
数据治理之元数据管理的利器——Atlas入门宝典(万字长文)
共 17131字,需浏览 35分钟
·
2021-12-12 22:47
本文档基于Atlas2.1.0版本,整理自部分官网内容,各种博客及实践过程。文章较长,建议收藏。
正文共: 17003字
预计阅读时间: 43分钟
本文档共分为8个部分,层级结构如下图所示。
文档版权为公众号 大数据流动 所有,请勿商用。相关技术问题以及安装包可以联系笔者独孤风加入相关技术交流群讨论获取。
一、数据治理与元数据管理
背景
为什么要做数据治理?业务繁多,数据繁多,业务数据不断迭代。人员流动,文档不全,逻辑不清楚,对于数据很难直观理解,后期很难维护。
在大数据研发中,原始数据就有着非常多的数据库,数据表。
而经过数据的聚合以后,又会有很多的维度表。
近几年来数据的量级在疯狂的增长,由此带来了系列的问题。作为对人工智能团队的数据支撑,我们听到的最多的质疑是 “正确的数据集”,他们需要正确的数据用于他们的分析。我们开始意识到,虽然我们构建了高度可扩展的数据存储,实时计算等等能力,但是我们的团队仍然在浪费时间寻找合适的数据集来进行分析。
也就是我们缺乏对数据资产的管理。事实上,有很多公司都提供了开源的解决方案来解决上述问题,这也就是数据发现与元数据管理工具。
元数据管理
简单地说,元数据管理是为了对数据资产进行有效的组织。它使用元数据来帮助管理他们的数据。它还可以帮助数据专业人员收集、组织、访问和丰富元数据,以支持数据治理。
三十年前,数据资产可能是 Oracle 数据库中的一张表。然而,在现代企业中,我们拥有一系列令人眼花缭乱的不同类型的数据资产。可能是关系数据库或 NoSQL 存储中的表、实时流数据、 AI 系统中的功能、指标平台中的指标,数据可视化工具中的仪表板。
现代元数据管理应包含所有这些类型的数据资产,并使数据工作者能够更高效地使用这些资产完成工作。
所以,元数据管理应具备的功能如下:
搜索和发现:数据表、字段、标签、使用信息
访问控制:访问控制组、用户、策略
数据血缘:管道执行、查询
合规性:数据隐私/合规性注释类型的分类
数据管理:数据源配置、摄取配置、保留配置、数据清除策略
AI 可解释性、再现性:特征定义、模型定义、训练运行执行、问题陈述
数据操作:管道执行、处理的数据分区、数据统计
数据质量:数据质量规则定义、规则执行结果、数据统计
架构与开源方案
下面介绍元数据管理的架构实现,不同的架构都对应了不同的开源实现。
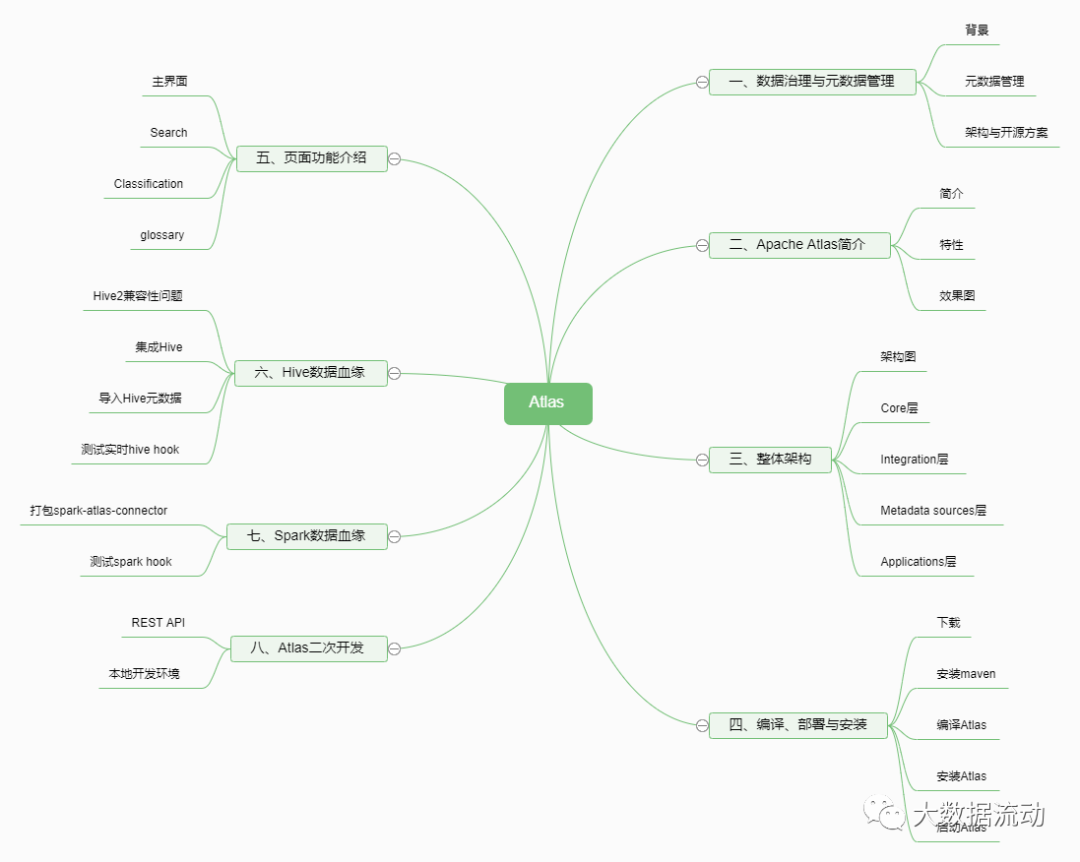
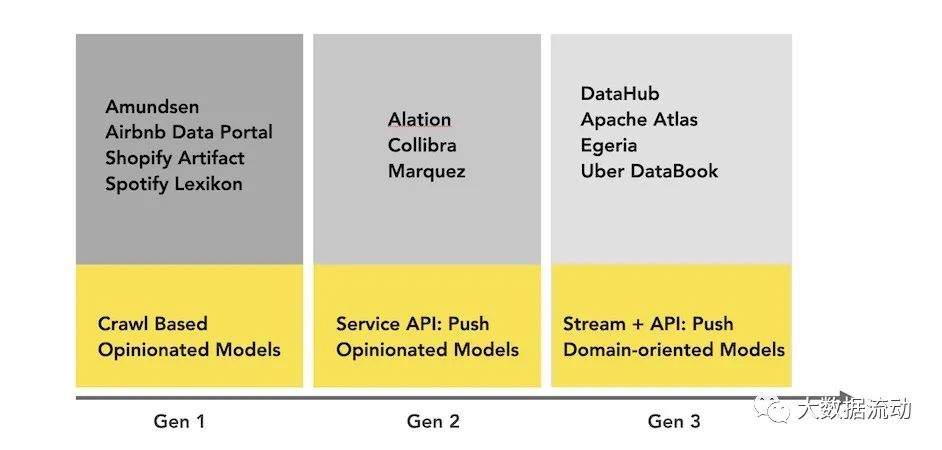
下图描述了第一代元数据架构。它通常是一个经典的单体前端(可能是一个 Flask 应用程序),连接到主要存储进行查询(通常是 MySQL/Postgres),一个用于提供搜索查询的搜索索引(通常是 Elasticsearch),并且对于这种架构的第 1.5 代,也许一旦达到关系数据库的“递归查询”限制,就使用了处理谱系(通常是 Neo4j)图形查询的图形索引。
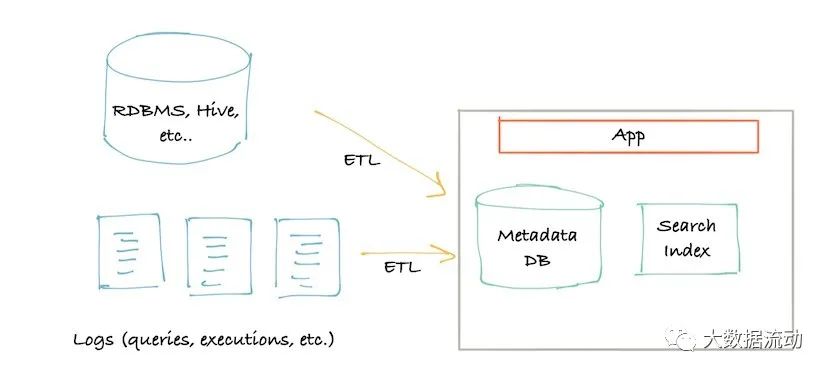
很快,第二代的架构出现了。单体应用程序已拆分为位于元数据存储数据库前面的服务。该服务提供了一个 API,允许使用推送机制将元数据写入系统。
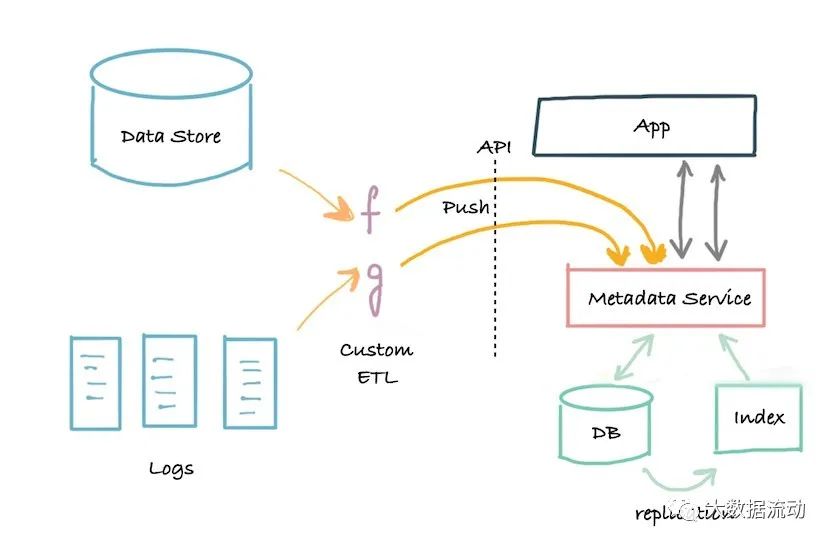
第三代架构是基于事件的元数据管理架构,客户可以根据他们的需要以不同的方式与元数据数据库交互。
元数据的低延迟查找、对元数据属性进行全文和排名搜索的能力、对元数据关系的图形查询以及全扫描和分析能力。
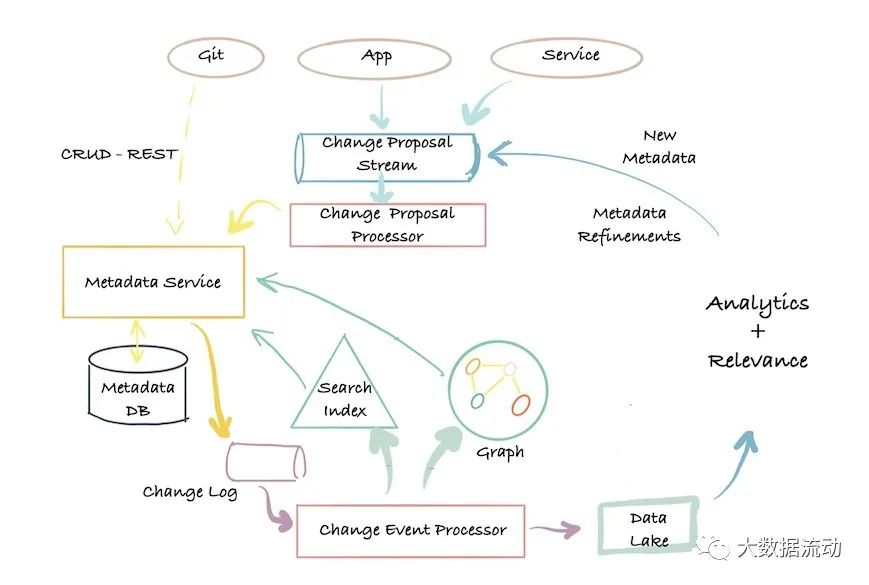
Apache Atlas 就是采用的这种架构,并且与Hadoop 生态系统紧密耦合。
下图是当今元数据格局的简单直观表示:
(包含部分非开源方案)
其他方案可作为调研的主要方向,但不是本文讨论的重点。
二、Apache Atlas简介
简介
在当今大数据的应用越来越广泛的情况下,数据治理一直是企业面临的巨大问题。
大部分公司只是单纯的对数据进行了处理,而数据的血缘,分类等等却很难实现,市场上也急需要一个专注于数据治理的技术框架,这时Atlas应运而生。
Atlas官网地址:https://atlas.apache.org/
Atlas是Hadoop的数据治理和元数据框架。
Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效,高效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系统集成。
Apache Atlas为组织提供了开放的元数据管理和治理功能,以建立其数据资产的目录,对这些资产进行分类和治理,并为数据科学家,分析师和数据治理团队提供围绕这些数据资产的协作功能。
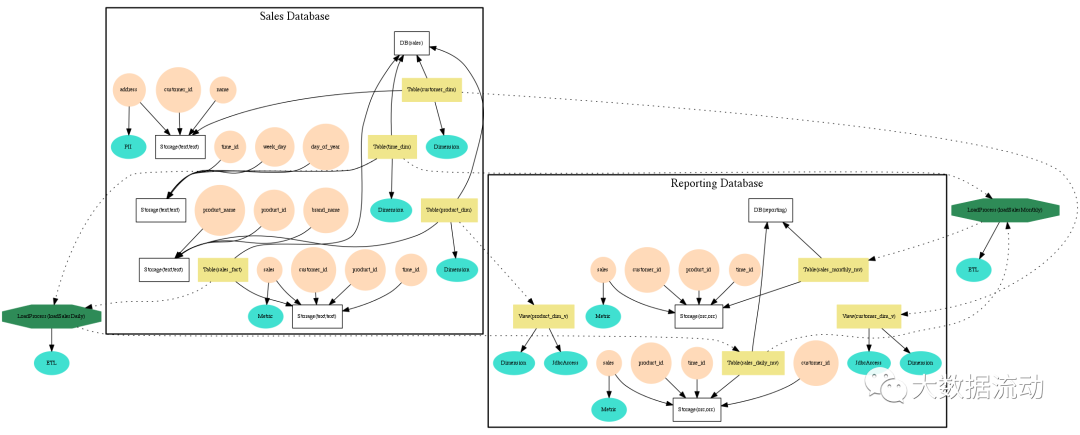
如果想要对这些数据做好管理,光用文字、文档等东西是不够的,必须用图。Atlas就是把元数据变成图的工具。
特性
Atlas支持各种Hadoop和非Hadoop元数据类型
提供了丰富的REST API进行集成
