
2020最新文本检测算法TextFuseNet

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
TextFuseNet: Scene Text Detection with Richer Fused Features
自然场景中任意形状文本检测是一项极具挑战性的任务,与现有的仅基于有限特征表示感知文本的文本检测方法不同,本文提出了一种新的框架,即 TextFuseNet ,以利用融合的更丰富的特征进行文本检测。
该算法用三个层次的特征来表示文本,字符、单词和全局级别,然后引入一种新的文本融合技术融合这些特征,来帮助实现鲁棒的任意文本检测。另外提出了一个弱监督学习机制,可以生成字符级别的标注,在缺乏字符级注释的数据集情况下也可以进行训练。
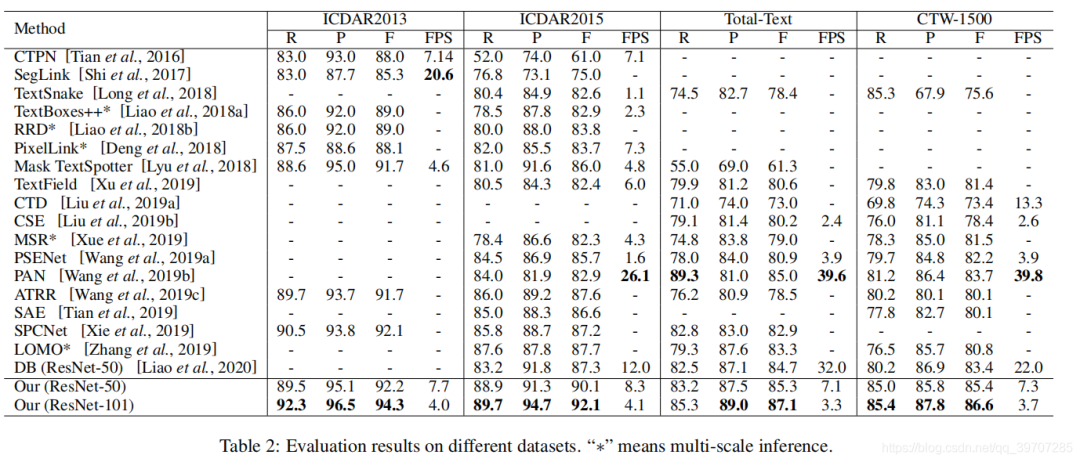
该算法在ICDAR2013上取得F1分数94.3%,在ICDAR2015上F1分数92.1%,在Total-Text上87.1%,在CTW-1500上86.6%,目前为止最佳成绩。
复现代码 获取:
关注微信公众号 datayx 然后回复 文本检测 即可获取。
AI项目体验地址 https://loveai.tech
1. 算法简介
之前的文本检测算法大致分为两种,基于字符级别的检测和基于单词级别的检测。基于字符级别的检测算法首先提取单个字符,然后再使用字符合并算法合并这些字符成一个单词,然而这种方法因为要生成大量的字符候选框并且要合并,比较耗时。相比之下,基于单词级别的检测算法直接检测单词,会更高效和简单,但这种方法通常无法有效地检测具有任意形状的文本。为了解决这个问题,一些基于单词的方法进一步应用实例分割来进行文本检测。在这些方法中,前景分割掩码被估计以帮助确定各种文本形状。
尽管有很好的结果,但现有的基于实例分割的方法仍然有两个主要的局限性。一是,这些方法只基于单个感兴趣区域(RoI)检测文本,而不考虑全局上下文,因此它们倾向于基于有限的视觉信息产生不准确的检测结果。二是,现有的方法没有对不同层次的单词语义进行建模,产生假阳性的可能性增大。从图一中可以看到这种方法的弊端。

