fine的估计,显存和时间都大幅缩减,并且有更好的表现。
2.PatchmatchNet
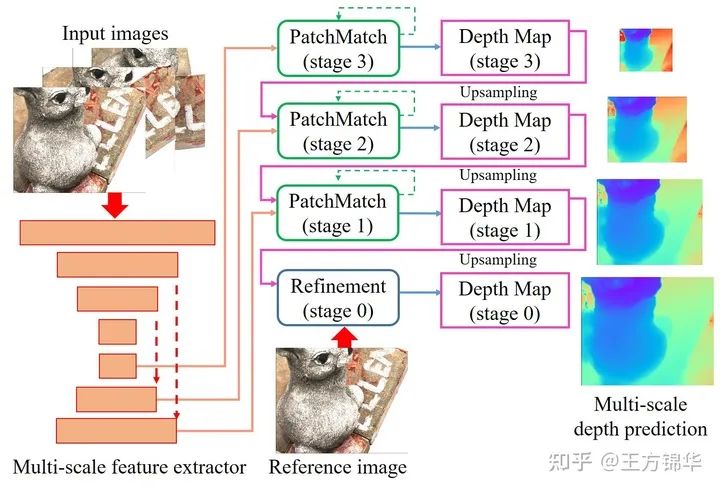
具体而言,PatchmatchNet是一种以learning-based Patchmatch为主体的cascade结构,主要包括基于FPN的多尺度特征提取、嵌入在cascade结构中的learning-based Patchmatch以及spatial refinement模块(用来上采样至原图大小)。
3.Learning-based Patchmatch
我们基于传统的PatchMatch进行修改和拓展,提出了adaptive版本的Patchmatch(仍然包括Initialization、Propagation和Evaluation三个部分)。需要注意的是,不同于传统的PatchMatch方法使用倾斜平面(hypothesis包括depth以及normal),我们出于计算量的考虑,还是像MVSNet那样使用fronto-parallel平面(平面和图像平面平行,hypothesis只包括depth)。使用倾斜平面的话,为确定normal,需要对每个像素所在的邻域进行warping,所以计算比较昂贵。具体结构见下图:
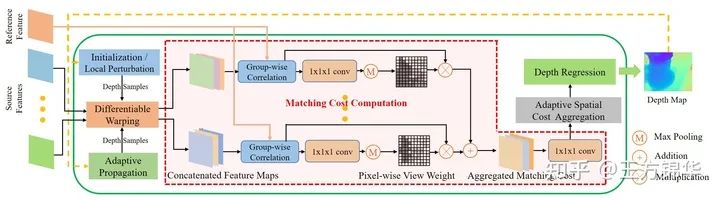
整个流程具体如下:
initialization:在第一个iteration(stage 3的第一个),随机初始化 个sample(为保证sample尽可能分布到整个depth range,将depth range划分为多个区间,在每个区间随机采样); local perturbation:在第一个iteration以后,以前一个iteration得到的估计值为中心,在一个小邻域内采样(local refinement); adaptive propagation:基于特征,对每个像素,将adaptively sampled neighbors的depth