对数据血缘的追溯达到了字段级别,这种技术还没有其实类似框架可以实现
对权限也有很好的控制
Atlas包括以下组件:
采用Hbase存储元数据
采用Solr实现索引
Ingest/Export 采集导出组件 Type System类型系统 Graph Engine图形引擎 共同构成Atlas的核心机制
所有功能通过API向用户提供,也可以通过Kafka消息系统进行集成
Atlas支持各种源获取元数据:Hive,Sqoop,Storm。。。
还有优秀的UI支持
效果图
三、整体架构
架构图
Atlas架构图如下:
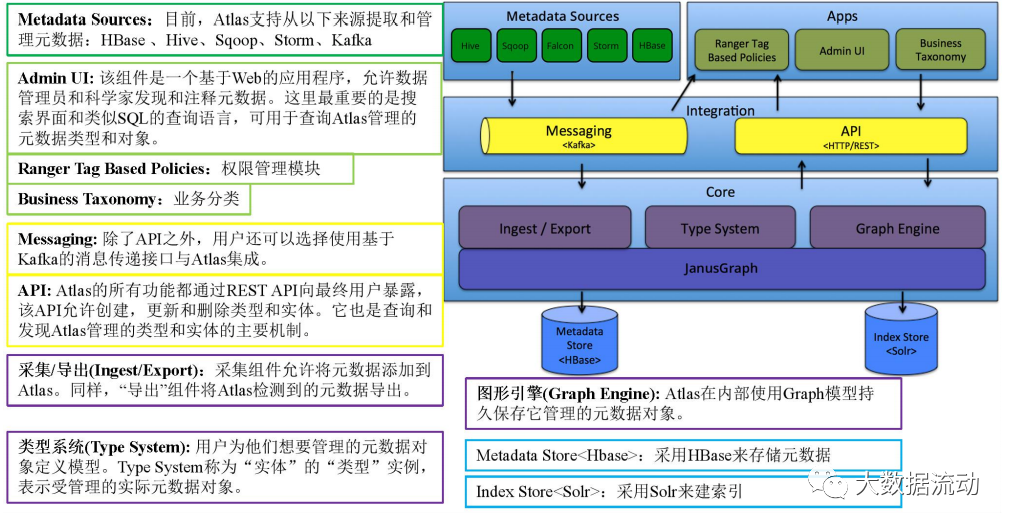
Core层
Atlas核心包含以下组件:
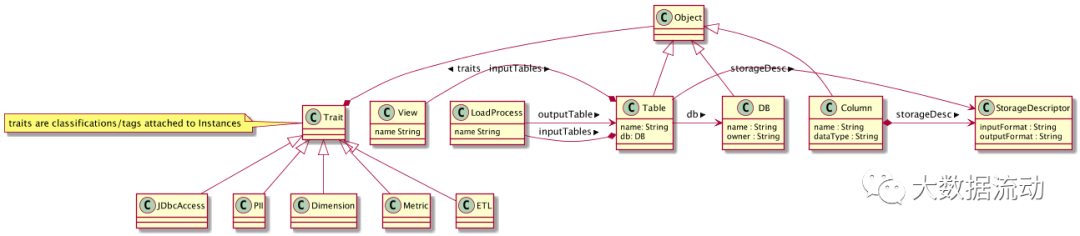
类型(Type)系统: Atlas允许用户为他们想要管理的元数据对象定义模型。该模型由称为“类型”的定义组成。称为“实体”的“类型”实例表示受管理的实际元数据对象。Type System是一个允许用户定义和管理类型和实体的组件。开箱即用的Atlas管理的所有元数据对象(例如Hive表)都使用类型建模并表示为实体。要在Atlas中存储新类型的元数据,需要了解类型系统组件的概念。
需要注意的一个关键点是Atlas中建模的一般特性允许数据管理员和集成商定义技术元数据和业务元数据。也可以使用Atlas的功能定义两者之间的丰富关系。
图形引擎: Atlas在内部使用Graph模型持久保存它管理的元数据对象。这种方法提供了很大的灵活性,可以有效地处理元数据对象之间的丰富关系。图形引擎组件负责在Atlas类型系统的类型和实体之间进行转换,以及底层图形持久性模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便可以有效地搜索它们。Atlas使用JanusGraph存储元数据对象。
采集/导出:采集组件允许将元数据添加到Atlas。同样,“导出”组件将Atlas检测到的元数据更改公开为事件。消费者可以使用这些更改事件来实时响应元数据的变更。
Integration层
在Atlas中,用户可以使用以下的两种方式管理元数据:
API: Atlas的所有功能都通过REST API向最终用户暴露,该API允许创建,更新和删除类型和实体。它也是查询和发现Atlas管理的类型和实体的主要机制。
Messaging: 除了API之外,用户还可以选择使用基于Kafka的消息传递接口与Atlas集成。这对于将元数据对象传递到Atlas以及使用Atlas使用可以构建应用程序的元数据更改事件都很有用。如果希望使用与Atlas更松散耦合的集成来实现更好的可伸缩性,可靠性等,则消息传递接口特别有用.Atlas使用Apache Kafka作为通知服务器,用于钩子和元数据通知事件的下游消费者之间的通信。事件由钩子和Atlas写入不同的Kafka主题。
Metadata sources层
Atlas支持开箱即用的多种元数据源集成。未来还将增加更多集成。目前,Atlas支持从以下来源提取和管理元数据:
HBase
Hive
Sqoop
Storm
Kafka
集成意味着两件事:Atlas定义的元数据模型用于表示这些组件的对象。Atlas提供了从这些组件中摄取元数据对象的组件(在某些情况下实时或以批处理模式)。
Applications层
Atlas管理的元数据被各种应用程序使用,以满足许多治理需求。
Atlas Admin UI: 该组件是一个基于Web的应用程序,允许数据管理员和科学家发现和注释元数据。这里最重要的是搜索界面和类似SQL的查询语言,可用于查询Atlas管理的元数据类型和对象。Admin UI使用Atlas的REST API来构建其功能。
Tag Based Policies:Apache Ranger是Hadoop生态系统的高级安全管理解决方案,可与各种Hadoop组件进行广泛集成。通过与Atlas集成,Ranger允许安全管理员定义元数据驱动的安全策略以实现有效的治理。Ranger是Atlas通知的元数据更改事件的使用者。
四、编译、部署与安装
Atlas的安装坑较多。本教程将详细介绍Atlas2.1.0整个安装过程。
比较难受的是 ,Atlas不提供安装包,下载的是源码包 ,需要自行编译打包。
下载
请前往官网 https://atlas.apache.org/#/Downloads
下载对应版本的源码包 本文使用的是 2.1.0版本
国内站点 速度要快一些
https://mirrors.tuna.tsinghua.edu.cn/apache/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
安装maven
注意,需要先安装maven,因为这是使用maven开发的java web工程。maven3.6.3版本即可
一些下载地址
http://maven.apache.org/download.cgi
https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
上传到linux的/usr/local目录
cd /usr/local
解压文件
