处理非均衡数据的7种技术
共 2353字,需浏览 5分钟
·
2022-12-22 06:24
作者:Ye Wu、Rick Radewagen
翻译:陈之炎
校对:赵茹萱
诸如银行的欺诈检测、营销的实时竞价或网络的入侵检测等领域的数据集都有哪些共同点?
在这些领域的数据通常只占有总数据量不到1%,为罕见但“有趣的”事件(例如,骗子使用信用卡、用户点击广告或入侵服务器扫描其网络)。然而,绝大多数机器学习算法并不能很好地处理这些非均衡的数据集。利用以下七种技术可以通过训练一个分类器来检测出上述异常类。

1. 使用正确的评估指标
对于那些使用非均衡数据的模型来说,应用不恰当的评估度量指标非常危险。想象一下,假设训练数据如上图所示,如果用准确率来衡量一个模型的好坏,那么将所有测试样本分类为“0”的模型将具有极好的准确率(99.8%),显然,这个模型不会提供任何有价值的信息。
在这种情况下,可以采用其他评估指标,例如:
精度/特异性:有多少选定实例是相关的。
召回率/敏感度:选择了多少个相关的实例。
F1评分:精度和查全率的调和平均值。
MCC:观察到的和预测到的二元分类之间的相关系数。
AUC:真阳性率与假阳性率之间的关系。
2. 重新采样训练集
除了使用不同的评估标准外,还可以采取一定的措施以获取到其他不同的数据集,通常利用欠采样和过采样两种方法从非均衡数据集中提取出均衡数据集。
2.1 欠采样
通过减少不同类的大小来平衡数据集的过程称为欠采样,当数据量充足时,使用该方法。通过将所有样本保留到稀有类中,并在不同类中随机选择相同数量的样本,在后续建模过程中便可以检索到一个新的均衡数据集。
2.2 过采样
相反,当数据量不足时,则使用过采样。过采样通过增加稀有样本的大小来平衡数据集。在不去除大量的样本的情况下,通过使用重复、引导或SMOTE(合成少数过采样技术)[1]来生成新的稀有样本。
请注意,以上两种重采样方法并没有各自绝对的优势,这两种方法的应用取决于用例和数据集本身,过采样和欠采样两种方法的组合往往也能成功。
3. 正确使用k倍交叉验证
值得注意的是,在使用过采样的方法来解决非均衡数据问题时,可以适当地应用交叉验证。
请记住,过采样观察到的是稀有样本,并利用自举法根据分布函数生成新的随机数据。如果在过采样后应用交叉验证,便会将模型过拟合到一个特定的人工自举结果中。这就是为什么应该在过采样数据之前进行交叉验证,正如应该在实现特征之前对特征做出选择一样,只有通过重复采样数据,方可在数据集中引入随机性,确保不会出现过拟合问题。
4. 集成不同的重采样数据集