hypothesis传递过来; differentiable warping:在得到所有depth hypotheses后(前三个步骤),进行differentiable warping,将source features warp到reference view; matching cost computation:对每个像素和每个depth hypothesis,进行matching cost的计算,使用Pixel-wise view weight(在第一个iteration估计得到,因为第一个iteration的samples能比较好的分布在整个depth range)对所有source views的costs进行aggregation【需要注意的是,在这个步骤,我们只使用了 的卷积,而没有使用大部分方法的3D U-Net,原因有两方面:一是coarse-to-fine结构以及adaptive propagation使得不同像素的hypotheses都不相同,cost volume不规则;二是为了提升效率,具体可参见supplementary】; adaptive spatial cost aggregation:对每个像素和每个depth hypothesis,自适应采样一些邻域内的像素进行cost aggregation; depth regression:得到所有costs以后,用softmax得到每个hypothesis对应的概率,然后求期望得到估计值。
3.1 Adaptive Propagation
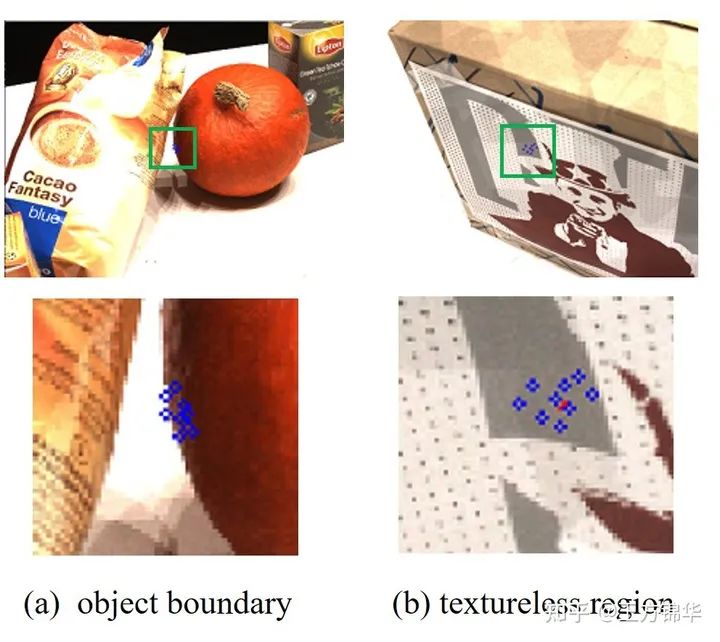
大部分传统方法(譬如Gipuma)使用固定的pattern选取neighbors,进行propagation。但是,深度图的空间一致性往往只对一个表面上的像素成立(周围的neighbors有相似的深度值)。所以,我们希望在采样neighbors的过程中,只采样和当前像素在同一表面上的neighbors,这样的话可以加快算法的收敛速度,提升精度。具体效果如下:
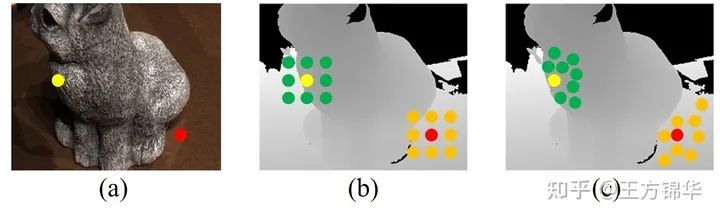
对于边缘的点(黄色),所有的采样点尽可能分布在边界内部。对于untextured area上的点(红色),采样点分布的比较分散,因为untextured area上的估计往往有比较大的ambiguity,比较分散的采样可以降低ambiguity。
具体实现的话,受Deformable Convolution Networks启发,我们构建了一层2D CNN layer,以reference feature为输入,直接输出每个像素 的 个neighbors的additional 2D offset,得到hypothesis集合 :
其中, 是固定的offset(3x3,棋盘状的pattern), 是additional 2D offsets。
实验结果如下:

3.2 Adaptive Spatial Cost Aggregation
在matching cost computation 步骤,我们只使用了 卷积,没有聚合邻域信息。而大部分传统方法都会在一个spatial window里进行cost aggregation以增强匹配的鲁棒性,所以我们提出了adaptive spatial aggregation strategy。与adaptive propagation类似,我们用2D CNN学习得到每个像素 的additional 2D offset 。然后,我们使用feature weight( )和depth weight( )来分配第k个neighbor的贡献权重,计算weighted sum得到cost:
adaptive sampling的实验结果如下:
4.实验
和大部分方法一样,我们在DTU训练数据集上训练模型。然后,我们在DTU测试数据集、Tanks & Temples和ETH3D Benchmark上进行测试。
4.1 DTU
