
千呼万唤始出来!PyTorch Lightning 1.0版发布,终于可以抛弃Keras

新智元报道
新智元报道
编辑:QJP
【新智元导读】在过去的几个月里,PyTorch Lightning的团队一直在微调 API、改进文档、录制教程,现在终于向大家分享 PyTorch Lightning 的 V1.0.0版本。
现阶段人工智能的发展速度远远超过任何单一框架所能跟上的速度,深度学习的领域更是在不断发展的,主要体现在在复杂性和规模上。
类似于Keras,Pytorch Lightning 提供了抽象出所有工程细节,从而方便的使用复杂模型进行交互的一种用户体验。
PyTorch Lightning:Pytorch版的Keras
PyTorch Lightning:Pytorch版的Keras
像 PyTorch 这样的框架是为人工智能研究主要关注网络架构的时代而设计的,例如nn.Module可以定义操作顺序的模块。
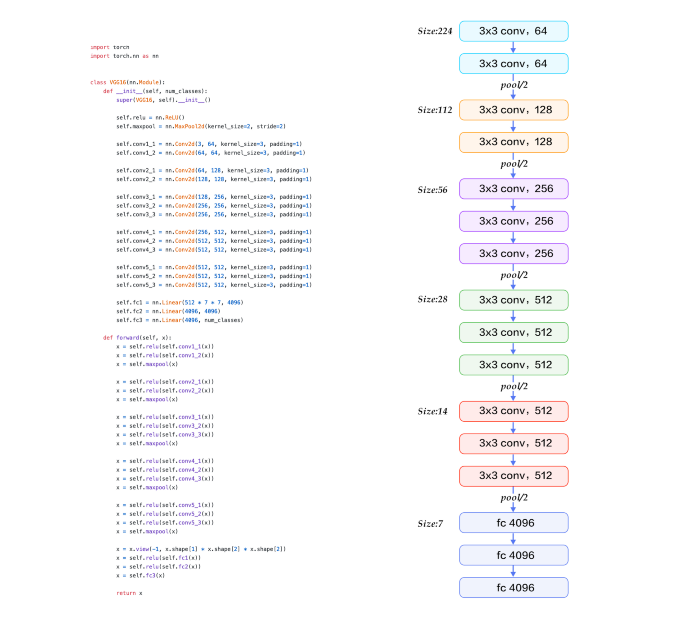 图:VGG 16
图:VGG 16
这些框架在为研究或者生产提供极其复杂的模型所需的所有部件方面做出了巨大的工作,但是一旦模型开始相互作用,比如 GAN,BERT,或者一个Autoencoder,这种模式就会打破。
复杂的模型会失去灵活性,导致在项目规模上很难维护。
与之前出现的框架不同,PyTorch Lightning 被设计成封装一系列相互作用的模型,即深度学习系统。
Lightning 是为当今世界更复杂的研究和生产案例而设计的,在这些案例中,许多模型使用复杂的规则相互作用。
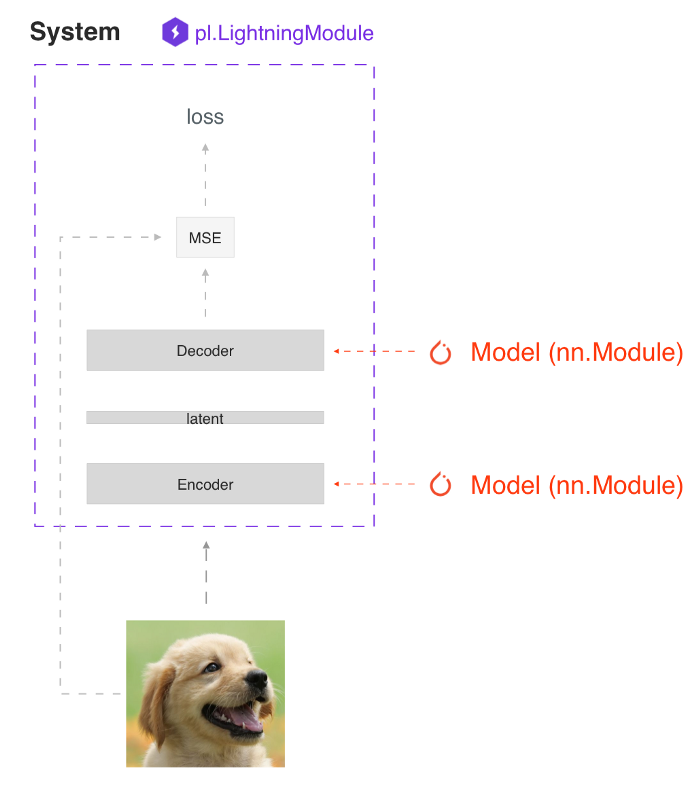 图:antuencoder自动编码系统
图:antuencoder自动编码系统
PyTorch Lightning 的第二个关键原则是硬件和科学代码必须分开。Lightning 可以利用大规模的计算,而不需要向用户显示任何抽象概念。
通过这种分离,Lightning 获得了以前不可能的新功能,比如在笔记本电脑上使用CPU调试你的512 GPU 而不需要更改代码。
 最后,Lightning 创建的愿景是成为一个由社区驱动的框架。
最后,Lightning 创建的愿景是成为一个由社区驱动的框架。
构建好的深度学习模型需要大量的专业知识和使系统工作的Tricks。在世界各地,大量的工程师和博士们一遍又一遍地实现着相同的代码。
Lightning现在有一个不断增长的贡献者社区,其中有超过300个最有才华的深度学习人员,他们选择分配相同的能量,做完全相同的优化,但是却有成千上万的人从他们的努力中受益。
Pytorch Lightning 1.0.0新功能抢先看
Pytorch Lightning 1.0.0新功能抢先看
Lightning 1.0.0标志着一个稳定的最终 API。这意味着开发者依赖于 Lightning 的项目可以放心地知道他们的代码在未来不会中断或改变。
研究与生产
Lightning的核心力量是使最先进的人工智能研究能够大规模发生。这是一个为专业研究人员设计的框架,在最大的计算资源上尝试最难的想法,而不会失去任何灵活性。
Lightning 1.0.0现在也可以轻松地在规模上部署这些模型,所有的 Lightning 代码确保所有的东西都可以轻松导出到 onnx 和 torchscript。

