
肝了3天,整理了50个Pandas高频使用技巧,强烈建议收藏!
今天小编来分享在pandas当中经常会被用到的方法,篇幅可能有点长但是提供的都是干货,读者朋友们看完之后也可以点赞收藏,相信会对大家有所帮助,大致本文会讲述这些内容
- DataFrame初印象
- 读取表格型数据
- 筛选出特定的行
- 用
pandas来绘图 - 在DataFrame中新增行与列
- DataFrame中的统计分析与计算
- DataFrame中排序问题
- 合并多个表格
- 时序问题的处理
- 字符串类型数据的处理
DataFrame初印象
我们先来通过Python当中的字典类型来创建一个DataFrame,
import pandas as pd
data = {"Country": ["Canada", "USA", "UK"],
"Population": [10.52*10**6, 350.1*10**6, 65.2*10**6]
}
df = pd.DataFrame(data)
df
Python当中的字典来创建DataFrame,字典当中的keys会被当做是列名,而values则是表格当中的值 Country Population
0 Canada 10520000.0
1 USA 350100000.0
2 UK 65200000.0
要是我们要获取当中的某一列,我们可以这么来做
df["Country"]
output
0 Portugal
1 USA
2 France
Name: Country, dtype: object
而当我们想要获取表格当中每一列的数据格式的时候,可以这么做
df.dtypes
output
Country object
Population float64
dtype: object
读取数据
Pandas当中有特定的模块可以来读取数据,要是读取的文件是csv格式,我们可以这么来做import pandas as pd
df = pd.read_csv("titanic.csv")
我们要是想要查看表格的前面几行,可以这么做
df.head(7)
output
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
6 7 0 1 ... 51.8625 E46 S
tail()方法来展示末尾的若干行的数据df.tail(7)
output
PassengerId Survived Pclass ... Fare Cabin Embarked
884 885 0 3 ... 7.050 NaN S
885 886 0 3 ... 29.125 NaN Q
886 887 0 2 ... 13.000 NaN S
887 888 1 1 ... 30.000 B42 S
888 889 0 3 ... 23.450 NaN S
889 890 1 1 ... 30.000 C148 C
890 891 0 3 ... 7.750 NaN Q
要是遇到文件的格式是excel格式,pandas当中也有相对应的方法
df = pd.read_excel("titanic.xlsx")
可以通过pandas当中的info()方法来获取对表格数据的一个初步的印象
df.info()
output
'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
筛选出特定条件的行
要是我们想要筛选出年龄在30岁以上的乘客,我们可以这么来操作
df[df["Age"] > 30]
output
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
6 7 0 1 ... 51.8625 E46 S
11 12 1 1 ... 26.5500 C103 S
.. ... ... ... ... ... ... ...
873 874 0 3 ... 9.0000 NaN S
879 880 1 1 ... 83.1583 C50 C
881 882 0 3 ... 7.8958 NaN S
885 886 0 3 ... 29.1250 NaN Q
890 891 0 3 ... 7.7500 NaN Q
[305 rows x 12 columns]
当然我们也可以将若干个条件合起来,一同做筛选,例如
survived_under_45 = df[(df["Survived"]==1) & (df["Age"]<45)]
survived_under_45
output
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
8 9 1 3 ... 11.1333 NaN S
9 10 1 2 ... 30.0708 NaN C
.. ... ... ... ... ... ... ...
874 875 1 2 ... 24.0000 NaN C
875 876 1 3 ... 7.2250 NaN C
880 881 1 2 ... 26.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
889 890 1 1 ... 30.0000 C148 C
[247 rows x 12 columns]
&也就是and的表达方式来将两个条件组合到一起,表示要将上述两个条件都满足的数据给筛选出来。当然我们在上文也提到,数据集中有部分的列存在空值,我们可以以此来筛选行与列df[df["Age"].notna()]
output
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
885 886 0 3 ... 29.1250 NaN Q
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[714 rows x 12 columns]
isin方法来进行筛选,df[df["Pclass"].isin([1, 2])]
output
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
3 4 1 1 ... 53.1000 C123 S
6 7 0 1 ... 51.8625 E46 S
9 10 1 2 ... 30.0708 NaN C
11 12 1 1 ... 26.5500 C103 S
.. ... ... ... ... ... ... ...