tar -zxvf apache-maven-3.6.3-bin.tar.gz
配置环境变量
vi /etc/profile
export MAVEN_HOME=/usr/local/apache-maven-3.6.3
export PATH=MAVEN_HOME/bin:PATH
刷新环境变量
source /etc/profile
检查版本
mvn -v

配置好maven的环境变量 注意国内需要配置好maven的国内镜像,一般使用阿里,华为,清华等镜像 vi /usr/local/apache-maven-3.6.3/conf/settings.xml
alimaven
aliyun maven http://maven.aliyun.com/nexus/content/groups/public/
central
把这个setting.xml 拷贝到 ~/.m2/
cp settings.xml .m2/
编译Atlas
解压源码包
tar -zxvf apache-atlas-2.1.0-sources.tar.gz
1.修改atlas源码工程的pom.xml
将hbase zookeeper hive等依赖的版本修改成自己环境中一致的版本(或者兼容的版本)
父工程pom文件
3.4.14
2.2.3
7.7.2
2.执行maven编译打包
atlas可以使用内嵌的hbase-solr作为底层索引存储和搜索组件,也可以使用外置的hbase和solr 如果要使用内嵌的hbase-solr,则使用如下命令进行编译打包 cd apache-atlas-sources-2.1.0/ export MAVEN_OPTS="-Xms2g -Xmx2g" mvn clean -DskipTests package -Pdist,embedded-hbase-solr
不用内置就这样 mvn clean -DskipTests package -Pdist
改完路径还会非常快的 耐心等待
atlas的webui子模块中依赖了nodejs,会从nodejs的中央仓库去下载相关依赖库
编译完成之后,会产生打包结果,所在位置是:源码目录中的新出现的distro/target目录
注意,这里产出的有压缩包也有解压后的包。这里面的hook包,可以看到有各种平台的hook包。
顾名思义,这就是钩子包,也就是各个大数据框架会提供各种生命周期回调函数,并且将相关信息以数据方式提供出来。这些钩子就可以去监听和接收数据
如果没有错误 并看到一排success就是成功了
安装Atlas
在完成Atlas编译以后,就可以进行Atlas的安装了。Atlas的安装主要是安装Atlas的Server端,也就Atlas的管理页面,并确保Atlas与Kafka Hbase Solr等组件的集成。
Atlas的系统架构如下,在确保 底层存储与UI界面正常后,之后就可以进行与Hive等组件的集成调试了。
在完成Atlas编译以后,就可以进行Atlas的安装了。Atlas的安装主要是安装Atlas的Server端,也就Atlas的管理页面,并确保Atlas与Kafka Hbase Solr等组件的集成。
在确保 底层存储与UI界面正常后,之后就可以进行与Hive等组件的集成调试了。
1、环境准备
安装之前 先要准备好
JDK1.8
Zookeeper
Kafka
Hbase
Solr
在启动Atlas时会配置这些环境变量的地址,所以一定要确保以上组件正常运行。
由于在编译时可以选择内部集成,所以这些Atlas是可以自带的,但是JDK一定要安装好。
在安装Altas中,需要Solr 预先创建好collection
bin/solr create -c vertex_index -shards 3 -replicationFactor 2
bin/solr create -c edge_index -shards 3 -replicationFactor 2
bin/solr create -c fulltext_index -shards 3 -replicationFactor 2
在solr中验证创建成功。
2、安装Atlas
到编译好的包的路径下 apache-atlas-sources-2.1.0/distro/target
将生成好的安装包 apache-atlas-2.1.0-server.tar.gz 拷贝到目标路径下。
解压:
tar -zxvf apache-atlas-2.1.0-server.tar.gz
3、修改配置
进入conf目录下:
vi atlas-env.sh
在此指定JAVA_HOME和是否要用内嵌启动
export JAVA_HOME=/opt/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=true
export MANAGE_LOCAL_SOLR=true
如果使用内嵌,那么配置结束,直接去 启动Atlas
但是大部分时候,需要使用已经有的组件进行集成,所以设置为false。
export JAVA_HOME=/opt/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=false
