
祖传代码的重构体验
作者:代一鸣
链接:https://www.jianshu.com/p/fe0024e6c1b8
声明:本文是 代一鸣 原创,转发等请联系原作者授权。
背景
相信很多同学对于祖传代码都有极其恐怖的体验,不改他难以维护、难以支撑新业务,改了又会冒出一堆莫名其妙的 bug,而且,当这些代码以模块的形式大量的出现在工程中时,估计想死的心都有了。
凑巧的是,在我们的项目里就充斥着这样的代码,在我接手这个项目的时候这个项目已经传了4代了,并且第一代写这个项目的程序员不是写 Android 的,他们写的很多代码还仍被当做核心模块留在工程中,可能也是前几代开发者对祖传代码充满恐惧,所以一有新业务就仅是在其基础上不断添加代码,从而导致项目越来越臃肿,很多模块都难以读懂。
因为我是一个对代码有洁癖的人,并且在项目正常维护(开发新内容、bugfix)的时候,这些祖传代码已经难以再支撑下去,于是当我负责 Android 端整个项目的时候,我就决定大刀阔斧的对这些内容进行整体的重构,也是为后来想在项目中做出更多创新打下基础。
分享一个模块的重构 - 数据库模块
因为我们项目的特殊性,大量的用户数据都被存储在本地的 SQLite 数据库中,所以数据库模块成为了我们重点维护的核心模块,这次分享也以这个模块的重构为基础。
老数据库模块存在的问题:
一. 数据库表结构设计混乱
用户主要在我们的项目中通过做任务去获取奖励,任务有多个类型,用户所做的任务都会存储在数据库中等待上传,因为数据库的结构设计问题(也可能是前几代同学在合作的时候没有沟通好),导致出现了任务1、2、3存储在表1,任务4存储在表2,任务5存储在表3的情况(如下图),并且因为 SQLite 不支持字段删除,很多表的字段数多达 20 多个。
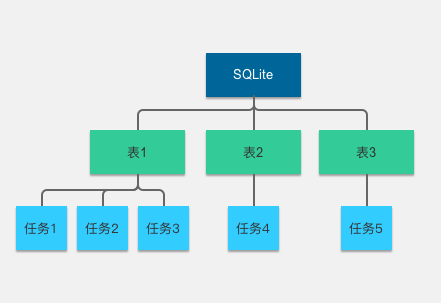
任务存储方式.png
二. 数据库操作框架 bug
我们项目中之前一直使用的是 OrmLite 框架进行数据库操作,这个框架提供了很好的数据库管理模式,带来了很大的方便,但是却存在一个致命问题就是数据库并行操作会导致 Crash(好像作者已经不维护这个框架了…),虽然并发在客户端上并不是很高频,但是在我们的项目中确实存在很多这样的情况,如用户边后台上传任务边编辑任务等。
三. 数据库操作层代码混乱
原数据库模块在 OrmLite 框架的基础上,针对每张表封装了 Table 类进行数据库操作,再在 Table 层下封装了 Service 层对外暴露静态接口方便调用,虽然这个设计看起来很好,也有分层的概念,但是还是存在几个问题:
因为表 1 中存储了多个任务,导致表 1 对应的 Table 类代码爆炸,达到了几千行;
Service 层仅作为方便调用的中转,“工作量” 不够,且徒增代码量;
Table 层每个接口做的事情不够 “单一”,掺杂了业务逻辑在里面,众多接口不方便复用。
重构方案
一. 重新设计模块结构
通过对业务的分析,每个数据库操作实际都是对应每一种 “任务” 的查询操作,所以每种 "任务" 是我们需要直接面向的对象,而不应该是真实的数据库表,并且真实的数据库表可能包含多种任务类型,如果直接对表进行操作,就会出现一张表对应的 Table 类里出现多个任务的业务逻辑代码,于是基于这个思路重新设计模块结构,如下图:

模块结构设计图.png
基本的设计思路是:
既然数据表没有很好的对任务进行划分,那我们就抽象一个虚拟的任务表层出来,每个任务表只负责自己对应任务的数据库操作,并把真实的数据表层 Abstract 化,只对外暴露我们任务表,这样我们之后就只需要关心对应任务的操作了,每个任务的 Table 类也不会代码量膨胀,便于维护。可能会有同学疑问为什么不直接对数据库结构进行调整,主要是因为代价太大,需要用户强制升级,并大量迁移数据,当然这一步在后续合适的时机也一定是回去做的。
对于虚拟的任务 Table 类的每个接口,我们只提供最基本的增、删、改、查操作,事务操作转由 Helper 层提供, 这样便于 Helper 层针对不同的业务逻辑来组合这些接口,达到代码复用,并且因为单条查询粒度较小,对于数据库并发框架提供的读写锁来说,可以提升很大的效率。
Helper 层则通过 AbstractHelper 基类向下层提供的数据库并发处理框架和虚拟任务表单例,针对不同的业务提供接口,对于需要“跨表”(这里也包括跨虚拟任务表,虽然它们实际在一张真实表里)的操作,提供 UnionQueryHelper 工具类来组合各 TaskHelper 提供查询,这样做到模块间代码界限清晰,不至于随着后面的不断维护,各个 Helper 层之间代码界限又变的混乱不堪。
整体来说,就是抽象出一个虚拟表层来表示每种任务表,彻底将混乱不堪的 SQLite 的真实表层彻底屏蔽掉。
二. 解决数据库框架的 bug
值得庆幸的是老的数据库框架采用了分层的思想,不管分层做的好不好,但是对在日常需求开发中穿插的代码重构来说,确实节省了很多的时间, 在解决并发问题的时候我们就是在原 Table 层上添加一层并发处理层,很快的解决了这个问题并融合到将要发版的版本进行正常发版。
之前的同学就是在这个基础上提供了一个解决并发问题的小框架,借鉴了一些成熟框架的思想,采用了任务队列的方式,虽然解决了并发问题,但是并不十分适合我们的实际场景,也引入了一些其他的bug,比如对于用户大量的任务数据,当我们进行全量读取的时候,会消耗大量的时间,此时其他的任何数据库操作都需要等待,效率比较低。
针对客户端并发量低、读操作多、操作耗时基本较端的特性,我认为依靠读写锁进行数据库并发限制就可以很好的解决问题,并且执行效率较高,也便于维护,并发操作限制中转层代码如下:
/**
* 提供给所有 Helper 子类使用的数据库表操作加锁工具类,不对外暴露
*/
protected object Executor {
const val INSERT = 0L
const val DELETE = 1L
const val UPDATE = 2L
const val QUERY = 3L
private const val TRANSACTION = 4L