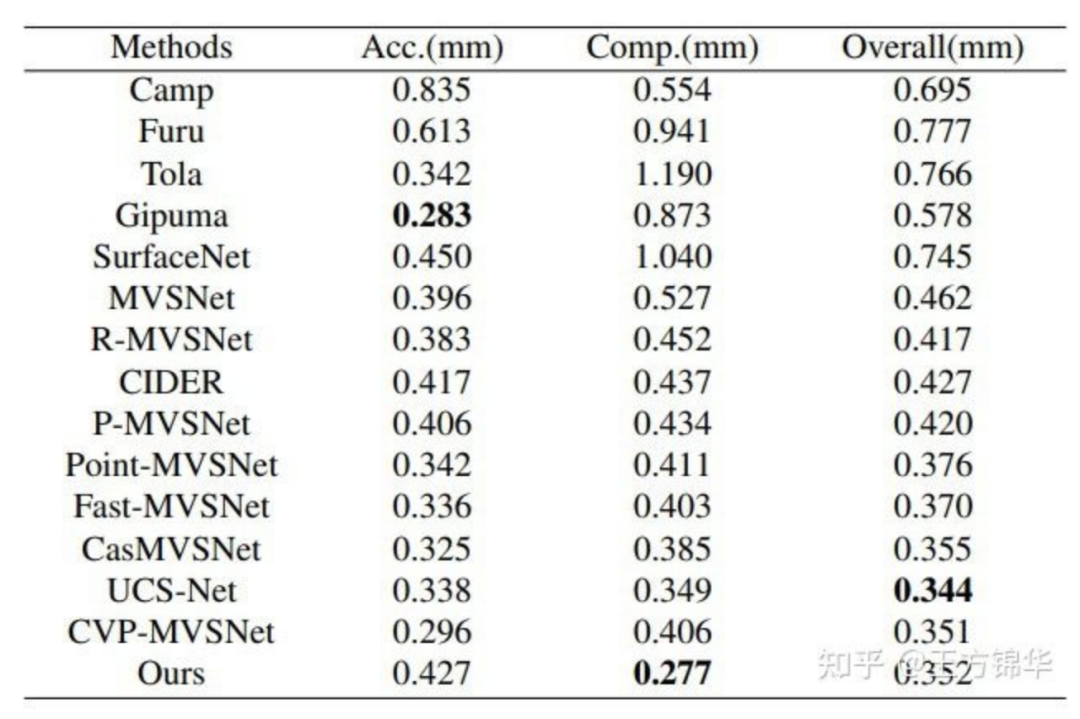 Table 1: DTU数据集上的测试结果(指标越小越好)
Table 1: DTU数据集上的测试结果(指标越小越好)
可以看到,在所有方法中,Gipuma的accuracy最高,PatchmatchNet的completeness最高,并且具有不错的overall quality(accuracy和completeness的平均)。
我们还通过可视化进行了qualitative comparison,如下图所示。可以发现,PatchmatchNet的点云更加稠密,门、窗等细节都重建的比较好,这体现了方法较高的completeness。与此同时,对于屋顶上的一些细节(譬如边缘、尖顶等),PatchmatchNet的重建效果比CasMVSNet更好。一般而言,cascade结构都存在finer level无法完全修正coarse level误差的局限性。而我们提出的adaptive propagation可以使用邻域像素的信息(譬如边界内像素的depth),帮助当前像素跳出local optima,从而使估计更精确。

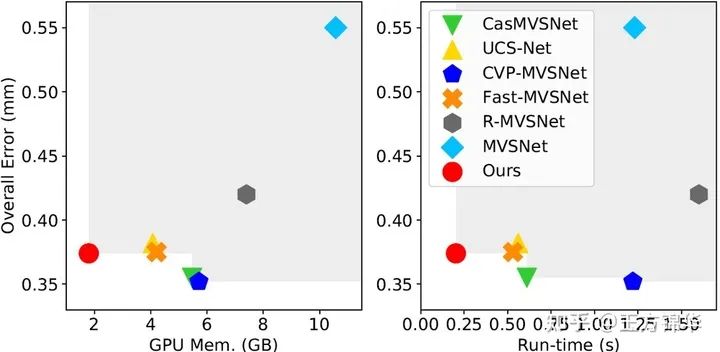
4.2 显存和时间比较
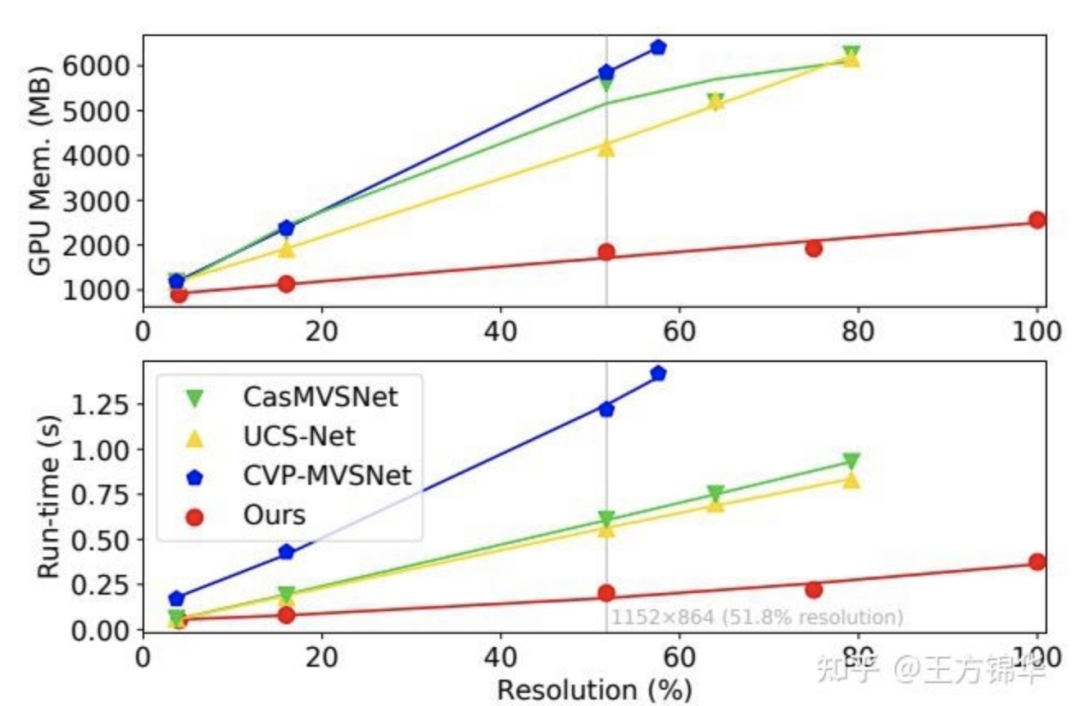
我们和当前的state-of-the-art:CasMVSNet、UCS-Net、CVP-MVSNet进行了比较,具体如图8所示。可以看到,PatchmatchNet的显存消耗和运行时间相比于其他方法有大幅度的减小。譬如在输入图像为 时,显存消耗和运行时间比CasMVSNet减少67.1%和66.9%,比UCS-Net减少55.8%和63.9%,比CVP-MVSNet减少68.5%和83.4%。
4.3 Tanks & Temples
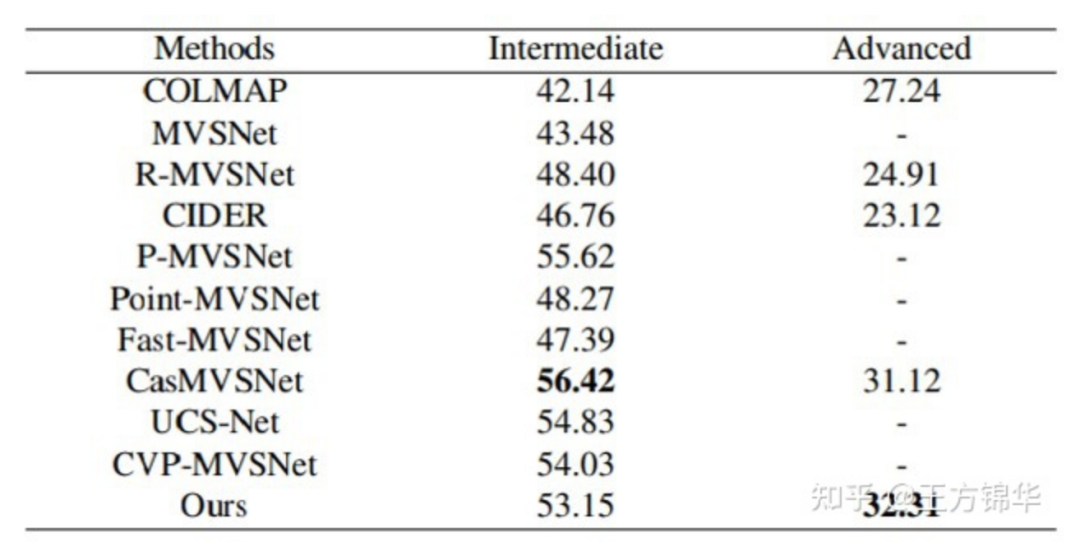