export MANAGE_LOCAL_SOLR=false
#注意修改Hbase配置文件路径
export HBASE_CONF_DIR=/opt/hbase/conf
修改其他配置
vim atlas-application.properties
这里就是设置Hbase Solr等配置
#Hbase地址 就是Hbase配置的zookeeper地址
atlas.graph.storage.hostname=slave01:2181,slave02:2181,slave03:2181
atlas.audit.hbase.zookeeper.quorum=slave01:2181,slave02:2181,slave03:2181
#solr服务器地址
atlas.graph.index.search.solr.http-urls=http://slave01:8984/solr
#kafka地址
atlas.notification.embedded=false
atlas.kafka.zookeeper.connect=slave01:2181,slave02:2181,slave03:2181
atlas.kafka.bootstrap.servers=slave01:9092,slave02:9092,slave03:9092
#atlas地址
atlas.rest.address=http://slave01:21000
启动Atlas
bin/atlas_start.py
启动成功后访问:
http://slave01:21000
admin/admin登录
五、页面功能介绍
Atlas的页面功能非常的丰富,可以进行元数据的管理及数据血缘的展示。
主界面
Search
基本搜索
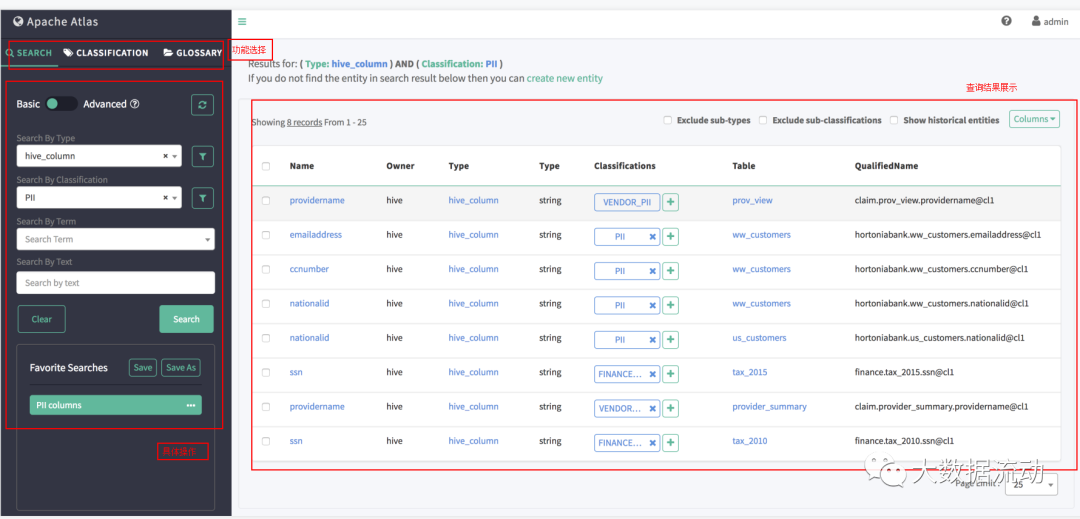
基本搜索允许您使用实体的类型名称,关联的分类/标记进行查询,并且支持对实体属性以及分类/标记属性进行过滤。
可以使用 AND/OR 条件对多个属性进行基于属性的过滤。
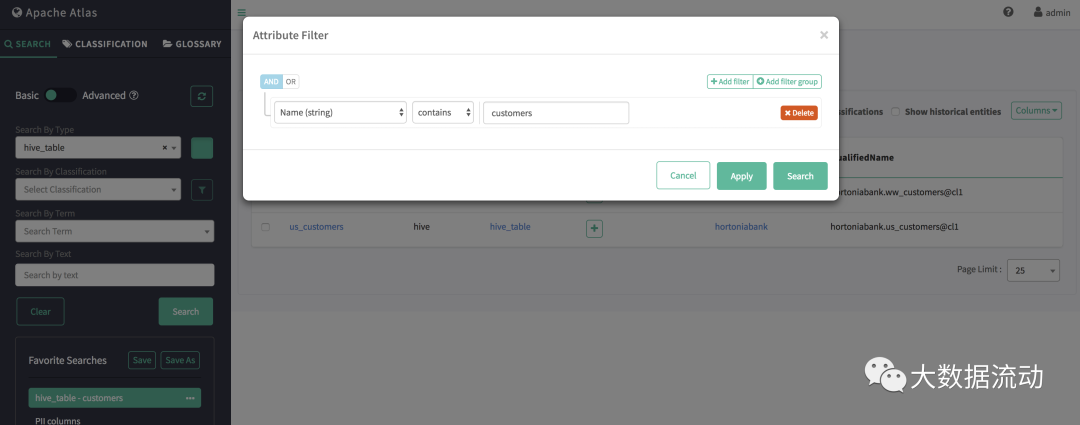
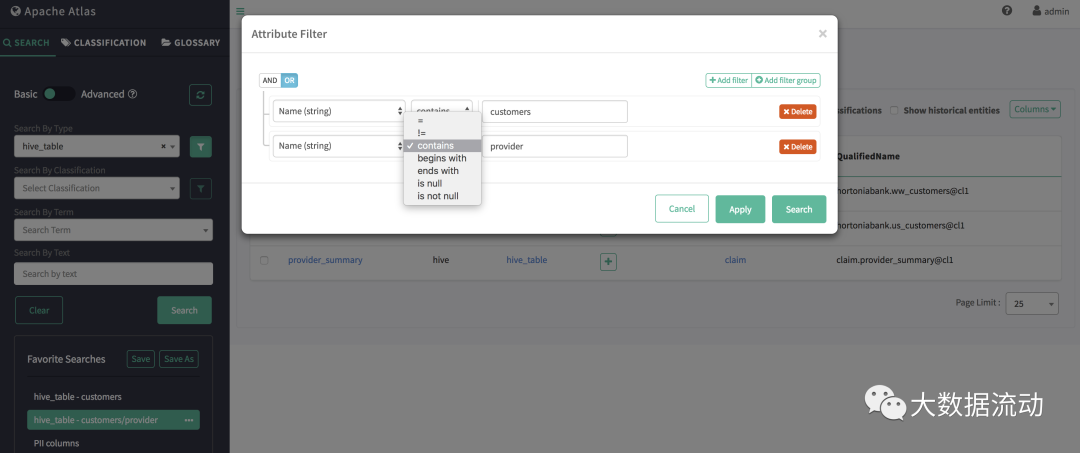
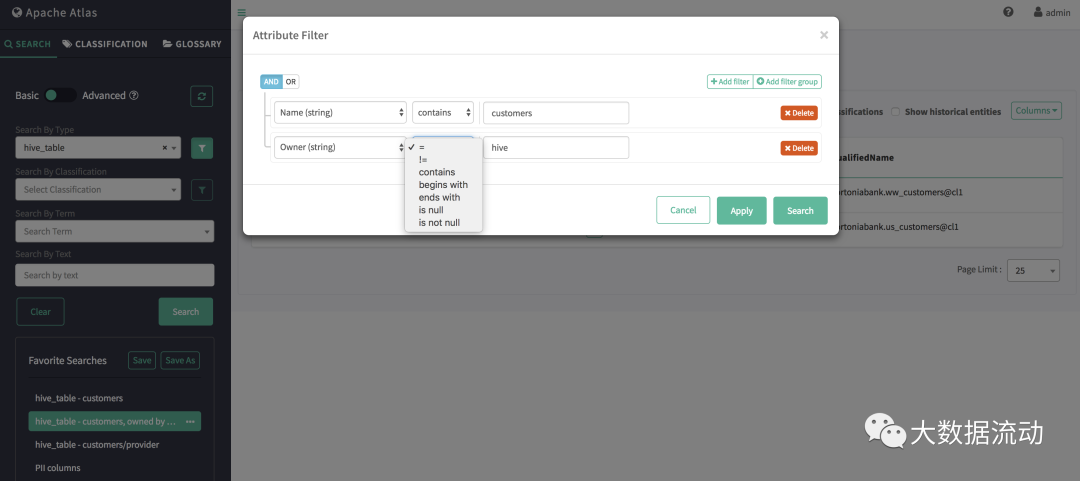
支持的过滤运算符
LT(符号:<, lt)适用于数字、日期属性
GT(符号:>、gt)适用于数字、日期属性
LTE(符号:<=, lte)适用于数字、日期属性
GTE(符号:>=,gte)适用于数字、日期属性
EQ(符号:eq、=)适用于数字、日期、字符串属性
NEQ(符号:neq、!=)适用于数字、日期、字符串属性
LIKE(符号:like、LIKE)与字符串属性一起使用
STARTS_WITH(符号:startsWith、STARTSWITH)与字符串属性一起使用
ENDS_WITH(符号:endsWith、ENDSWITH)与字符串属性一起使用
CONTAINS (symbols: contains, CONTAINS) 使用 String 属性
高级搜索
Atlas 中的高级搜索也称为基于 DSL 的搜索。
领域特定搜索 (DSL) 是一种结构简单的语言,该语法模拟了关系数据库流行的结构化查询语言 (SQL)。
具体语法请参考Github上的Atlas DSL Grammer (Antlr G4格式)。
例:要检索名称可以是 time_dim 或 customer_dim 的 Table 类型的实体:
from Table where name = 'time_dim' or name = 'customer_dim'
Classification
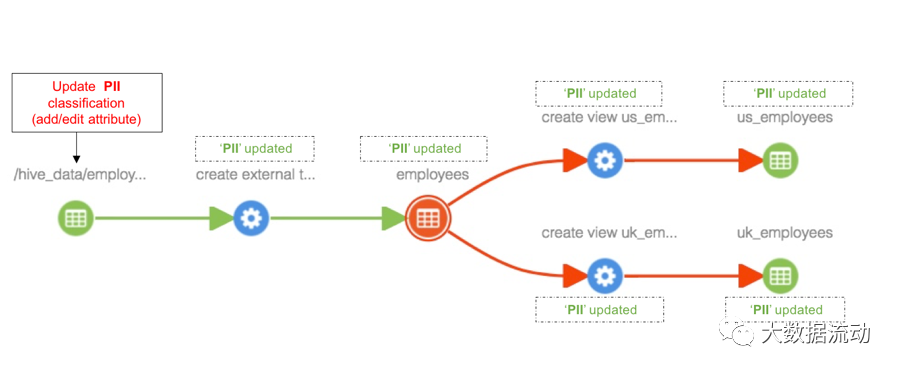
分类传播使与实体相关联的分类能够自动与该实体的其他相关实体相关联。这在处理数据集从其他数据集派生数据的场景时非常有用 。
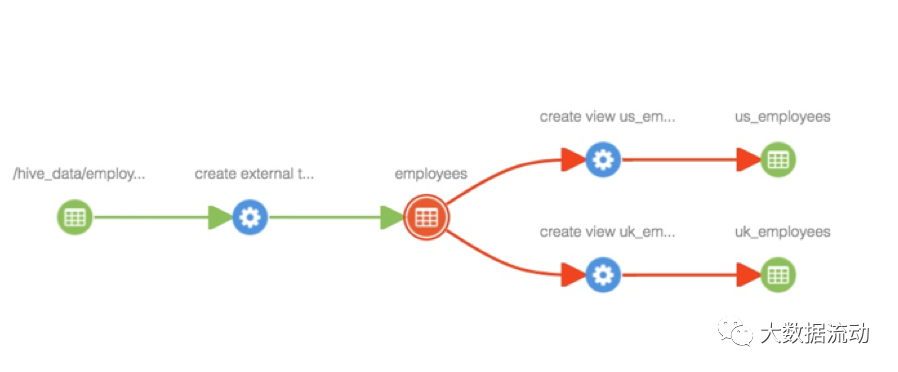
为实体添加分类
将分类“PII”添加到“hdfs_path”实体后,该分类将传播到沿袭路径中的所有受影响实体,包括“员工”表、视图“us_employees”和“uk_employees” - 如下所示。
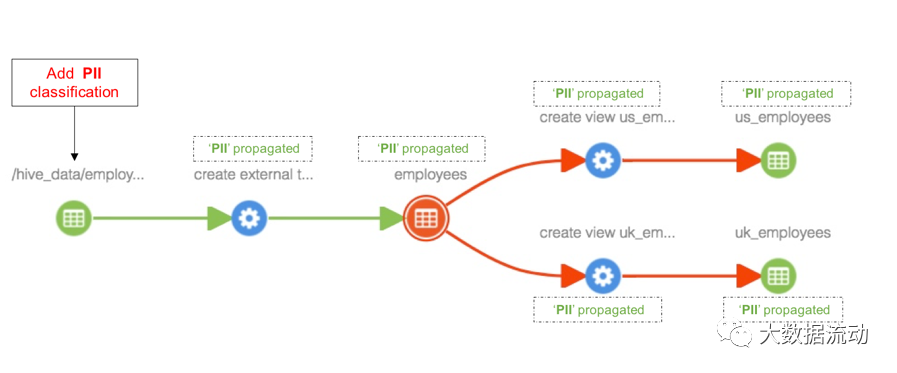
更新与实体关联的分类
与实体关联的分类的任何更新也将在分类传播到的所有实体中看到。
简单的说,此功能可以监控数据到底流向了哪里。
glossary
词汇表,也称术语表为业务用户提供适当的词汇表,它允许术语(词)相互关联并分类,以便在不同的上下文中理解它们。然后可以将这些术语映射到数据库、表、列等资产。这有助于抽象与存储库相关的技术术语,并允许用户发现/使用他们更熟悉的词汇表中的数据。
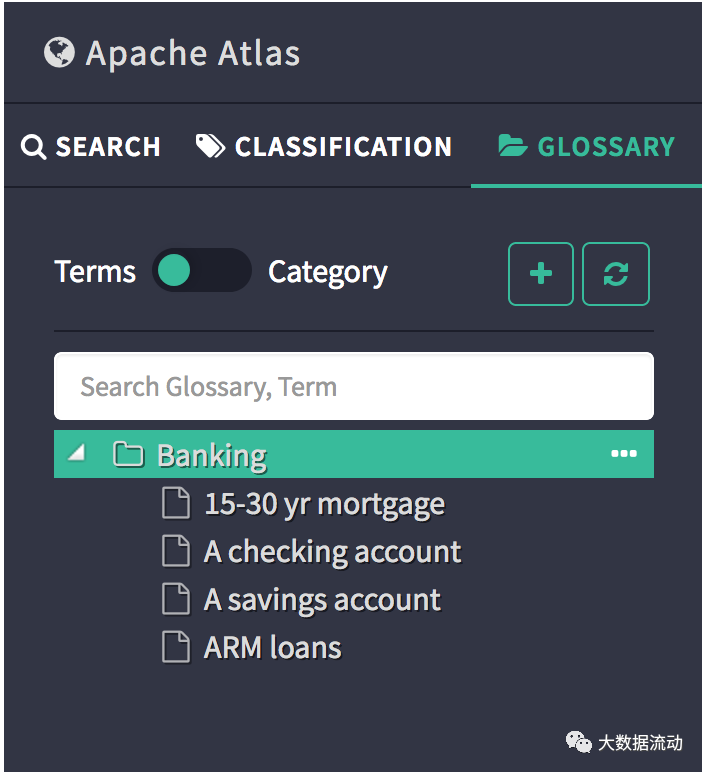
通过单击词汇表 UI 中的术语名称,可以查看术语的各种详细信息。详细信息页面下的每个选项卡提供该术语的不同详细信息。
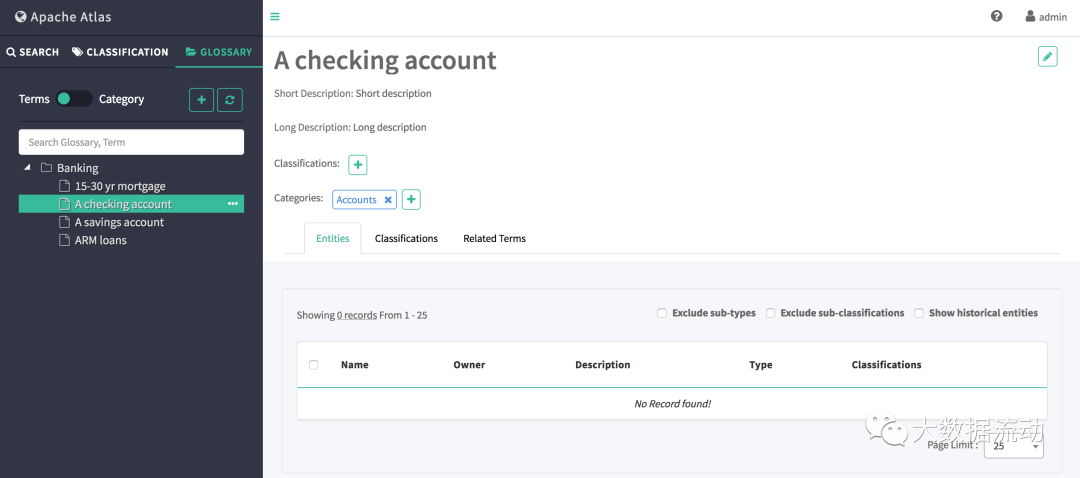
当切换开关在类别上时,面板将列出所有词汇表以及类别层次结构。这是此视图下可能的交互的列表。
