
ECCV2020 | RecoNet:上下文信息捕获新方法,比non-local计算成本低100倍以上
共 4015字,需浏览 9分钟
·
2020-08-15 23:47
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

这篇文章收录于ECCV2020,主要是有关语义分割算法中的上下文信息重建方法,本文中同时考虑了通道维和空间维,可以看作是视觉注意力机制的优化与应用。思想其实和CCNet、CVPR2020的条纹池化Strip Pooling相似,这篇可以看作是他们的抽象。
论文地址:https://arxiv.org/abs/2008.00490
代码地址:https://github.com/CWanli/RecoNet
上下文信息在语义分割的成功中起着不可或缺的作用。事实证明,基于non-local的self-attention的方法对于上下文信息收集是有效的。由于所需的上下文包含空间和通道方面的注意力信息,因此3D表示法是一种合适的表达方式。但是,这些non-local方法是基于2D相似度矩阵来描述3D上下文信息的,其中空间压缩可能会导致丢失通道方面的注意力。另一种选择是直接对上下文信息建模而不进行压缩。但是,这种方案面临一个根本的困难,即上下文信息的高阶属性。本文提出了一种新的建模3D上下文信息的方法,该方法不仅避免了空间压缩,而且解决了高阶难度。受张量正则-多态分解理论(即高阶张量可以表示为1级张量的组合)的启发,本文设计了一个从低秩空间到高秩空间的上下文重建框架(即RecoNet)。具体来说,首先介绍张量生成模块(TGM),该模块生成许多1级张量以捕获上下文特征片段。然后,使用这些1张量通过张量重构模块(TRM)恢复高阶上下文特征。大量实验表明,本文的方法在各种公共数据集上都达到了SOTA。此外,与传统的non-local的方法相比,本文提出的方法的计算成本要低100倍以上。
简介
语义分割的目的是为给定的图像分配像素级的预测,这是一个具有挑战性的任务,需要精细的形状、纹理和类别识别。语义分割中的开创性工作完全卷积网络(FCN),探索了深度卷积网络在分割任务中的有效性。
最近,更多的工作从探索上下文信息方面取得了很大的进展,其中基于非局部non-local的方法是最近的主流,这些方法通过对上下文特征的重要性进行评级排序来模拟上下文表示。然而,这样得到的上下文特征缺乏通道维度的重要性,而通道维是上下文的关键组成部分。具体来说,对于一个典型的非局部区块,由两个输入维度分别为H×W×C和C×H×W的矩阵相乘生成二维相似度图。值得注意的是,在乘法过程中,通道维度C被消除,这意味着只表示空间上的注意力,而通道上的注意力被压缩。因此,这些基于非局部non-local的方法可以收集细粒度的空间上下文特征,但可能会牺牲通道维度的上下文注意力。