成功泛化模型的最简单方法是使用更多的数据。像逻辑回归或随机森林等开箱即用的分类器倾向于通过丢弃稀有类来实现泛化。一个简单而有效的实践是针对稀有类的所有样本和多数类的n个不同样本,建立n个模型。假设需要集成10个模型,保留例如1.000个稀有类的案例,并随机抽取10.000个多数类的案例,然后把10.000个多数类分成10块,训练10个不同的模型。
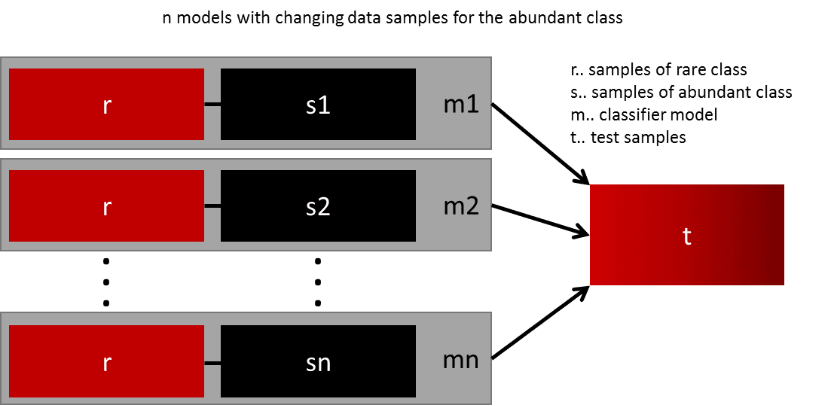
如果存在大量的数据,那么这种方法非常简单,并且完全可水平扩展,可以在不同的集群节点上训练和运行模型。集成模型也可更好地泛化,这种方法非常易于处理。
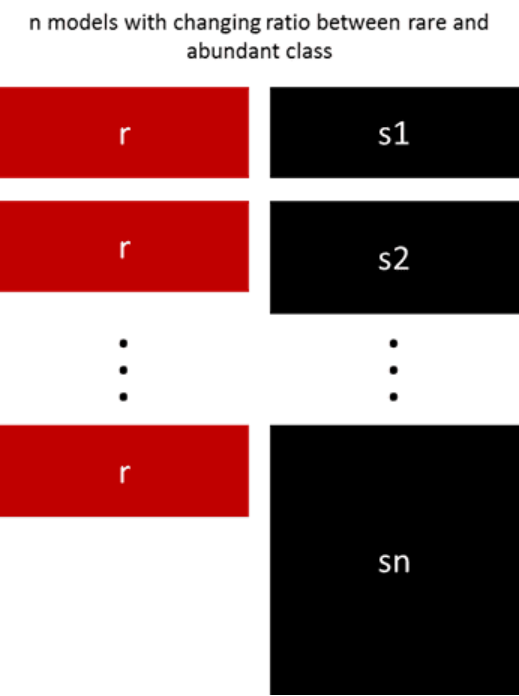
5. 按照不同的比例重新采样
通过调整稀有类和多数类之间的比例,利用前文所述的几种方法来进行微调。两种类数目的最佳配比在很大程度上取决于数据本身和所使用的模型。
与其以相同的比例训练所有的模型,还不如尝试以不同比例集成数据。如果训练了10个模型,那么比例为1:1(稀有:多数)和比例为1:3,甚至是2:1的模型均可能都是有意义的,类的权重取决于所使用的模型。
6. 聚类多数类
Quora [2]的Sergey提出了一种更加优雅的方法,他建议将多数类聚类到r组中,r即r组中的案例数, 取代随机样本来覆盖训练样本的多样性。对于每一组,只保留medoid(聚类的中值),然后用稀有类和medoids对模型进行训练。
7. 设计自定义模型
前文所述的方法关注的是数据,将模型视为一个固定的组件。但事实上,如果模型本身适用于非均衡的数据,就无需对数据进行重新采样。如果类没有太多的倾斜, XGBoost便很好用了,因为其内部已经关注了袋子里的不均衡数据。但话说回来,这也只是在秘密的情况之下,对数据重新采样。
通过设计一个成本函数,对稀有类的错误分类进行惩罚,而不是对多数类的错误分类进行惩罚,有可能设计出许多有利于稀有类泛化的模型。例如,配置一个SVM,以惩罚稀有类的错误分类。
小结
本文的内容并非唯一的技术列表,只是处理非均衡数据的一个起点。也不存在能解决所有问题的最佳方法或模型,强烈建议尝试不同的技术和模型来评估哪种方法最为有效,可以尝试有创意地将多种方法结合起来使用。同样需要注意的是,在欺诈检测、实时竞价等诸多领域,当非均衡类别发生的同时,“市场规则”也在不断变化。因此,需要检查过往的数据是否已经过时了。
参考文献
作者简介
Ye Wu :FARFETCH高级数据分析师,她有会计背景、市场营销和销售预测方面的实践经验。
Rick Radewagen :Sled的联合创始人,有计算机科学背景的、有抱负的数据科学家。
原文标题:
7 Techniques to Handle Imbalanced Data
原文链接:
https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html