
今天,我被二维码卷到了...





-
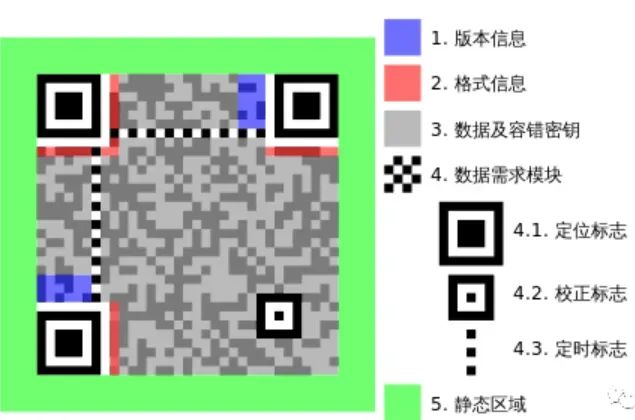
根据三个定位图案检测以及“摆正”二维码。 -
将二维码区域转换为灰度图,切分成不重叠的区块,每个区块内单独计算得到一个阈值,高于阈值的为1,小于阈值的为0。 -
根据一定的规则,从读取的一串010110...数据流中解码得到信息。二维码的编码有一定的冗余,数据流中偶然几位的0,1被搞混也不会影响解码。
-
依然包含关键的三个定位图案。 -
定位图案包围的数据区域有明显的亮暗关系变化,可以被解码为0,1数据流。 -
数据流中被扰乱的0,1比特还没有那么多,还能被冗余信息恢复。





Tony Stark, bruise wounded, wet soaked, water splash, torn apart, ripped clothes, random background vintage, neons lights, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, hyperdetailed, intricately detailed, unreal engine, fantastical, ideal human, high quality, film grain, bokeh, Fujifilm XT3, hyper realisticNegative prompt: ugly, disfigured, low quality, blurry, nsfwSteps: 50, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 3724036266, Size: 768x768, Model hash: 4199bcdd14, Model: revAnimated_v122, Denoising strength: 0.85, Mask blur: 4, ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.8, starting/ending: (0.23, 0.9), resize mode: Just Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"
ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.8, starting/ending: (0.23, 0.9), resize mode: Just Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"





futobot, cyborg, ((masterpiece),(best quality),(ultra-detailed), (full body:1.2), 1 female, solo, hood up, upper body, mask, 1 girl, female focus, black gloves, cloak, long sleevesNegative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples, (((necklace))), (worst quality, low quality:1.2), watermark, username, signature, text, multiple breasts, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, single color, ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), (((tranny))), (((trans))), (((trannsexual))), (hermaphrodite), extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), (((disfigured))), (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), (missing legs), (((extra arms))), (((extra legs))), mutated hands,(fused fingers), (too many fingers), (((long neck))), (bad body perspect:1.1)Steps: 60, Sampler: DPM++ 2M Karras, CFG scale: 11, Seed: 2912497446, Size: 768x768, Model hash: ed4f26c284, Model: camelliamix25D_v2, Denoising strength: 1, Mask blur: 4, ControlNet 0: "preprocessor: openpose_full, model: control_sd15_openpose [fef5e48e], weight: 1, starting/ending: (0, 1), resize mode: Resize and Fill, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)", ControlNet 1: "preprocessor: tile_resample, model: control_v11f1e_sd15_tile [a371b31b], weight: 0.75, starting/ending: (0.23, 1), resize mode: Resize and Fill, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 1, 64)"









评论