解决此问题的一个直观想法是直接构造上下文,而不是使用2D相似度图。不幸的是,由于上下文特征的high-rank高阶属性,该方法面临着根本的困难。也就是说,上下文张量应该具有足够的容量,因为上下文因图像而异,并且这种大的多样性并不能由非常有限的参数来进行表示。
启发于tensor canonical-polyadic decomposition理论,高阶张量可以表示为rank-1张量的组合,因此本文提出了一种新的方法,即以渐进的方式对高阶上下文信息进行建模,而无需进行通道维的空间压缩。在图1中展示了非局部non-local网络和RecoNet的工作流程,其基本思路是先用一系列低阶时序器来收集上下文特征的部分信息,然后将它们组合起来,重建精细的上下文特征。具体来说,本文提出的框架由两个关键部分组成,rank-1张量生成模块(TGM)和高阶张量重构模块(TRM)。在这里,TGM的目的是在通道、高度和宽度方向上生成rank-1的张量,以低阶约束探索不同视图中的上下文特征。TRM采用tensor canonical-polyadic(CP)重构来重建高阶注意力图谱,其中基于不同视图的rank-1张量挖掘共现co-occurrence上下文信息。在这两部分的配合下,实现了高效的高阶上下文建模。
在五个公共数据集上测试了本文的方法。在这些实验中,所提出的方法始终达到最新SOTA水平,特别是对于PASCAL-VOC12数据集,RecoNet达到了top-1的性能。此外,与其他基于non-local的上下文建模方法相比,通过合并简洁的低秩特征,使得整个模型的计算量更少(比non-local低100倍以上)。
张量分解
根据张量分解理论,张量可以由一系列低秩张量的线性组合表示。这些低秩张量的重建结果是原始张量的主要成分。因此,张量的低秩表示被广泛用于计算机视觉任务中,例如卷积加速和模型压缩。有两种张量分解方法:Tuker分解和CP分解。对于Tuker分解,将张量分解为一组矩阵和一个核心张量。如果核心张量是对角线,那么Tuker分解将退化为CP分解。对于CP分解,张量由一组rank-1的张量(向量)表示。在本文中,将这种理论应用于重构,即从一组rank-1的上下文片段信息中重构高rank的上下文张量。