880 881 1 2 ... 26.0000 NaN S
883 884 0 2 ... 10.5000 NaN S
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
889 890 1 1 ... 30.0000 C148 C
[400 rows x 12 columns]
df[(df["Pclass"] == 1) | (df["Pclass"] == 2)]
筛选出特定条件的行与列
要是我们想要筛选出年龄大于40岁的乘客,同时想要得知他们的姓名,可以这么来操作df.loc[df["Age"] > 40,"Name"]
output
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
15 Hewlett, Mrs. (Mary D Kingcome)
33 Wheadon, Mr. Edward H
35 Holverson, Mr. Alexander Oskar
...
862 Swift, Mrs. Frederick Joel (Margaret Welles Ba...
865 Bystrom, Mrs. (Karolina)
871 Beckwith, Mrs. Richard Leonard (Sallie Monypeny)
873 Vander Cruyssen, Mr. Victor
879 Potter, Mrs. Thomas Jr (Lily Alexenia Wilson)
Name: Name, Length: 150, dtype: object
loc\iloc来筛选出部分数据的时候,[]中的第一部分代表的是“行”,例如df["Age"] > 40,而[]中的第二部分代表的是“列”,例如Name,你可以选择只要一列,也可以选择需要多列,用括号括起来即可df.loc[df["Age"] > 40,["Name", "Sex"]]
如果我们将逗号后面的部分直接用:来代替,则意味着要所有的列
df.loc[df["Age"] > 40,:]
output
PassengerId Survived Pclass ... Fare Cabin Embarked
6 7 0 1 ... 51.8625 E46 S
11 12 1 1 ... 26.5500 C103 S
15 16 1 2 ... 16.0000 NaN S
33 34 0 2 ... 10.5000 NaN S
35 36 0 1 ... 52.0000 NaN S
.. ... ... ... ... ... ... ...
862 863 1 1 ... 25.9292 D17 S
865 866 1 2 ... 13.0000 NaN S
871 872 1 1 ... 52.5542 D35 S
873 874 0 3 ... 9.0000 NaN S
879 880 1 1 ... 83.1583 C50 C
[150 rows x 12 columns]
iloc来进行筛选,只是与上面loc不同的在于,这里我们要填的是索引,例如我们想要前面的0-3列以及0-9行的内容,df.iloc[0:10, 0:3]
output
PassengerId Survived Pclass
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
5 6 0 3
6 7 0 1
7 8 0 3
8 9 1 3
9 10 1 2
用Pandas来画图
我们还可以用Pandas来画图,而且实际用到的代码量还比较的少
df.plot()
output
要是你想要单独某一列的趋势图,我们也可以这么做
df["Age"].plot()
output

要是我们想要不同年龄对于船票费“Fare”的影响,画图可以这么来画
df.plot.scatter(x = "Age", y = "Fare", alpha = 0.6)
output
for method_name in dir(df.plot):
if not method_name.startswith("_"):
print(method_name)
output
area
bar
barh
box
density
hexbin
hist
kde
line
pie
scatter
df.plot.box()
output
要是我们希望可以分开来绘制图形,就可以这么来操作
df.plot.area(figsize=(12, 4), subplots=True)
output
要是我们想要将绘制好的图片保存下来,可以直接使用savefig方法,
import matplotlib.pyplot as plt
fig, axs = plt.subplots(figsize=(12, 4))
df.plot.area(ax=axs)
fig.savefig("test.png")
output
如何新增一列
在DataFrame当中新增一列其实不难,我们可以这么来操作
df["Date"] = pd.date_range("1912-04-02", periods=len(df))
df.head()
output
PassengerId Survived Pclass ... Cabin Embarked Date
0 1 0 3 ... NaN S 1912-04-02
1 2 1 1 ... C85 C 1912-04-03
2 3 1 3 ... NaN S 1912-04-04
3 4 1 1 ... C123 S 1912-04-05
4 5 0 3 ... NaN S 1912-04-06
[5 rows x 13 columns]
def define_age(age):
if age < 18:
return "少年"
elif age >= 18 and age < 35:
return "青年"
elif age >= 35 and age < 55:
return "中年"