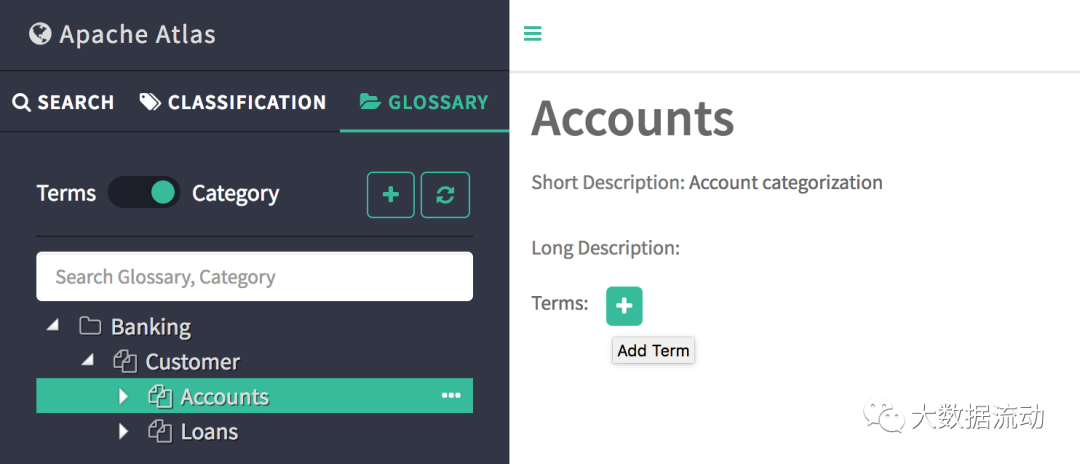
如果一个术语具有分类,则该实体已被分配继承相同的分类。
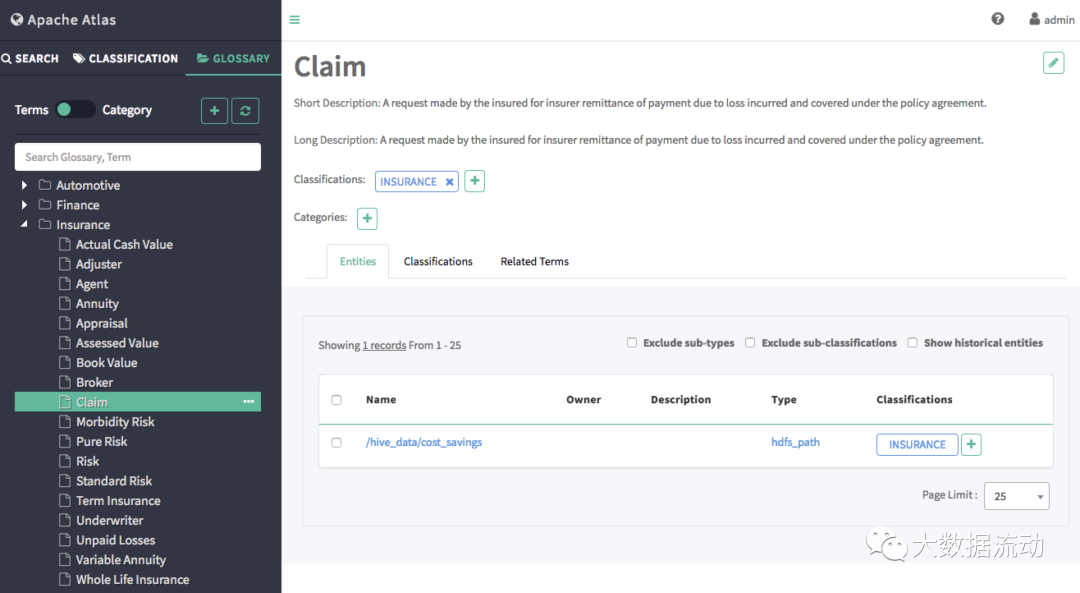
通过术语表的功能,让数据资产与业务系统建立了联系。
六、Hive数据血缘
Hive2兼容性问题
Atlas与Hive存在兼容性问题,本文基于Atlas2.1.0兼容CDH6.3.2部署。Hive版本为2.1.1.其他版本的问题不在此文档讨论。
为兼容Hive2.1.1,需要修改源码重新编译。
所需修改的项目位置:
apache-atlas-sources-2.1.0\addons\hive-bridge
①.org/apache/atlas/hive/bridge/HiveMetaStoreBridge.java 577行
String catalogName = hiveDB.getCatalogName() != null ? hiveDB.getCatalogName().toLowerCase() : null;
改为:
String catalogName = null;
②.org/apache/atlas/hive/hook/AtlasHiveHookContext.java 81行
this.metastoreHandler = (listenerEvent != null) ? metastoreEvent.getIHMSHandler() : null;
改为:C:\Users\Heaton\Desktop\apache-atlas-2.1.0-sources\apache-atlas-sources-2.1.0\addons
this.metastoreHandler = null;
集成Hive
将 atlas-application.properties 配置文件,压缩加入到 atlas-plugin-classloader-2.0.0.jar 中
#必须在此路径打包,才能打到第一级目录下
cd /usr/local/src/atlas/apache-atlas-2.1.0/conf
zip -u /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/atlas-plugin-classloader-2.1.0.jar atlas-application.properties
修改 hive-site.xml
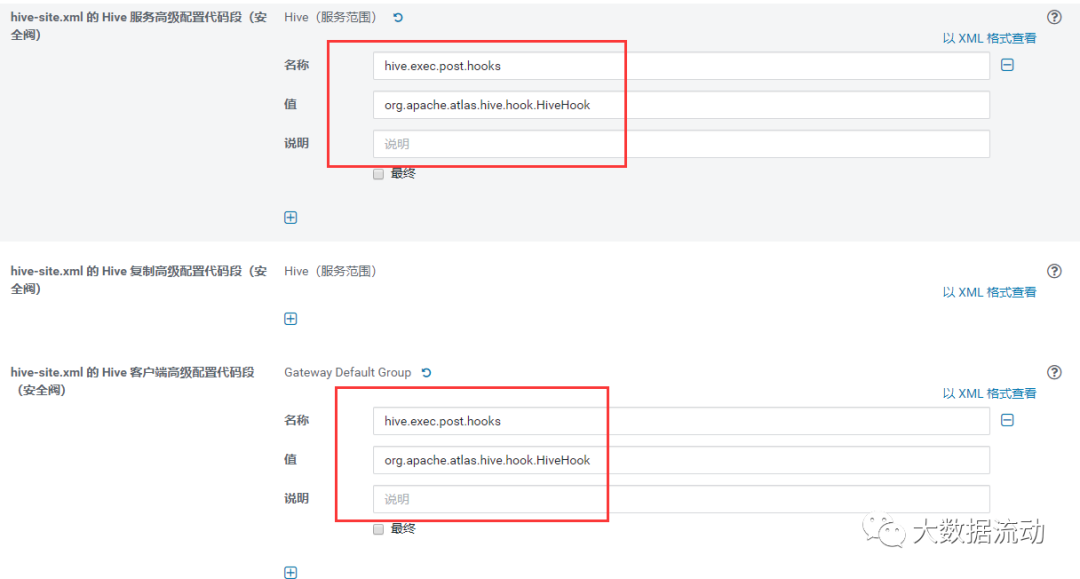
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
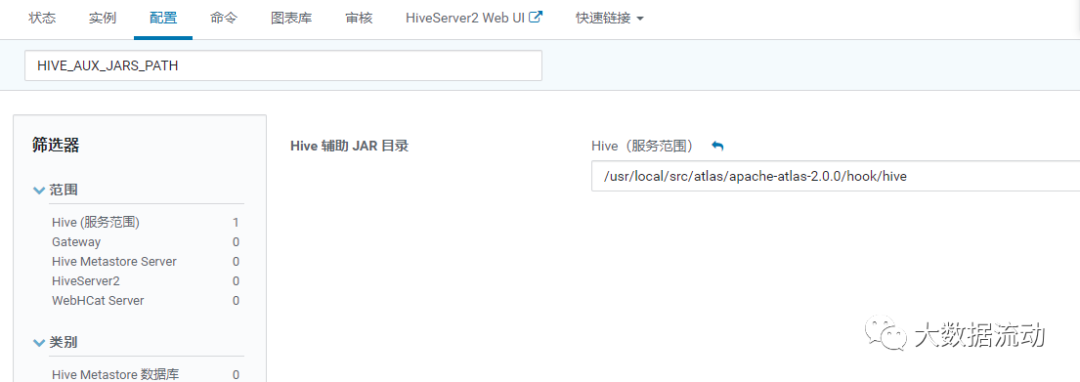
修改 hive-env.sh 的 Gateway 客户端环境高级配置代码段(安全阀)

HIVE_AUX_JARS_PATH=/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
修改 HIVE_AUX_JARS_PATH
修改 hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)
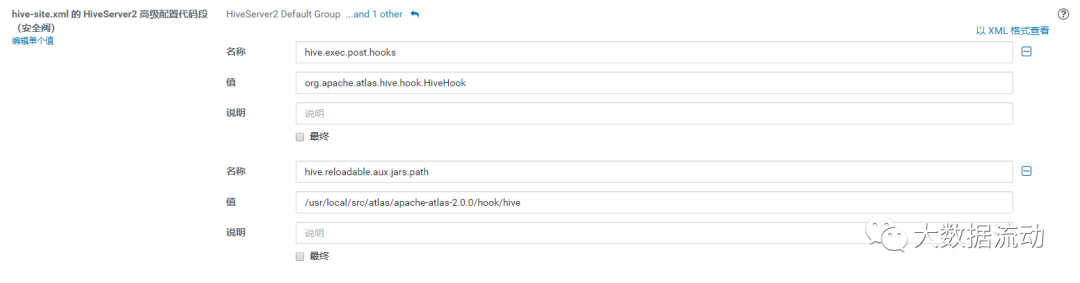
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
hive.reloadable.aux.jars.path
/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
修改 HiveServer2 环境高级配置代码段

HIVE_AUX_JARS_PATH=/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
需要将配置好的Atlas包发往各个hive节点后重启集群。
导入Hive元数据
执行atlas脚本
./bin/import-hive.sh
#输入用户名:admin;输入密码:admin
登录Atlas查看元数据信息。
测试实时hive hook
简单执行一个hera资源统计的hive脚本
use sucx_test
;
-- 昨日升级设备数
create table if not exists qs_tzl_ProductTag_result(
pid string
,category string
,category_code string
,tag_name string
,tag_value string
,other string
,update_time string
)
partitioned by (tag_id string)
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY')
;
insert overwrite table qs_tzl_ProductTag_result partition(tag_id='3014')
select
T1.product_id as pid
,T2.category