本文提出的TextFuseNet能够有效的解决这些问题,并且可以高效准确的预测任意形状的文本。TextFuseNet与其他算法相比主要的区别在于,有效的利用各种层次的特征,例如字符级别的、单词级别的、全局级别的特征,而其他的文本检测算法往往只使用一种层次的特征。
TextFuseNet网络结构主要分为三个分支:
第一个是语义分割分支( semantic segmentation branch),该分支用来提取液全局级别的特征;
另外二个是检测分支和mask分支(detection and mask branches),用来提取字符级别和单词级别的特征;
在得到三种层次的特征后,使用多路径特征融合体系结构(Multi-path Fusion Architecture),融合三者特征,生成更具代表性的特征表示,从而产生更准确的文本检测结果。
目前大部分数据集只包含单词级别的标注,很少有字符级别的标注,为解决字符级别标注数据集缺乏的问题,提出了一种弱监督学习方案,通过从单词级注释数据集学习来生成字符级注释。
总体的结构如图2所示。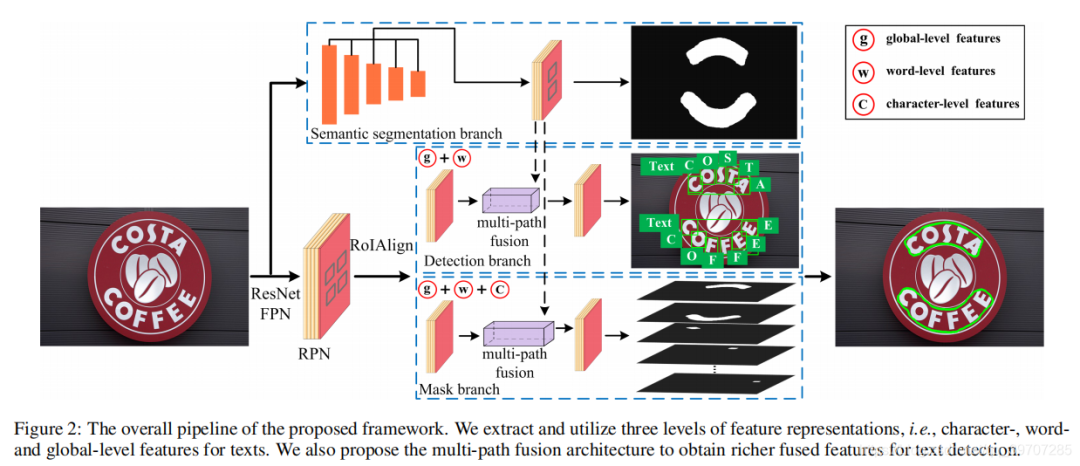
2. 算法详解
2.1 网络结构
具体网络结构如图2所示,首先提取多层次的特征,然后执行多路径融合以进行文本检测。该结构主要由5部分组成,
使用特征金字塔(FPN)作为backbone进行多特征提取;
使用RPN生成文本候选框;
语义分割分支生成全局语义特征;
检测分支预测单词和字符;
mask分支生成单词和字符的实例分割;
在TextFuseNet中,使用ResNet作为backbone,RPN生成的文本候选框作为检测和mask分支的输入,在语义分割分支来对输入图像进行语义分割,并帮助获得全局级别的特征。
mask在检测分支中,通过预测文本候选框的类别和采用边界框回归来细化文本候选框,提取和融合了单词和全局级别的特征来检测单词和字符。
mask分支,对从检测分支检测到的对象执行实例分割;
提取和融合所有字符、单词和全局级别的特征,以完成实例分割以及最后的文本检测任务。
2.2节来主要来讲解提取多层次的特征表示,在提取多特征后,多路径融合体系结构来融合不同的特征,用于检测任意形状的文本,多径融合体系结构可以有效地对多层特征进行对齐和合并,以提供健壮的文本检测,多路径融合体系结构的实现细节在2.3节中描述。
2.2 Multi-level Feature Representation
在检测器的检测和掩码分支中,通过预测文本候选框中的字符和单词,能够很容易的获得字符级别和单词级别的特征。这里应用RoIAlign提取不同的特征,并对单词和字符进行检测。
除了字符和单词特征,还要获取全局的语义特征,如图2所示,语义分割分支是基于FPN的输出构建的。将所有特征层的特征融合到一个统一的特征表示中,并在这个统一的特征表示上执行分割,从而获得全局分段的文本检测结果。通常,使用1×1的卷积将不同特征层的特征的通道数对齐,并将特征映射调整为相同的大小,以便以后统一。
2.3 Multi-path Fusion Architecture
在获取到多级特征后,分别在检测和mask分支采用多径融合体系结构。
在检测分支中,基于从RPN获得的文本候选,提取全局和单词级特征,用于不同路径的文本检测。然后,融合这两种类型的特征,以单词和字符的形式提供文本检测。值得注意的是,在检测分支的时候,不能提取和融合字符级别的特征,因为,在执行检测之前,字符尚未被识别。在实际代码中,给定一个文本候选框,使用RoIAlign从FPN的输出特征中提取到一个大小为7×7的全局和单词特征。使用 element-wise相加融合这两个特征,然后再经过一个3×3的卷积层和一个1×1的卷积层,最终融合后的特征用于分类和坐标回归。
在mask分支,对于每个单词级实例,可以在多路径融合体系结构中融合得到相应的字符、单词和全局级别特征。图3详细说明了多路径融合结构。
在所提出的体系结构中,从不同的路径中提取多层次特征,并将它们融合起来,以获得更丰富的特征,以帮助学习更具鉴别性的特征表示。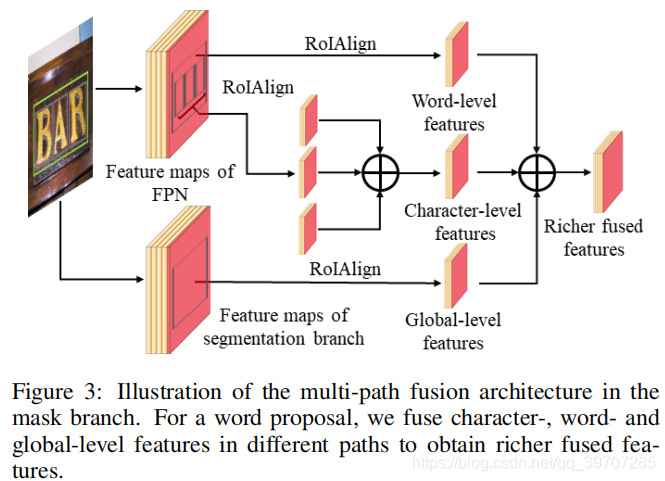


通过进一步应用RoIAlign提取单词的特征和相应的全局语义特征,通过element-wise求和将这三个层次的特征融合起来,然后通过一个3×3卷积层和一个1×1卷积层去获得更丰富的特征。最后融合的特征用于实例分割。
3.4 loss函数


4. 测试结果
原文地址https://blog.csdn.net/qq_39707285/article/details/113046449
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码