本文方法
从图像进行的语义信息预测与上下文信息密切相关。由于上下文的种类繁多,因此需要使用高阶张量来表示上下文特征。然而,在这种约束下,对上下文特征进行建模直接意味着巨大的成本。受CP分解理论的启发,尽管上下文预测是一个高阶问题,但可以将其分为一系列低阶问题,这些低阶问题更易于处理。具体来说,不会直接预测上下文特征,而是会生成其片段。然后,使用这些片段构建一个完整的上下文特征。从低阶到高阶的重建策略不仅可以维持3D表示(在通道方面和在空间方面),而且还可以解决高阶表示难度的问题。
本文的模型的流程如图2所示,由低阶张量生成模块(TGM),高阶张量重构模块(TRM)和全局池化模块(GPM)组成,以在空间和通道维度上获取全局上下文。在语义标签预测之前,使用双线性插值对模型输出进行上采样。在具体的实现中,使用多个低秩感知器来处理高秩问题,通过该问题可以学习部分上下文信息(即上下文片段)。然后,通过张量重构理论构建高秩张量。
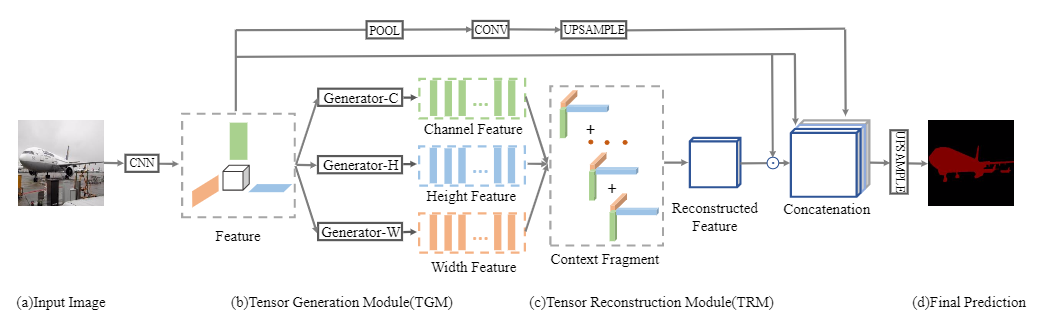
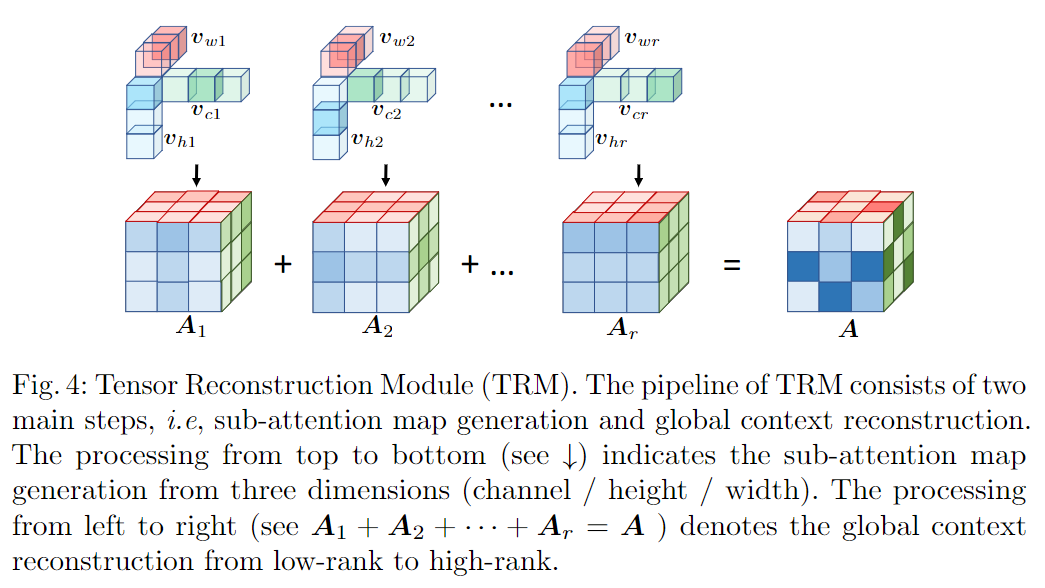
图2. 框架的流程,主要涉及两个部分,即张量生成模块(TGM)和张量重建模块(TRM)。TGM执行低阶张量生成,而TRM通过CP构造理论实现高阶张量重建。
1、 Tensor Generation Module
Context Fragments.上下文片段定义为张量生成模块的输出,该片段表示通道,高度和宽度方向上的一些rank-1向量。每个上下文片段都包含一部分上下文信息。
Feature Generator.定义了三个特征生成器:通道生成器,高度生成器和宽度生成器。每个生成器由Pool-Conv-Sigmoid序列组成。全局池化在以前的工作中作为全局上下文收集方法被广泛使用。同样,这里在特征生成器中使用全局平均池,以C / H / W方向获得全局上下文表示。
Context Fragments Generation.为了学习跨越三个方向的上下文信息片段,网络在输入特征的基础上应用通道、高度和宽度发生器,并重复这个过程r次,得到3r个可学习向量。所有向量都是使用独立的卷积核生成的,它们各自学习一部分上下文信息,并作为上下文片段输出。TGM结构如图3所示。
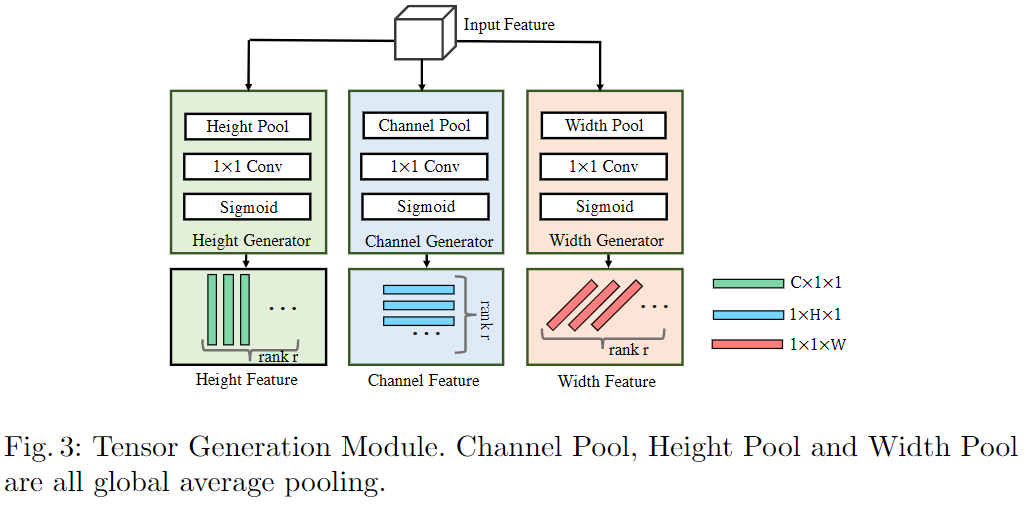