,cast(from_unixtime(unix_timestamp()) as string) as update_time
from (select
product_id
from COM_PRODUCT_UPGRADE_STAT_D where p_day='20200901'
) T1
left join (select category
from bi_ods.ods_smart_product where dt='20200901'
) T2
on T1.product_id=T2.id
;
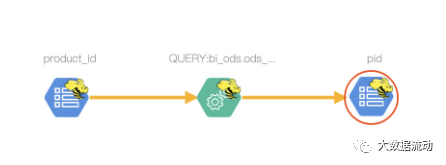
执行后查看 qs_tzl_ProductTag_result 的表级血缘为
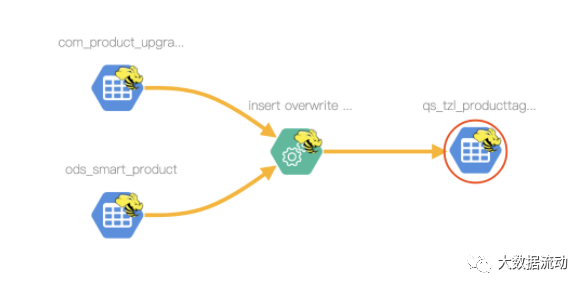
pid 的字段血缘为
七、Spark数据血缘
打包spark-atlas-connector
atlas 官方文档中并不支持 spark sql 的解析,需要使用第三方的包。
地址:https://github.com/hortonworks-spark/spark-atlas-connector
一、git clone 后本地进行打包
mvn package -DskipTests
二、打包后在 spark-atlas-connector/spark-atlas-connector-assembly/target 目录有一个 spark-atlas-connector-assembly-${version}.jar 的 jar,将该 jar 上传到服务器。需要注意的是不要上传 spark-atlas-connector/spark-atlas-connector/target 这个目录内的 jar ,缺少相关依赖包
三、将 spark-atlas-connector-assembly-${version}.jar 放到一个固定目录 比如/opt/resource
测试spark hook
首先进入spark-sql client
spark-sql --master yarn \
--jars /opt/resource/spark-atlas-connector_2.11-0.1.0-SNAPSHOT.jar \
--files /opt/resource/atlas-application.properties \
--conf spark.extraListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \
--conf spark.sql.queryExecutionListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \
--conf spark.sql.streaming.streamingQueryListeners=com.hortonworks.spark.atlas.SparkAtlasStreamingQueryEventTracker
执行 hera 的一个资源统计任务
CREATE EXTERNAL TABLE IF NOT EXISTS sucx_hera.ads_hera_task_mem_top_10(
`job_id` BIGINT COMMENT '任务ID',
`user` STRING COMMENT '关注人',
`applicationId` STRING COMMENT 'yarn执行的app id',
`memorySeconds` BIGINT COMMENT '内存使用时间和',
`startedTime` BIGINT COMMENT '开始时间',
`finishedTime` BIGINT COMMENT '结束时间',
`elapsedTime` BIGINT COMMENT '运行时间',
`vcoreSeconds` BIGINT COMMENT 'vcore使用时间和')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'cosn://sucx-big-data/bi//sucx_hera/ads_hera_task_mem_top_10';
insert overwrite table sucx_hera.ads_hera_task_mem_top_10
select
job_id,user,applicationId,memorySeconds,startedTime,finishedTime,elapsedTime,vcoreSeconds
from
(SELECT
top.job_id,
row_number() over(distribute by top.applicationId ORDER BY sso.id) as num,
case when sso.name is null then operator
else sso.name end as user,
top.applicationId,
top.memorySeconds,
top.startedTime,
top.finishedTime,
top.elapsedTime,
