
ElasticSearch 双数据中心建设在新网银行的实践
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多惊喜

作者简介:
飞熊,目前就职于新网银行大数据中心,主要从事大数据实时计算和平台开发相关工作,对Flink ,Spark 以及ElasticSearch等大数据技术有浓厚兴趣和较深入的理解。
引言
新网银行是作为西部首家互联网银行,一直践行依靠数据和技术驱动业务的发展理念。自开业以来,已经积累了大量数据。早期因为数据量不大全部存入在 Hbase 集群,随着数据 量的增多,Hbase 集群的缺点逐渐被暴露,最显著的问题就是查询返回耗时太长。为了更快, 更好的响应业务,引入了 Elastic Search。Elastic Search 作为大数据搜索查询的一把“利剑”, 能够在海量数据下实现多维分析下近实时返回。并逐渐取代 Hbase,嵌入到新网银行核心业 务线条,成为业务必不可少的一环。
技术方案
银行作为金融机构,对线上业务的连续性有着近乎苛刻的要求,一旦出现问题必然面临 监管机构的问责。因此,为了保证 ElasticSearch 集群的高可用性和灾难恢复性,需要考虑 针对 Elastic Search 集群的双数据中心建设。目前主流的技术方案如下:

表 1. Elastic Search 双数据中心建设方案对比
ElasticSearch 集群是 P2P 模式的分布式系统架构,任意 2 个节点之间的互相通信将会 很频繁。如果考虑单集群跨机房部署,那么可能造成节点之间频繁的通信,那么通信延时会比较高,甚至造成集群运行频繁不正常,且后期维护成本较高。因此采用多集群多机房部署方案。
针对多集群多机房的部署方案,在实际建设的时候也存在多种选择。如考虑应用双写方法或则考虑利用 ElasticSearch 的白金会员特性 CCR(跨集群复制)。但是这 2 中方案也有缺 点:如双写方法需要额外的操作保障一致性;CCR(跨集群复制)的白金会员会提高建设成本。因此,经过多方对比,决定采用解析 ElasticSearch 的 Translog 文件方案。这种方案的优点在于:保证实时性,对外屏蔽应用对数据的感知和实现读写分离。
技术建设
1.Translog 文件介绍
Translog 是 Elastic search 的事务日志文件,它记录所有对分片的事务操作 (add/update/delete),并且每个分片对应一个 translog 文件。Elastic Search 写入数据的时候, 是先写到内存和 translog 文件。因此可以通过对 translog 文件中数据的拦截,实时写入另一 个数据中心。在 Elastic Search 的分片目录下,存在如下 2 种数据文件:
(1) translog-N.tlog: 日志文件,N 表示 generation(代)的意思。每次当 flush 的时 候就会产生一个 generation(代)。
(2) translog-N.ckp: 记录日志信息的元数据文件,N 表示 generation(代)的意思, 记录 3 个信息:偏移量,事务操作数据量和当前代。
对于包含 N 的文件名,意味着没有数据再写入;正在写入的文件,其文件名是不包含 N。
2. Translog 解析
对于日志文件的解析,采用的思想是:部分先行,结束补全。即每次跳过上次读取偏 移量后读取数据,同时等待当前日志文件写完后再读取一次全量数据写入。这样做的目的是为了,补全截取正在写入日志文件时丢失的数据,同时保证数据的时效性。整个解析过程如下:
 图 1.分片下 Translog 解析方法
图 1.分片下 Translog 解析方法
3.线上部署
目前部署方式是采用非嵌入式的,即将代码作为一个单独的应用程序,即命名为 X-CCR 工具,部署到 Elastic Search 的节点服务器上。通过 X-CCR 实现双数据中心数据同步, 同时从业务层面实现数据读写分离,冷热查询分离。部署情况见图 2 所示:
 图 2. Elastic Search 双数据中心部署效果
图 2. Elastic Search 双数据中心部署效果
性能表现
目前新网银行有 2 个 Elastic Search 数据中心,每个数据中心各自有 3 台物理机。通过在线上观察和验证测试,X-CCR 工具可以确保在主分片写入 TPS=50000/s 下,75%的数 据在 2s 内,实现数据相互可见。相关的统计数据见图 3:
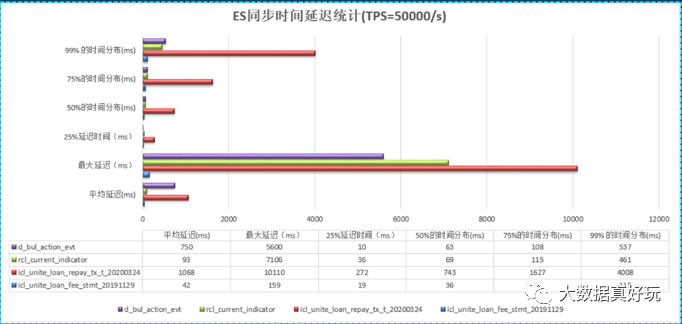
图 3. Translog解析同步工具X-CCR 工具性能测试
总结
本文介绍了新网银行在Elastic Search双数据中心建设上的实践。目前,已经完成了第一个版本的建设,从功能上和性能上满足了业务需求,但还需更加完善;后期打算将其与Elastic Search 插件集成,方便部署和管理。

Apache Iceberg技术调研&在各大公司的实践应用大总结
Apache Spark 3.0 自适应查询优化在网易的深度实践及改进