else:
return "老年"
然后再用apply来实现
df["Generation"] = df["Age"].apply(define_age)
df.head()
output
PassengerId Survived Pclass ... Cabin Embarked Generation
0 1 0 3 ... NaN S 青年
1 2 1 1 ... C85 C 中年
2 3 1 3 ... NaN S 青年
3 4 1 1 ... C123 S 中年
4 5 0 3 ... NaN S 中年
[5 rows x 13 columns]
如果我们想给表格中的列名重新命名的话,可以使用rename方法,
df_renamed = df.rename(columns={"Name":"Full Name", "Sex": "Gender", "Ticket": "FareTicket"})
df_renamed.head()
output
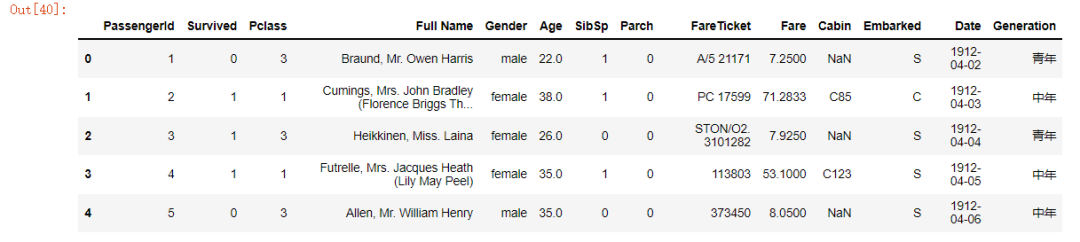
DataFrame中的统计分析
在Pandas中也提供了很多相关的方法来进行数据的统计分析
print(df["Age"].mean())
print(df["Age"].max())
print(df["Age"].min())
print(df["Age"].median())
29.69911764705882
80.0
0.42
28.0
同时我们也可以使用describe()方法
df.describe()
output
PassengerId Survived Pclass ... SibSp Parch Fare
count 891.000000 891.000000 891.000000 ... 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 ... 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 ... 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 ... 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 ... 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 ... 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 ... 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 ... 8.000000 6.000000 512.329200
[8 rows x 7 columns]
当然我们也可以对于特定几列的数据进行统计分析
df.agg(
{
"Age": ["min", "max", "mean"],
"Fare": ["min", "max", "mean"]
}
)
output
Age Fare
min 0.420000 0.000000
max 80.000000 512.329200
mean 29.699118 32.204208
groupby方法来进行数据的统计,例如我们想要知道不同的性别之下的平均年龄分别是多少,可以这么来操作df[["Sex", "Age"]].groupby("Sex").mean()
output
Age
Sex
female 27.915709
male 30.726645
另外,value_counts()方法也可以针对单独某一列数据,看一下数据的具体分布,
df["Pclass"].value_counts()
output
3 491
1 216
2 184
Name: Pclass, dtype: int64
DataFrame中的排序问题
我们假设有这么一组数据,
data = {
"Name": ["Mike", "Peter", "Clara", "Tony", "John"],
"Age": [30, 26, 20, 22, 25]
}
df = pd.DataFrame(data)
df
output
Name Age
0 Mike 30
1 Peter 26
2 Clara 20
3 Tony 22
4 John 25
我们可以将数据按照“Age”年龄这一列来进行排序
df.sort_values(by="Age")
output
Name Age
2 Clara 20
3 Tony 22
4 John 25
1 Peter 26
0 Mike 30
当然我们也可以按照降序来进行排列
df.sort_values("Age", ascending=False)
output
Name Age
0 Mike 30
1 Peter 26
4 John 25
3 Tony 22
2 Clara 20
合并多个表格
例如我们有这么两个表格,
df1 = pd.DataFrame(
{
"Name": ["Mike", "John", "Clara", "Linda"],
"Age": [30, 26, 20, 22]
}
)
df2 = pd.DataFrame(
{
"Name": ["Brian", "Mary"],
"Age": [45, 38]
}
)
df_names_ages = pd.concat([df1, df2], axis=0)
df_names_ages
output
Name Age
0 Mike 30
1 John 26
2 Clara 20
3 Linda 22
0 Brian 45
1 Mary 38
concat方法来进行合并,当然我们也可以用join方法df1 = pd.DataFrame(
{
"Name": ["Mike", "John", "Clara", "Sara"],
"Age": [30, 26, 20, 22],