top.vcoreSeconds
FROM (
select * from sucx_hera.dws_hera_task_mem_top_10 where dt = '20200901' ) top
left join bi_ods.ods_hera_job_monitor monitor
on monitor.dt='20200901' and top.job_id=monitor.job_id
left join bi_ods.ods_hera_sso sso
on sso.dt='20200901' and find_in_set(sso.id,monitor.user_ids) >0 order by job_id ) temp
where temp.num = 1
执行后,查看 ads_hera_task_mem_top_10 表级血缘
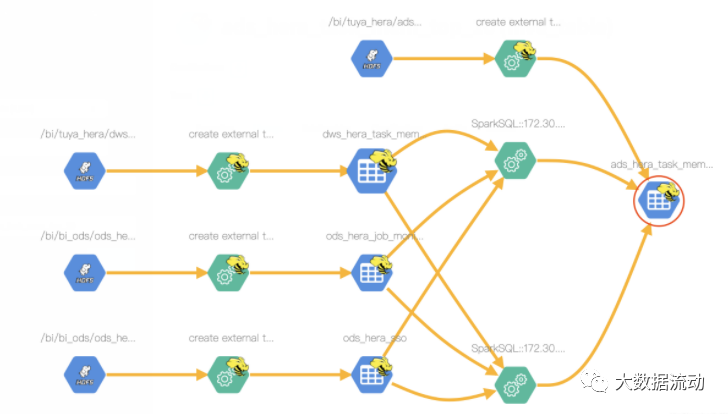
注意此包不支持 spark 字段的支持。
如果需要spark字段的支持,一种是spark代码转成hive跑一遍,一种就是需要自研了。
八、Atlas二次开发
atlas虽好,但是很多场景依然无法满足我们的需要。这时候就不得不做一些改动了。二次开发有两种方式一种是基于Atlas Api的开发,一种是修改源码。
REST API
http://atlas.apache.org/api/v2/index.html
DiscoveryREST
http://hostname:21000/api/atlas/v2/search/basic?classification=class1
参数支持:query、typeName、classification、excludeDeletedEntities、limit、offset
code:https://github.com/apache/atlas/blob/6bacbe946bbc5ca72118304770d5ad920695bd52/webapp/src/main/java/org/apache/atlas/web/rest/DiscoveryREST.java
# 查询所有 Table
http://hostname:21000/api/atlas/v2/search/dsl?typeName=Table
# 查询 owner 前缀为 John 的 Table
http://hostname:21000/api/atlas/v2/search/attribute?typeName=Table&attrName=owner&attrValuePrefix=John
# 查询 Table 的一些属性,如:guid, ownerName, searchParameters 等
http://hostname:21000/api/atlas/v2/search/saved/Table
# 不是很懂(返回的数据和上面那个 API 一模一样)
http://hostname:21000/api/atlas/v2/search/saved
# 查询 EntityType - Table 下有哪些 entity.
http://hostname:21000/api/atlas/v2/search/saved/execute/Table
# 查询 guid 为 e283d8c1-ae19-4f4b-80c0-38031788383b 的 EntityType 下有哪些 entity.
http://hostname:21000/api/atlas/v2/search/saved/execute/guid/e283d8c1-ae19-4f4b-80c0-38031788383b
LineageREST
# 查询 guid 为 a95cb57f-4643-4edf-b5a5-0f1de2e0f076 的实体的血缘
http://hostname:21000/api/atlas/v2/lineage/a95cb57f-4643-4edf-b5a5-0f1de2e0f076
EntityREST
# 查询 guid 为 48f29229-47a9-4b05-b053-91e6484f42a1 的实体
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1
# 查询 guid 为 48f29229-47a9-4b05-b053-91e6484f42a1 的实体的审计数据
http://hostname:21000/api/atlas/v2/entity/48f29229-47a9-4b05-b053-91e6484f42a1/audit
# 查询 guid 为 48f29229-47a9-4b05-b053-91e6484f42a1 的实体所属的 classifications
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1/classifications
# 根据 EntityType 的唯一属性查找实体
# 如下:name 是 DB 的一个唯一属性. 查找 name=Logging 的 DB.
http://hostname:21000/api/atlas/v2/entity/uniqueAttribute/type/DB?attr:name=Logging