在Tanks & Temples上,我们直接使用了在DTU上训练得到的模型(没有fine-tuning)。在intermediate数据集上,PatchmatchNet的表现较好。在advanced数据集上,PatchmatchNet表现最好。
4.4 ETH3D Benchmark
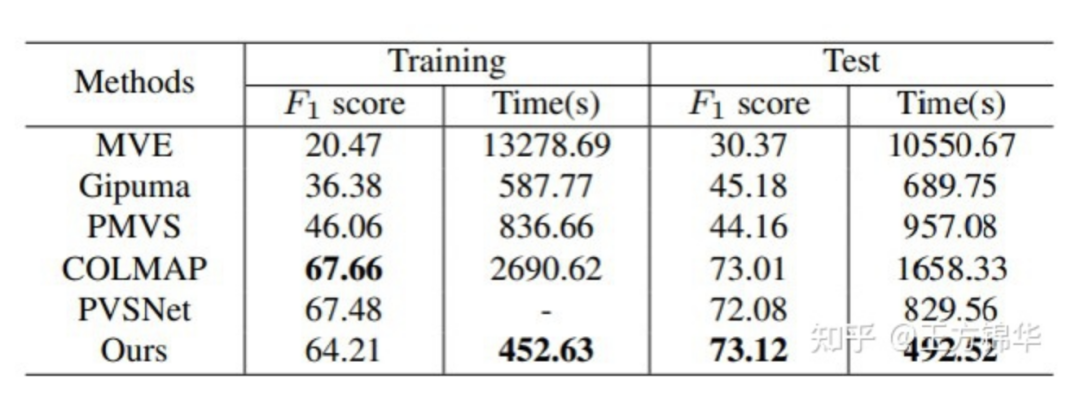
同样,在ETH3D Benchmark上,我们直接使用了在DTU上训练得到的模型(没有fine-tuning)。在Training数据集上,PatchmatchNet的表现接近于COLMAP。在Test数据集上,PatchmatchNet表现最好。与此同时,PatchmatchNet是目前在ETH3D Benchmark上运行时间最短的方法。
5. 小结
在这个工作中,我们提出了PatchmatchNet,一种以learning-based Patchmatch为主体的cascade结构。我们对传统的PatchMatch进行了拓展,提出了adaptive propagation和adaptive evaluation。在DTU、Tanks & Temples和ETH3D Benchmark上,PatchmatchNet表现出了十分competitive的performance。与此同时,相比于大部分state-of-the-art,PatchmatchNet在显存消耗和运行时间上十分高效。
本文亮点总结
Initialization:每个像素随机初始化深度值; Propagation:把每个像素的depth hypothesis传播到周围像素; Evaluation:对每个像素,从所有的hypotheses中选取cost最小的作为估计值。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“pytorch”获取Pytorch 官方书籍英文版电子版~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