"City": ["New York", "Shanghai", "London", "Paris"],
}
)
df2 = pd.DataFrame(
{
"City": ["New York", "Shanghai", "London", "Paris"],
"Occupation": ["Machine Learning Enginner", "Data Scientist", "Doctor","Teacher"]
}
)
df_merged = pd.merge(df1,df2,how="left", on="City")
df_merged
output
Name Age City Occupation
0 Mike 30 New York Machine Learning Enginner
1 John 26 Shanghai Data Scientist
2 Clara 20 London Doctor
3 Sara 22 Paris Teacher
join方法依次来进行合并。由于篇幅有限,小编在这里也就简单地提及一下,后面再专门写篇文章来详细说明。时序问题的处理
在时序问题的处理上,小编之前专门写过一篇文章,具体可以看
例如我们有这么一个数据集
df = pd.read_csv("air_quality.csv")
df = df.rename(columns={"date.utc": "datetime"})
df.head()
output
city country datetime location parameter value
0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0
1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8
2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5
3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9
4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4
我们看一下目前“datetime”这一列的数据类型
df.dtypes
output
city object
country object
datetime object
location object
parameter object
value float64
dtype: object
pandas当中的to_datetime方法将“datetime”这一列转换成“datetime”的格式df["datetime"] = pd.to_datetime(df["datetime"])
df["datetime"].head()
output
0 2019-06-21 00:00:00+00:00
1 2019-06-20 23:00:00+00:00
2 2019-06-20 22:00:00+00:00
3 2019-06-20 21:00:00+00:00
4 2019-06-20 20:00:00+00:00
Name: datetime, dtype: datetime64[ns, UTC]
我们便可以查看起始的日期
df["datetime"].min(), df["datetime"].max()
output
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
中间相隔的时间
df["datetime"].max() - df["datetime"].min()
output
Timedelta('44 days 23:00:00')
文本数据的处理问题
当我们的数据集中存在文本数据时,pandas内部也有相对应的处理方法
data = {"Full Name": ["Peter Parker", "Linda Elisabeth", "Bob Dylan"],
"Age": [40, 50, 60]}
df = pd.DataFrame(data)
df
output
Full Name Age
0 Peter Parker 40
1 Linda Elisabeth 50
2 Bob Dylan 60
可以用str方法将这些文本数据摘取出来,然后再进一步操作
df["Full Name"].str.lower()
output
0 peter parker
1 linda elisabeth
2 bob dylan
Name: Full Name, dtype: object
或者也可以这样来操作
df["Last Name"] = df["Full Name"].str.split(" ").str.get(-1)
df
output
Full Name Age Last Name
0 Peter Parker 40 Parker
1 Linda Elisabeth 50 Elisabeth
2 Bob Dylan 60 Dylan
这样我们可以将其“姓”的部分给提取出来,同样的我们也可以提取“名”的部分
df["First Name"] = df["Full Name"].str.split(" ").str.get(0)
df
output
Full Name Age Last Name First Name
0 Peter Parker 40 Parker Peter
1 Linda Elisabeth 50 Elisabeth Linda
2 Bob Dylan 60 Dylan Bob
我们也可以通过contains方法来查看字段中是不是包含了某一个字符串
df["Full Name"].str.contains("Bob")
output
0 False
1 False
2 True
Name: Full Name, dtype: bool
同样也是通过str方法将文本数据也提取出来再进行进一步的操作
分享、收藏、点赞、在看安排一下?