# 查询 entity 与 classification 是否有关?
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1/classification/Dimension
# 批量查询实体
http://hostname:21000/api/atlas/v2/entity/bulk?guid=e667f337-8dcc-468b-a5d0-96473f8ede26&guid=a95cb57f-4643-4edf-b5a5-0f1de2e0f076
RelationshipREST
# 查询 guid 为 726c0120-19d2-4978-b38d-b03124033f41 的 relationship
# 注:relationship 可以看做是血缘的一条边
http://hostname:21000/api/atlas/v2/relationship/guid/726c0120-19d2-4978-b38d-b03124033f41
TypesREST
http://hostname:21000/api/atlas/v2/types/typedef/guid/e0ca4c40-6165-4cec-b489-2b8e5fc7112b
http://hostname:21000/api/atlas/v2/types/typedef/name/Table
http://hostname:21000/api/atlas/v2/types/typedefs/headers
http://hostname:21000/api/atlas/v2/types/typedefs
http://hostname:21000/api/atlas/v2/types/enumdef/name/hive_principal_type
http://hostname:21000/api/atlas/v2/types/enumdef/guid/ee30446a-92e1-4bbc-aa0a-66ac21970d88
http://hostname:21000/api/atlas/v2/types/structdef/name/hive_order
http://hostname:21000/api/atlas/v2/types/structdef/guid/0b602605-8c88-4b60-a177-c1c671265294
http://hostname:21000/api/atlas/v2/types/classificationdef/name/PII
http://hostname:21000/api/atlas/v2/types/classificationdef/guid/3992eef8-fd74-4ae7-8b35-fead363b2122
http://hostname:21000/api/atlas/v2/types/entitydef/name/DataSet
http://hostname:21000/api/atlas/v2/types/entitydef/guid/5dca20ce-7d57-4bc3-a3f1-93fa622c32b1
http://hostname:21000/api/atlas/v2/types/relationshipdef/name/process_dataset_outputs
http://hostname:21000/api/atlas/v2/types/relationshipdef/guid/5d76dae0-6bad-4d19-b9b2-cb0cdc3b53d5
GlossaryREST
http://hostname:21000/api/atlas/v2/glossary
http://hostname:21000/api/atlas/v2/glossary/302dc8f8-3bc8-4878-9ba2-0c585ca6de3d
本地开发环境
启动HBase和solr
由于在Atlas需要使用到HBase以及slor。方便调试可以解压之前编译好内置HBase和sole的tar。
文件补充
创建文件夹将,atlas所需要的文件拷贝过去。
将编译内置HBase以及solr源码目录distro/target/conf下的文件拷贝到上述的上图的conf目录。将源码中addons/models下所有的文件拷贝过去。将源码中的atlas/webapp/target中的内容全部拷贝到webapp目录中。
源码启动
将clone下来的源码导入到IDEA中。配置启动参数:
-Datlas.home=/opt/deploy
-Datlas.conf=/opt/deploy/conf
-Datlas.data=/opt/deploy/data
附录:
参考文章:
http://atlas.apache.org/
https://blog.csdn.net/su20145104009/article/details/108253556
https://www.cnblogs.com/ttzzyy/p/14143508.html