Non-linearity in TGM.回顾TGM生成3r个rank-1张量,并且这些张量由Sigmoid函数激活,该函数将上下文片段中的值重新缩放为[0,1]。添加非线性激活函数有两个原因:首先,每个重新标定的元素都可以看作是满足关注定义的某种上下文特征的权重。其次,所有上下文片段都不应是线性相关的,以便它们中的每一个都可以代表不同的信息。
2、Tensor Reconstruction Module
Context Aggregation(特征聚合过程)
与以前的只收集空间或通道注意力的方法不同,本文的方法同时收集了两个方向的注意力分布。TRM的目标是获得在空间和通道注意力方面都保持响应的3D注意图A∈C×H×W。之后,通过逐元素乘积获得上下文特征。具体而言,给定输入特征X和上下文注意图,细粒度的上下文特征Y由下式给出:
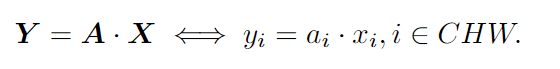
Low-rank Reconstruction(低秩重建)
张量重构模块(TRM)解决了上下文特征的高阶高级属性。TRM的完整工作流程如图4所示,它包括两个步骤,即子注意力图聚合和全局上下文特征重构。首先,将三个上下文片段合成为rank-1的子注意图A1,该子注意图表示3D上下文特征的一部分。然后,按照相同的过程重构其他上下文片段。之后,使用加权均值汇总这些子注意图:
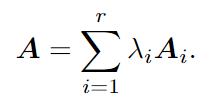
λi∈(0,1)是可学习的归一化因子。尽管每个子注意图都表示低秩上下文信息,但是它们的组合成为高秩张量。
3、 Global Pooling Module
全局池模块(GPM)由全局平均池化操作和1×1卷积组成,它在空间和通道维度上都收集全局上下文。在本文提出的模型中,将GPM应用于网络性能的进一步提升。
4、网络细节
使用ResNet 作为主干网络,并在其Res-4和Res-5的输出中应用空洞卷积,使得网络的输出分辨率为原图大小的1/8。Res-5块的输出特征标记为X,然后将TGM + TRM和GPM添加到X的顶部。并在Res-4块之后也使用了辅助损失,将权重α设置为0.2。
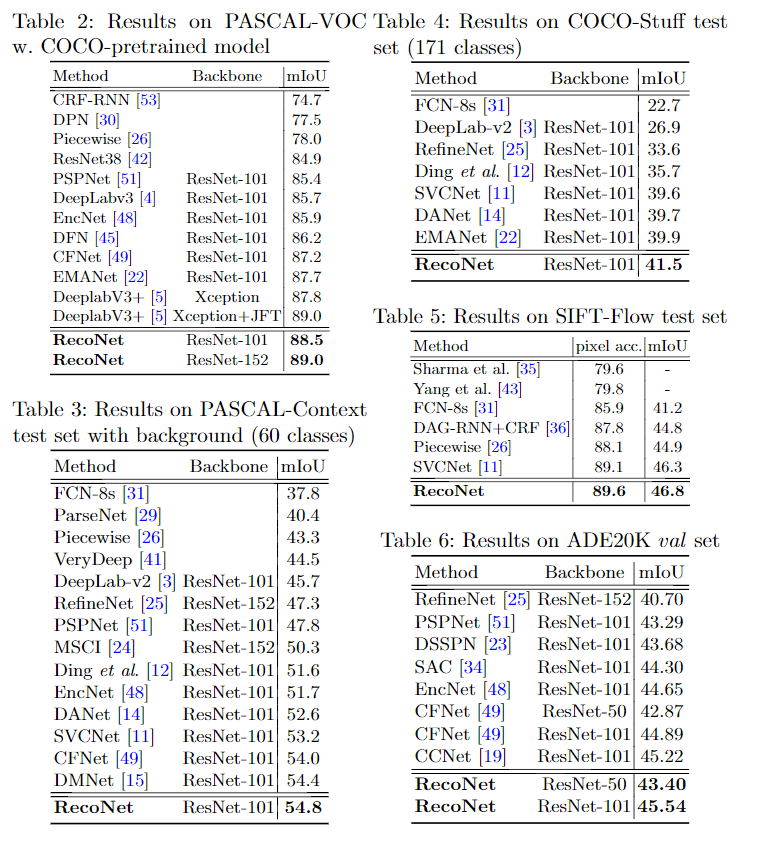
数据集: PASCAL-VOC12, PASCAL-Context, COCO-Stuff, ADE20K ,SIFT-FLOW
对比实验:
消融实验

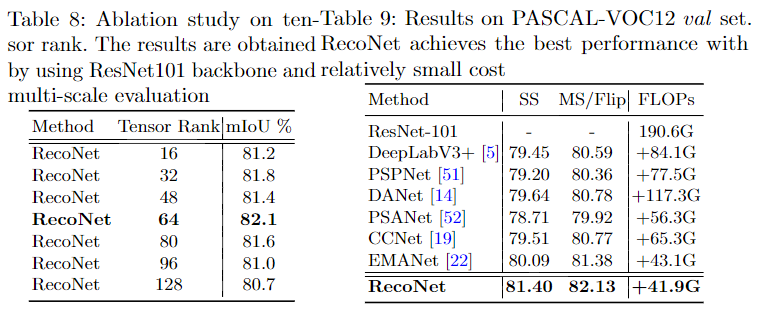
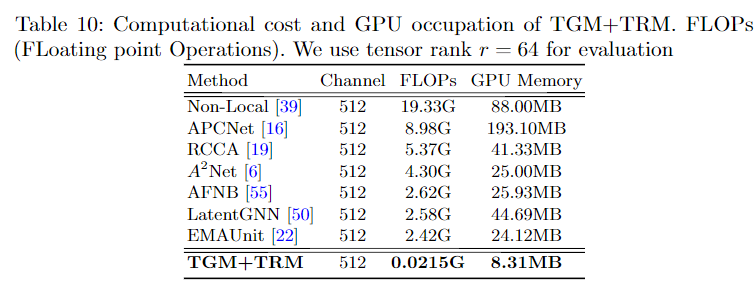
参数量对比
可视化对比


更多细节可参考论文原文。