因此,这意味着数据科学家、研究人员等团队现在可以成为将模型投入生产的人,而不需要庞大的机器学习工程师团队。
这也是一些领先的公司使用 Lightning 的一个主要原因: 可以作为一种帮助他们大大缩短生产时间而不失去任何研究所需的灵活性的方法。
衡量指标
pytorch_lightning.metrics是一个Metrics API,是为了便于度量开发和在 PyTorch 和 PyTorch Lightning 中使用而创建的。
更新后的 API 提供了一种内置方法,可以跨多个 GPU (进程)计算每个步骤的度量,同时存储统计信息,允许在一个epoch结束时计算指标,而不必担心与分布式后端相关的任何复杂性。
它还对所有的边缘情况都进行了严格的测试,并且包含了越来越多的常用指标的实现,比如 Accuracy、 Precision、 Recall、 Fbeta、 MeanSquaredError 等等。
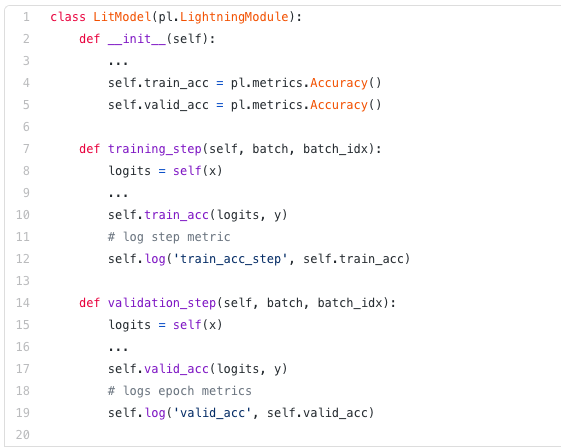 要实现自定义衡量指标,只需子类化基本度量类并实现 _ init _ ()、 update ()和 compute ()方法,所需要做的就是正确调用 add _ state () ,以便使用 DDP 实现自定义度量。对使用 add _ state ()添加的度量状态变量调用 reset ()。
要实现自定义衡量指标,只需子类化基本度量类并实现 _ init _ ()、 update ()和 compute ()方法,所需要做的就是正确调用 add _ state () ,以便使用 DDP 实现自定义度量。对使用 add _ state ()添加的度量状态变量调用 reset ()。
手动优化和自动优化
使用 Lightning,你不需要担心什么时候启用/禁用梯度,做反向传播,或者更新优化器,只要你从training_step返回一个附加图表,Lightning 将自动优化。

然而,对于某些研究,比如GANs、强化学习或者有多个优化器或者内部循环的东西,你可以关闭自动优化,自己完全控制训练循环。
首先,关闭自动优化:

这样,循环就可以自行控制了。
Logging
Lightning 使得与记录器的集成变得非常简单:只需在 LightningModule 的任何地方调用 log ()方法,它就会将记录的数量发送到您选择的logger。默认情况下我们使用 Tensorboard,但是您可以选择任何您希望支持的logger。

根据调用 log ()的情况不同 ,Lightning 会自动确定何时应该进行日志记录(在每个step或每个epoch上) ,但是当然也可以通过手动使用 on _ step 和 on _ epoch 选项来覆盖默认行为。设置on _epoch = True 将在整个训练期内累积日志的值。

数据流
每个循环(训练、验证、测试)都有三个可以实现的hook:「x_step」,「x_step_end」,「x_epoch_end」
为了说明数据是如何流动的,我们将使用训练循环(即: x = training)

你在training_step中返回的任何东西都可以作为训练training_epoch_end的输入。
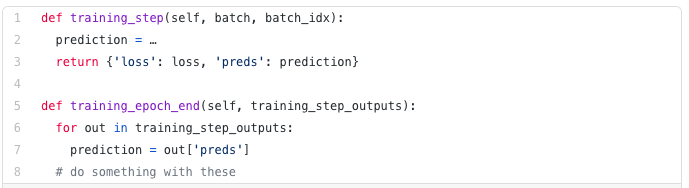
在官方提供的文档中还有更多详细的说明,请见下方的参考链接。
参考链接:
https://github.com/PyTorchLightning/pytorch-lightning/releases