private val mLock = ReentrantReadWriteLock()
@IntDef(INSERT, DELETE, UPDATE, QUERY, TRANSACTION)
@Retention(AnnotationRetention.SOURCE)
annotation class ActionType
class TransactionResult<out T_DATA>(val success: Boolean, val data: T_DATA)
fun transaction(action: () -> Unit, catcher: ((Exception) -> Unit)? = null): Boolean {
var success = true
val lock = getAdaptiveLock(TRANSACTION)
lock.lock()
try {
LocalDatabase.instance.inTransaction { action() }
} catch (e: Exception) {
handleException(e, catcher)
success = false
} finally {
lock.unlock()
}
return success
}
fun transactionResult(action: () -> T_RESULT, defaultVal: T_RESULT): TransactionResult {
return transactionResult(action, null, defaultVal)
}
fun transactionResult(action: () -> T_RESULT,
catcher: ((Exception) -> Unit)? = null, defaultVal: T_RESULT): TransactionResult {
var success = true
val resultHolder = arrayOfNulls(1).apply { this@apply[0] = defaultVal }
val lock = getAdaptiveLock(TRANSACTION)
lock.lock()
try {
LocalDatabase.instance.inTransaction { resultHolder[0] = action() }
} catch (e: Exception) {
handleException(e, catcher)
success = false
} finally {
lock.unlock()
}
@Suppress("UNCHECKED_CAST")
return TransactionResult(success, resultHolder[0] as T_RESULT)
}
fun execute(@ActionType actionType: Long, action: () -> Unit,
catcher: ((Exception) -> Unit)? = null) {
val lock = getAdaptiveLock(actionType)
lock.lock()
try {
action()
} catch (e: Exception) {
handleException(e, catcher)
} finally {
lock.unlock()
}
}
fun executeResult(@ActionType actionType: Long,
action: () -> T_RESULT, defaultVal: T_RESULT): T_RESULT {
return executeResult(actionType, action, null, defaultVal)
}
fun executeResult(@ActionType actionType: Long,
action: () -> T_RESULT,
catcher: ((Exception) -> Unit)?, defaultVal: T_RESULT): T_RESULT {
var result = defaultVal
val lock = getAdaptiveLock(actionType)
lock.lock()
try {
result = action()
} catch (e: Exception) {
handleException(e, catcher)
} finally {
lock.unlock()
}
return result
}
private fun getAdaptiveLock(@ActionType actionType: Long): Lock =
if (actionType == QUERY) mLock.readLock() else mLock.writeLock()
private fun handleException(ex: Exception, catcher: ((Exception) -> Unit)?) {
if (BuildConfig.DEBUG) {
throw ex
}
CrabSDK.uploadException(ex)
catcher?.invoke(ex)
}
}
使用过程可以参考如下:
fun getAllData() =
Executor.executeResult(Executor.QUERY, Table.Task1Table::getAllData, safeEmptyList())
不用调整原先工程中对 Service 层和 Table 层的调用,就可以将并发控制层插入,使用也很方便,安全性也都有保证。
总结
对于这些不是很好的祖传代码,如果有机会我认为一定是要改一改,一是对自己的提升,二也是降低日后维护的成本,便于开发,虽然可能带来一些问题,但是问题总是可以解决的。即使不能重构,我觉得也可以在其上层封装一层,彻底屏蔽它的实现,日后的维护过程中就可以再也不用关心它了,并且有机会的时候也可以利用这层中转的便利性直接把它替换掉。